¶ Проблема оракула и недетерминизм
Традиционное программное обеспечение строится на явной логике: программист пишет код, который реализует алгоритм . Если подаем на вход , мы ожидаем строго определенный . Ошибка здесь — это отклонение от спецификации. В AI/ML-системах логика не кодируется явно, а выводится из данных. Программа формируется в процессе обучения и ее поведение стохастично.
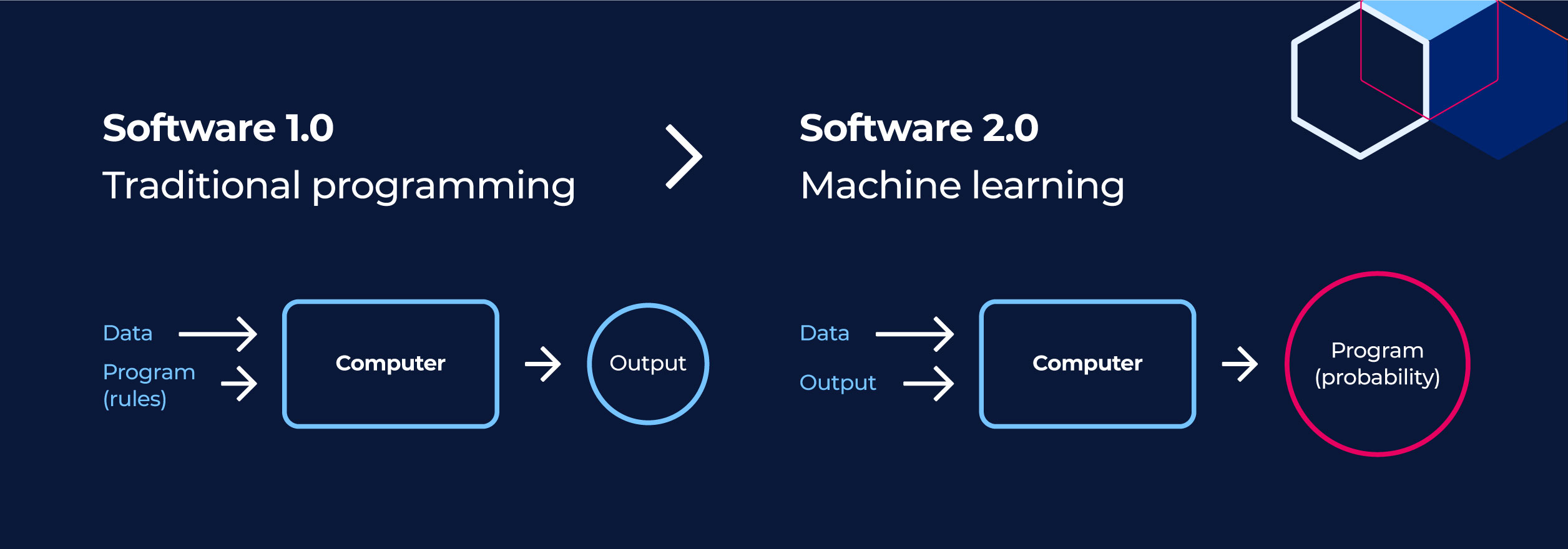
Это порождает так называемую проблему оракула (Oracle Problem) — отсутствие механизма, который мог бы для любого произвольного входа однозначно сказать, является ли выход правильным без привлечения человека-эксперта
В классическом тестировании ( unit-тесты) мы используем утверждения (assertions): assert add(2, 2) == 4. В ML это невозможно для всех случаев.
Рассмотрим систему классификации изображений. Если модель с уверенностью 85% утверждает, что на размытом фото изображена кошка — является ли это ошибкой, если человек-эксперт также сомневается? В генеративных моделях проблема круче: как определить, является ли сгенерированное резюме текста правильным? Нет бинарной истины, есть степень соответствия.
Из этого следует необходимость применения метаморфического тестирования (Metamorphic Testing). Вместо проверки точного соответствия выхода проверяем сохранение свойств (инвариантов) при трансформации входа.
assert model.predict(image) == model.predict(rotate(image, 5))
Если модель распознает автомобиль на фото, то при повороте изображения на 5 градусов или добавлении небольшого шума она все равно должна распознать автомобиль. Если предсказание меняется, то мы фиксируем дефект устойчивости, даже не зная истинной метки.
В классическом ПО исправление бага в функции авторизации обычно не ломает функцию поиска. В ML-системах действует принцип CACE (Changing Anything Changes Everything). Попытка переобучить модель для лучшего распознавания дорожных знаков в ночное время может привести к деградации точности в дневное время. Это накладывает определенные требования на регрессионное тестирование: любой новый релиз модели требует полного прогона всех метрик на валидационном наборе данных, а не только проверки исправленного кейса.
А вообще говоря:

Рассмотрим отсутствие детерминизма с двух точек зрения.
Обучение
При фиксированном коде и данных повторный запуск может дать иную модель из-за случайной инициализации весов, стохастического градиентного спуска (SGD) или порядка подачи батчей
Инференс
Результат работы модели — распределение вероятностей ([0.8 "кот", 0.2 "собака"]). QA-инженер должен оценивать качество этого распределения, а не бинарную корректность вывода.
Для систематизации процесса тестирования необходимо понимать природу дефектов. Ошибки в ML распределяются по трем слоям:
- ошибки данных: пропуски, шум, дрейф, смещение выборки
- ошибки модели: переобучение, недообучение, низкая обобщающая способность, катастрофическое забывание
- ошибки инфраструктуры: некорректная предобработка признаков, проблемы с сериализацией моделей
| Характеристика | Классическое ПО (Software 1.0) | AI/ML-системы (Software 2.0) |
|---|---|---|
| Логика работы | Явные правила, написанные человеком | Скрытые паттерны, извлеченные из данных |
| Природа ошибок | Логические ошибки, null pointers, исключения | Статистические отклонения, низкая точность, дрейф |
| Тестовый оракул | Четкая спецификация | Отсутствует или псевдо-оракул |
| Фокус QA | Верификация функциональных требований | Валидация данных, метрик качества и устойчивости |
¶ Метрики качества и пороги
В контексте QA метрика — это индикатор бизнес-риска. Ключевая задача тестировщика — выбрать метрику, соответствующую цене ошибки.
Матрица ошибок (матрица путаницы) позволяет декомпозировать работу модели на четыре исхода:
True Positive (TP): модель верно предсказала целевой класс (система безопасности верно опознала хакера).
True Negative (TN): модель верно отвергла нецелевой класс (система пропустила легитимного пользователя)
False Positive (FP / Ошибка I рода): ложная тревога, модель увидела хакера в легитимном пользователе
False Negative (FN / Ошибка II рода): пропуск цели. модель пропустила хакера
Напоминаю, что для понимания удобно воспринимать термины
PositiveиNegativeкак обозначения для целевого и нецелевого класса соответственно
Если в выборке 99% легитимных транзакций и 1% мошеннических, то модель, всегда говорящая ОК (транзакция легитимна), имеет
Accuracy99%. Матрица ошибок вскроет проблему (TP=0)
Precision (Точность)
QA-смысл: насколько мы можем доверять срабатыванию модели?
Кейс: спам-фильтр, если Precision низкий, то важные письма будут улетать в спам (много FP); это напрягает.
Recall (Полнота)
QA-смысл: какую долю искомых объектов нашли?
Кейс: медицинская диагностика (онкология), если Recall низкий, то мы пропускаем больных пациентов (много FN), что может стоить жизни; здесь Recall важнее Precision.
F1-Score (гармоническое среднее)
Гармоническое среднее наказывает за экстремально низкие значения одного из компонентов
Если Recall = 1.0 (нашли всех больных), но Precision = 0.01 (отметили всех подряд), среднее арифметическое даст около 0.5, что выглядит RESPECT. F1-Score даст куда меньше, честно отражая непригодность такой модели.
Модели ML выдают вероятность: . Превращение этого числа в класс (0 или 1) происходит по порогу (threshold), обычно 0.5.
QA-инженер должен участвовать в выборе порога
Сдвиг порога вверх (0.8) -> меньше FP, выше Precision, но ниже Recall. Сдвиг порога вниз (0.2) -> меньше FN, выше Recall, но ниже Precision.
Для формализации процесса используется Матрица стоимости (Cost Matrix). Если стоимость пропуска мошенничества () равна 1000, а стоимость проверки ложной тревоги () равна 10, мы можем математически найти оптимальный порог, минимизирующий общие убытки.
import numpy as np
from sklearn.metrics import confusion_matrix
np.random.seed(42)
n_samples = 1000
y_true = np.random.randint(0, 2, size=n_samples)
y_prob = np.random.rand(n_samples)
# улучшаем предсказания для демонстрации
y_prob = [p + 0.4 if y == 1 else p - 0.2 for p, y in zip(y_prob, y_true)]
y_prob = np.clip(y_prob, 0, 1)
COST_FP = 10
COST_FN = 1000
def calculate_total_cost(y_true, y_prob, threshold):
y_pred = [1 if p >= threshold else 0 for p in y_prob]
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
total_cost = (fp * COST_FP) + (fn * COST_FN)
return total_cost, fp, fn
thresholds = np.arange(0.0, 1.01, 0.01)
costs = []
best_threshold = 0.5
min_cost = float('inf')
for t in thresholds:
cost, fp, fn = calculate_total_cost(y_true, y_prob, t)
costs.append(cost)
if cost < min_cost:
min_cost = cost
best_threshold = t
# стандартный подход
def_cost, def_fp, def_fn = calculate_total_cost(y_true, y_prob, 0.5)
# оптимальный подход
opt_cost, opt_fp, opt_fn = calculate_total_cost(y_true, y_prob, best_threshold)
# далее сравнить можно
Тестирование моделей обучения без учителя (кластеризация клиентов) сложнее, поскольку нет правильных ответов. Значит не можем посчитать Accuracy. Вместо этого обычно используем метрики внутренней валидности, которые оценивают геометрические свойства полученных кластеров.
Коэффициент Силуэта (Silhouette Score)
Метрика оценивает, насколько объект похож на свой кластер по сравнению с другими кластерами. Диапазон от -1 до +1.
Есть точка , принадлежащая кластеру .
Среднее внутрикластерное расстояние:
Здесь — расстояние между точками. Чем меньше , тем плотнее сгруппирован кластер.
Среднее расстояние до ближайшего соседнего кластера:
Итог:
Если (до чужих далеко, свои близко), значит дробь стремится к . Если (граница кластеров), то числитель стремится к . Если (точка ближе к чужому кластеру, чем к своему), то результат отрицательный.
¶ Регрессионное тестирование и MLOps
Регрессионное тестирование (Regression Testing) — вид тестирования, направленный на проверку того, что новые изменения в коде (исправление багов, добавление фич, рефакторинг) не сломали уже существующую и работающую функциональность.
MLOps (Machine Learning Operations) — набор практик, инструментов и подходов, направленных на автоматизацию и стандартизацию процесса разработки, развертывания и мониторинга систем машинного обучения.
Почему все плохо без MLOps:
- дата-сатанист обучает модель в Jupyter Notebook на своем ноутбуке; у него все работает; он кидает файл модели разработчикам
- бэкендеры пытаются встроить файл в сервис; версии библиотек не совпадают, модель потребляет слишком много памяти, на реальных данных она ведет себя иначе
- QA не понимает, как это тестировать
В AI/ML системах объектом тестирования является не только финальный артефакт (файл весов .pkl или .h5), но и весь конвейер (pipeline), который его производит (Hidden Technical Debt in Machine Learning Systems)
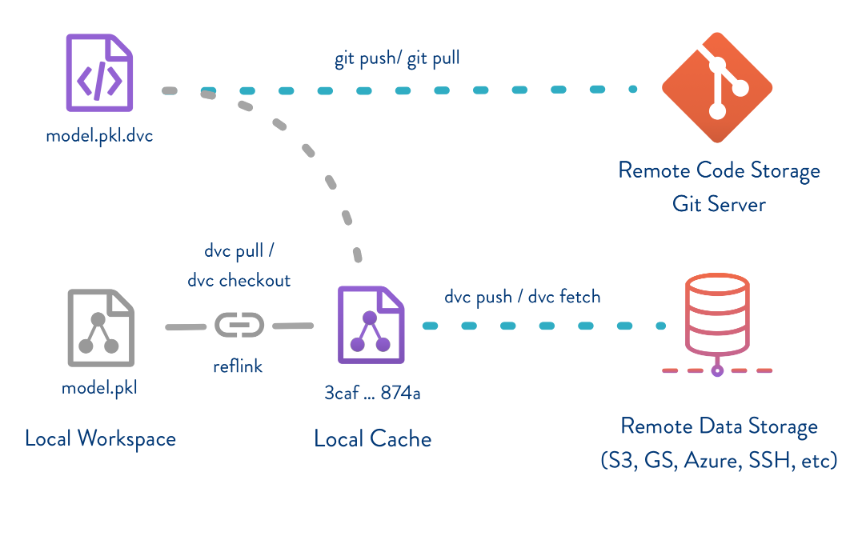
Git не подходит для ML-проектов. Если откатили код на неделю назад, но данные остались новыми — не воспроизведем результат.
Для обеспечения воспроизводимости проверок необходимо версионировать три компонента одновременно:
- код (Git)
- данные (DVC)
- окружение и параметры (MLflow)
DVC (Data Version Control ) — система контроля версий для машинного обучения. Она работает поверх Git.
pip install dvc dvc-s3
dvc init
dvc remote add -d remote s3://pmifi-bucket/ml-models
git add .
git commit -m "chore: init dvc"
Автоматически подхватываются значения переменных окружения AWS_ACCESS_KEY_ID и AWS_SECRET_ACCESS_KEY. Так добавляются данные в DVC
dvc add data/raw.csv
Создался файл data/raw.csv.dvc. Оригинал добавлен в .gitignore.
git add data/raw.csv.dvc .gitignore
git commit -m "chore: add dataset"
git push
dvc push
git checkout feature/ml
git pull
dvc pull
Конвейеры (dvc.yaml):
stages:
prepare:
cmd: python src/prepare.py data/raw.csv
deps:
- data/raw.csv
- src/prepare.py
params:
- prepare.split_ratio
- prepare.seed
outs:
- data/train.csv
- data/test.csv
train:
cmd: python src/train.py data/train.csv model.pkl
deps:
- data/train.csv
- src/train.py
params:
- train.epochs
- train.learning_rate
- train.model_type
outs:
- model.pkl
- run_id.txt
evaluate:
cmd: python src/evaluate.py model.pkl data/test.csv
deps:
- model.pkl
- run_id.txt
- data/test.csv
- src/evaluate.py
metrics:
- metrics.json:
cache: false
plots:
- plots/confusion_matrix.json:
cache: false
Файл с параметрами (params.yaml):
prepare:
split_ratio: 0.8
seed: 42
train:
epochs: 100
learning_rate: 0.001
model_type: "mlp"
Запуск конвейера командой dvc repro.
Здесь если
data/raw.csvне менялся, этапprepareне будет перезапускаться. Это экономит время.
В классическом ПО регрессия — когда сломалась кнопка. В ML регрессия — это когда метрики просели
dvc metrics diff main
Path Metric Old New Change
metrics.json accuracy 0.852 0.884 +0.032
metrics.json f1_score 0.810 0.805 -0.005
metrics.json loss 0.450 0.410 -0.040
Это объективное доказательство улучшения или ухудшения качества модели
Можно визуально сравнить графики (генерируется HTML-отчет):
dvc plots diff main
Любой участник команды может клонировать репозиторий, выполнить
dvc reproи гарантированно получить тот же результат, что и автор кода
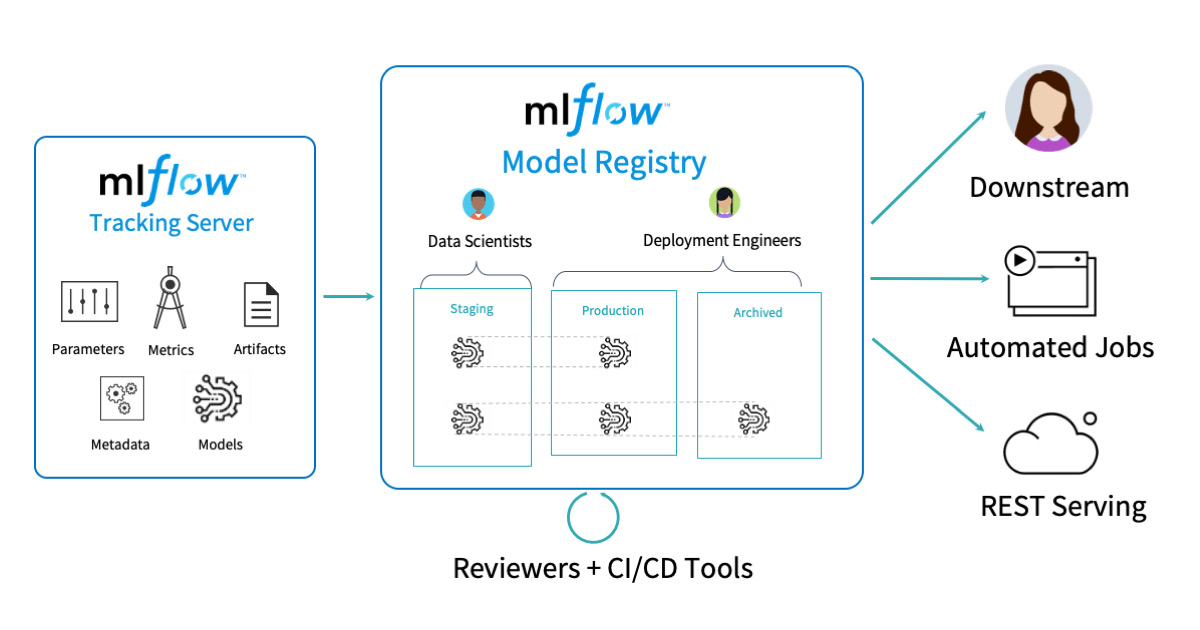
Можно добавить к этому MLFlow (платформу для управления жизненным циклом машинного обучения)
services:
db:
image: postgres:15
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: mlflow_db
volumes:
- ./pgdata:/var/lib/postgresql/data
minio:
image: minio/minio
command: server /data --console-address ":9001"
environment:
MINIO_ROOT_USER: minio_user
MINIO_ROOT_PASSWORD: minio_password
ports:
- "9000:9000"
- "9001:9001"
volumes:
- ./minio_data:/data
mlflow:
image: ghcr.io/mlflow/mlflow:latest
depends_on:
- db
- minio
ports:
- "5000:5000"
environment:
MLFLOW_BACKEND_STORE_URI: postgresql://user:password@db:5432/mlflow_db
MLFLOW_S3_ENDPOINT_URL: http://minio:9000
AWS_ACCESS_KEY_ID: minio_user
AWS_SECRET_ACCESS_KEY: minio_password
command: >
mlflow server
--backend-store-uri postgresql://user:password@db:5432/mlflow_db
--host 0.0.0.0
--default-artifact-root s3://mlflow-bucket
import sys
import yaml
import pandas as pd
import pickle
import mlflow
from sklearn.neural_network import MLPClassifier
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("DVC_Pipeline")
def train():
input_csv = sys.argv[1]
output_model = sys.argv[2]
with open("params.yaml", "r") as f:
params = yaml.safe_load(f)["train"]
with mlflow.start_run() as run:
run_id = run.info.run_id
with open("run_id.txt", "w") as f:
f.write(run_id)
mlflow.log_param("epochs", params["epochs"])
mlflow.log_param("learning_rate", params["learning_rate"])
mlflow.log_param("model_type", params["model_type"])
df = pd.read_csv(input_csv)
X, y = df.iloc[:, :-1], df.iloc[:, -1]
model = MLPClassifier(
max_iter=params["epochs"],
learning_rate_init=params["learning_rate"]
)
model.fit(X, y)
with open(output_model, "wb") as f:
pickle.dump(model, f)
mlflow.sklearn.log_model(model, "model", registered_model_name="ProductionModel")
if __name__ == "__main__":
train()
import sys
import json
import pickle
import pandas as pd
import mlflow
from sklearn.metrics import accuracy_score, f1_score
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("DVC_Pipeline")
def evaluate():
model_path = sys.argv[1]
data_path = sys.argv[2]
try:
with open("run_id.txt", "r") as f:
run_id = f.read().strip()
except FileNotFoundError:
print("run_id.txt не найден")
return
with open(model_path, "rb") as f:
model = pickle.load(f)
df = pd.read_csv(data_path)
X, y = df.iloc[:, :-1], df.iloc[:, -1]
predictions = model.predict(X)
acc = accuracy_score(y, predictions)
f1 = f1_score(y, predictions, average="macro")
metrics = {"accuracy": acc, "f1_score": f1}
with open("metrics.json", "w") as f:
json.dump(metrics, f)
with mlflow.start_run(run_id=run_id):
mlflow.log_metric("accuracy", acc)
mlflow.log_metric("f1_score", f1)
if __name__ == "__main__":
evaluate()
Можно использовать MLFlow чтобы смотреть всю аналитику по части ML и для загрузки готовых моделей
![]()
¶ Верификация при развертывании
Даже если dvc metrics diff показывает улучшение точности на 5%, это не значит, что модель готова. В реальности данные могут отличаться (вспоминаем Data Drift), или модель может работать долго.
Shadow Mode
Новая модель (Candidate) разворачивается параллельно с текущей (Champion). 100% входящего трафика дублируется и отправляется на обе модели. Пользователь получает ответ только от старой модели (Champion). Ответ новой модели логируется, но не показывается.
Необходимо сравнить распределения ответов. Если старая модель предсказывает мошенничество в 1% случаев, а новая в 15%, то это индикатор аномалии, который нужно изучить.
A/B-тестирование
Когда техническая стабильность подтверждена в Shadow Mode, проверяем бизнес-эффективность.
Трафик делится между моделями:
- группа А (control): 95% пользователей видят работу старой модели
- группа B (treatment): 5% пользователей видят работу новой модели
Измеряем бизнес-метрики:
- стали ли чаще покупать?
- стали ли чаще кликать?
- вырос ли средний чек?
Один и тот же пользователь должен всегда попадать в одну и ту же группу
DVC -> Pull Request -> CI -> Shadow Mode (неделя) -> A/B Test (на 5% пользователей) -> раскатка модели на 100% пользователей.