¶ Пирамида тестирования
В программной инженерии стратегия автоматизированного тестирования является не просто набором практик, а фундаментальным элементом, определяющим скорость разработки, стоимость владения продуктом и степень уверенности в его качестве.
Центральной концепцией, описывающей сбалансированный подход к автоматизации, является Пирамида Тестирования. Модель, представленная Mike Cohn в его книге «Succeeding With Agile», представляет собой метафору, которая визуализирует оптимальное распределение тестовых артефактов по различным уровням системы.
Основная идея пирамиды заключается в том, чтобы структурировать тесты по уровням детализации, скорости выполнения и стоимости поддержки, формируя таким образом эффективную и устойчивую базу тестирования
¶ Структура
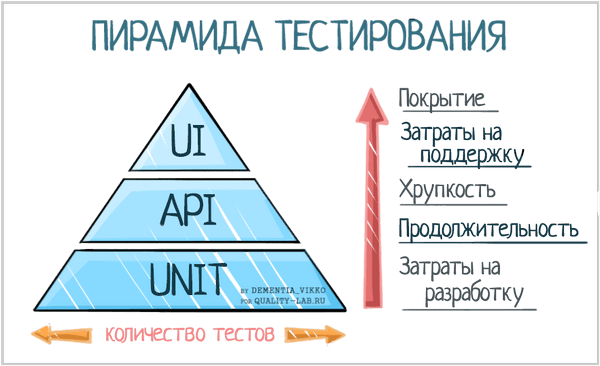
Оригинальная модель, предложенная Mike Cohn и развитая Martin Fowler, состоит из трех основных слоев.
¶ Unit Tests (Модульные / Компонентные тесты)
Самый широкий и фундаментальный слой пирамиды. Юнит-тесты проверяют наименьшие атомарные части системы в изоляции — отдельные функции, методы или классы. Их должно быть подавляющее большинство.
Ключевые характеристики этого уровня:
- чрезвычайно высокая скорость выполнения (тысячи тестов за секунды)
- низкая стоимость написания и поддержки
- высокая степень изоляции от внешних зависимостей (базы данных, файловая система, сетевые сервисы)
¶ Service / Integration Tests (Сервисные / Интеграционные тесты)
Предназначены для проверки взаимодействия между несколькими компонентами системы или корректности интеграции с внешними сервисами, такими как базы данных, брокеры сообщений или сторонние API.
Martin Fowler ввел термин Subcutaneous Tests («подкожные тесты»): эти тесты работают ниже уровня пользовательского интерфейса (UI), напрямую взаимодействуя с сервисным слоем или API приложения
Медленнее и дороже юнит-тестов, но проверяют корректность совместной работы модулей, что не может быть верифицировано на уровне юнитов.
¶ UI / End-to-End (E2E) Tests (Тесты Пользовательского Интерфейса / Сквозные тесты)
Самый узкий слой, содержащий наименьшее количество тестов. E2E-тесты симулируют реальные пользовательские сценарии от начала и до конца, проходя через все слои приложения — от пользовательского интерфейса до базы данных.
Они дают наивысший уровень уверенности в том, что система работает корректно с точки зрения пользователя.
E2E-тесты являются самыми медленными, самыми дорогими в разработке и поддержке, и наиболее хрупкими (склонными к появлению ошибок из-за незначительных изменений в UI или окружении).
¶ Обоснование
Структура пирамиды обусловлена прагматическими причинами.
¶ Скорость обратной связи
В гибкой разработке и DevOps-культуре скорость является ключевым фактором. Юнит-тесты, выполняемые за миллисекунды, могут быть запущены при каждом сохранении файла, предоставляя почти мгновенную обратную связь. Интеграционные тесты занимают секунды или минуты и обычно запускаются при каждом коммите. Сквозные E2E-тесты, длящиеся десятки минут или даже часы, могут выполняться лишь несколько раз в день. Чем ниже тест в пирамиде, тем быстрее цикл «код-тест-рефакторинг».
¶ Стоимость исправления дефектов
Стоимость обнаружения и исправления дефектов растет экспоненциально по мере его продвижения по жизненному циклу разработки. Ошибка, найденная юнит-тестом на этапе написания кода, может быть в 10-100 раз дешевле в исправлении, чем та же ошибка, обнаруженная E2E-тестом перед релизом или пользователем в продакшене. Пирамида является стратегией минимизации затрат путем раннего обнаружения дефектов.
¶ Стабильность и локализация проблемы
Юнит-тесты являются наиболее стабильными. При падении E2E-теста причина может скрываться в любом из десятков взаимодействующих компонентов, что превращает отладку в сложный процесс. Падение юнит-теста с высокой точностью указывает на конкретный модуль и часто на конкретный метод, где произошла ошибка.
Martin Fowler подчеркивает:
«Если у вас падает высокоуровневый тест, это сигнализирует не только о наличии бага в функциональном коде, но и об отсутствующем или некорректном юнит-тесте. Прежде чем исправлять баг, воспроизведите его с помощью юнит-теста»
¶ Антипаттерн «Рожок мороженого» (Ice-Cream Cone)
Нарушение принципов пирамиды приводит к появлению антипаттерна, известного как «Рожок Мороженого» — перевернутой пирамиды, где основная масса тестов сосредоточена на уровне UI/E2E, а юнит-тестов практически нет.
Это часто возникает в проектах, которые полагаются на практики, где тестирование отделено от разработки.
Последствия такого подхода:
- долгие циклы сборки, замедляющие весь процесс разработки
- высокая стоимость поддержки базы тестирования, так как малейшие изменения в UI требуют переработки десятков тестов
- сложная и медленная отладка, так как тесты не локализуют проблему
Важно понимать, что пирамида — не догма, а эвристическая модель. Её конкретная форма и пропорции могут и должны адаптироваться под архитектуру и технологический стек проекта
¶ Testing Trophy (Тестовый Кубок)
Концепция, предложенная Kent C. Dodds, смещает фокус с юнит-тестов на интеграционные. Основанием «кубка» является статический анализ (линтеры, тайп-чекеры), затем идет небольшое количество юнит-тестов, самый широкий слой — интеграционные тесты, и на вершине — очень мало E2E-тестов.
Идея в том, что интеграционные тесты обеспечивают наилучший баланс между уверенностью в корректной работе системы и затратами на их создание и поддержку.

Эволюция от классической пирамиды к моделям вроде «Кубка» не является опровержением исходных принципов, а демонстрирует адаптацию к изменившимся технологическим реалиям.
Пирамида была сформулирована в эпоху, когда взаимодействие с базами данных, файловой системой или сетью в автоматических тестах было действительно медленным, сложным и дорогостоящим
Это делало строгую изоляцию (юнит-тесты) единственным способом обеспечить быструю обратную связь.
Появление таких технологий, как Docker, позволило поднимать легковесные, изолированные экземпляры баз данных (например, PostgreSQL в контейнере) за секунды. Когда стоимость интеграционного теста, проверяющего взаимодействие сервиса с реальной, хоть и контейнеризированной, БД, становится сопоставимой со стоимостью юнит-теста, который эту базу данных имитирует, его ценность резко возрастает.
Таким образом, движение в сторону интеграционных тестов — прямое следствие снижения их стоимости, что делает их более привлекательной инвестицией для достижения уверенности в качестве продукта.
Несмотря на появление новых моделей, юнит-тесты остаются фундаментом любой зрелой стратегии тестирования
Помимо ключевого преимущества (раннее обнаружение дефектов), у юнит-тестов есть и другие фишки.
¶ Поддержка рефакторинга и эволюции кода
Наличие всеобъемлющего набора юнит-тестов позволяет разработчикам смело проводить рефакторинг и оптимизировать код. Если изменение нарушает существующую функциональность, соответствующий юнит-тест немедленно сообщит об этом, предотвращая регрессии. Без юнит-тестов любые изменения становятся слишком рискованными.
¶ Документация
В отличие от внешней документации или комментариев к коду, которые неизбежно устаревают, юнит-тесты всегда актуальны. Они являются точным и исполняемым примером того, как следует использовать API компонента. Изучая тесты, новый разработчик может быстро понять, какие входные данные ожидает функция, какие результаты она возвращает, и как она обрабатывает граничные и ошибочные ситуации.
¶ Улучшение архитектуры:
Процесс написания юнит-тестов заставляет разработчика думать о дизайне кода с точки зрения его тестируемости. Код, который сложно протестировать, как правило, является плохо спроектированным кодом: он может иметь слишком много зависимостей, нарушать принцип единственной ответственности (Single Responsibility Principle, SRP) или иметь скрытые побочные эффекты.
¶ Анатомия юнит-теста
¶ Определение юнита
Фундаментальный вопрос «Что именно является юнитом?» не имеет единого ответа
Сформировалось два основных подхода, которые предлагают разные подходы к определению границ юнита и принципов изоляции.
Классический подход (Kent Beck, Martin Fowler) соответствует подходу к разработке «изнутри наружу» (inside-out). Разработчик начинает с реализации ключевой доменной логики, дизайн системы вырисовывается в процессе написания кода и рефакторинга, направляемого тестами, проверяющими конечное поведение.
Сначала пишем связанные сервисы, приступаем к написанию контроллеров только когда взаимосвязанные сервисы протестированы
Лондонский подход продвигает подход «снаружи внутрь» (outside-in). Разработка начинается с внешних слоев системы. Его зависимости сразу же заменяются моками. Это заставляет разработчика целенаправленно проектировать интерфейсы и контракты взаимодействия между компонентами до того, как будет написана их реализация.
Начали писать контроллер - мокаем сервисы в тестах
| Критерий | Классический подход | Лондонский подход |
|---|---|---|
| Философия | Тестирование поведения (Behavioral Testing) | Тестирование взаимодействий (Interaction Testing) |
| Определение юнита | Единица поведения (может включать несколько классов) | Один класс |
| Подход к изоляции | Изоляция тестов друг от друга | Изоляция тестируемого класса от всех зависимостей |
| Использование зависимостей | Используются реальные объекты-коллабораторы | Все зависимости заменяются моками |
| Стиль тестов | "Социальные" (Sociable) | "Одиночные" (Solitary) |
| Метод верификации | Проверка конечного состояния (State Verification) | Проверка вызовов методов (Interaction Verification) |
| Сильная сторона | Устойчивость к рефакторингу реализации | Точная локализация ошибки; способствует дизайну через интерфейсы |
| Слабая сторона | Сложнее определить точную причину сбоя | Хрупкость тестов (тесная связь с реализацией) |
¶ Принципы F.I.R.S.T.
Служат стандартом для оценки и написания эффективных тестов
¶ Fast (Быстрые)
Юнит-тесты должны выполняться чрезвычайно быстро, за миллисекунды. Весь набор из тысяч юнит-тестов должен завершаться за несколько секунд. Если тесты медленные, разработчики перестанут запускать их регулярно, что сведет на нет их основное преимущество — мгновенную обратную связь.
¶ Isolated / Independent (Изолированные / Независимые)
Тесты не должны зависеть друг от друга. Результат одного теста не должен влиять на результат другого, а порядок их запуска не должен иметь значения. Каждый тест обязан самостоятельно подготавливать все необходимые данные и условия (контекст) и не оставлять после себя артефактов, которые могут повлиять на выполнение последующих тестов.
¶ Repeatable (Повторяемые)
Тест должен стабильно давать один и тот же результат при каждом запуске в любом окружении — на локальной машине разработчика, на сервере непрерывной интеграции. Зависимость от текущей даты/времени, случайных чисел, сетевых вызовов или состояния файловой системы, должны быть устранены или контролируемы.
¶ Self-Validating (Самопроверяемые)
Тест должен иметь четкий и однозначный результат: либо «пройден» (pass), либо «провален» (fail). Он не должен требовать от человека ручной интерпретации логов, сравнения файлов или просмотра вывода в консоли для определения статуса. Эту задачу выполняют утверждения (assertions) тестового фреймворка.
¶ Timely/Thorough (Своевременные/Тщательные)
Во-первых, тесты должны быть своевременными, то есть написанными в непосредственной близости к коду, который они проверяют. В идеале непосредственно перед его написанием (Test-Driven Development, TDD). Во-вторых, тесты должны быть тщательными. Это означает, что они должны проверять пограничные случаи, некорректные входные данные и сценарии обработки ошибок.
¶ Характеристики хорошего теста
¶ Структура Arrange-Act-Assert (AAA)
Канонический паттерн для структурирования тела теста.
Arrange (Подготовка): инициализируются объекты, подготавливаются тестовые данные и настраиваются тестовые двойники; создается весь необходимый контекст для теста
Act (Действие): вызывается тестируемый метод (блок содержит один вызов)
Assert (Проверка): результат, полученный на шаге Act, сравнивается с ожидаемым результатом; здесь находятся все утверждения (assertions)
¶ Информативное имя
Имя теста должно быть самодокументируемым.
CalculateDiscount_ForVIPClient_ReturnsTwentyPercent гораздо информативнее, чем Test1 или TestDiscount.
¶ Один логический Assert на тест
Тест должен проверять один конкретный аспект поведения или один сценарий. Это не означает, что в тесте может быть только один вызов функции assert. При проверке создания объекта User можно проверить user.name, и user.email в одном тесте, так как это относится к одному логическому исходу — корректному созданию объекта. При этом смешивать в одном тесте проверку успешного создания и проверку обработки ошибки является плохой практикой.
¶ Тестирование публичного API
Юнит-тесты должны проверять публичный контракт класса, то есть его публичные методы и свойства, а не детали внутренней реализации (приватные методы и поля)
Пример хорошего теста на Python:
# calculator.py
class Calculator:
def add(self, a, b):
if not isinstance(a, (int, float)) or not isinstance(b, (int, float)):
raise TypeError("Оба аргумента должны быть числиками")
return a + b
# test_calculator.py
import pytest
from calculator import Calculator
def test_add_two_positive_integers_returns_correct_sum():
# Arrange
calc = Calculator()
expected_result = 10
# Act
actual_result = calc.add(3, 7)
# Assert
assert actual_result == expected_result
def test_add_raises_type_error_for_non_numeric_input():
# Arrange
calc = Calculator()
# Act & Assert
with pytest.raises(TypeError) as excinfo:
calc.add("3", 7)
assert "Оба аргумента должны быть числиками" in str(excinfo.value)
¶ Антипаттерны юнит-тестов
¶ The Giant (Гигант)
Один тестовый метод, который проверяет сразу несколько различных сценариев, содержит сложную логику (циклы, условия) и занимает сотни строк. Такие тесты трудно читать, поддерживать, а при падении невозможно быстро понять, какой именно сценарий провалился
¶ The Inspector (Инспектор)
Тест, который нарушает инкапсуляцию и имеет доступ к приватным полям и методам тестируемого класса. Такие тесты тесно связаны с деталями реализации.
¶ The Liar (Лжец)
Тест, который всегда проходит, независимо от состояния кода. Это может быть тест без утверждений (assert) или тест, который проглатывает исключения.
¶ The Nitpicker (Придира)
Тест, который сравнивает большие, сложные объекты целиком (assert a == b), когда для проверки важны только одно-два поля. Любое изменение в нерелевантных полях объекта приведет к падению теста.
¶ The Environmental Vandal (Вандал окружения)
Тест, который зависит от специфической конфигурации окружения (абсолютные пути к файлам, переменные окружения, определенная версия ОС) и не является переносимым.
¶ Conjoined Twins (Сиамские близнецы)
Тест, который называется юнит-тестом, но на самом деле является интеграционным, так как напрямую работает с базой данных, файловой системой или сетью без использования тестовых двойников. Такие тесты медленные, нестабильные и нарушают принцип изоляции.
¶ Покрытие кода
¶ Метрики покрытия
Наличие тестов — необходимое, но не достаточное условие качества. Важно понимать, насколько полно тестовый набор проверяет кодовую базу.
Для количественной оценки этого аспекта используется метрика покрытия кода (code coverage).
Покрытие кода — метрика тестирования по принципу «белого ящика», которая измеряет, какая часть исходного кода была выполнена во время прогона автоматизированных тестов. Она выражается в процентах и рассчитывается по общей формуле:
где Items — измеряемые элементы кода (операторы, ветви, условия и т.д.). Существует иерархия метрик покрытия, каждая из которых обладает разной степенью строгости.
¶ Statement Coverage (Покрытие операторов)
Самая базовая метрика. Показывает, какой процент исполняемых операторов (строк кода) был выполнен хотя бы один раз.
Слабость: метрика полностью игнорирует логические ветвления. Для кода if (a && b) {... } один тест с a=true и b=true обеспечит 100% покрытие операторов, но при этом останутся абсолютно непроверенными все сценарии, когда условие ложно.
¶ Branch/Decision Coverage (Покрытие ветвлений/решений)
Более строгая метрика. Требует, чтобы каждое возможное решение (ветвь) в управляющих структурах (таких как if-else, switch, циклы) было выполнено хотя бы раз. Это означает, что для каждого if должны быть выполнены и true, и false ветви.
100% покрытие ветвлений гарантирует 100% покрытие операторов, но не наоборот
¶ Condition Coverage (Покрытие условий)
Метрика фокусируется на атомарных булевых подвыражениях внутри сложных условий. Она требует, чтобы каждое такое подвыражение было оценено и как true, и как false. Для условия if (a && b), необходимо как минимум два теста: один, где a — false, и другой, где b — false (например, (a=true, b=false) и (a=false, b=true)).
Слабость: 100% покрытие условий не гарантирует 100% покрытие ветвлений. В примере с if (a && b) тесты (a=true, b=false) и (a=false, b=true) обеспечат полное покрытие условий, но при этом тело оператора if (ветвь true) никогда не будет выполнено.
¶ Path Coverage (Покрытие путей)
Самая строгая и исчерпывающая метрика. Требует, чтобы каждый возможный логический путь выполнения через код был протестирован. Для последовательности из двух if-операторов это уже 4 пути. Из-за комбинаторного взрыва количества путей и наличия циклов (которые могут создавать бесконечное число путей) достижение 100% покрытия путей в нетривиальных программах практически невозможно.
Критически важно правильно интерпретировать данные о покрытии. Инструменты покрытия измеряют, какие строки кода были выполнены, но они ничего не говорят о качестве проверок, которые были сделаны во время этого выполнения.
Можно достичь 100% покрытия с набором тестов, в котором нет ни одного assert. Такой набор тестов докажет лишь то, что код не падает с ошибкой во время выполнения, но не то, что он производит корректные результаты
Покрытие кода является метрикой отсутствия тестов, а не присутствия качества
Вопрос, который следует задавать: не «Какой процент покрытия?», а «Что представляет собой непокрытый код и каков риск, связанный с его возможным отказом?»
¶ Анализ покрытия
Инструменты для анализа покрытия кода работают в два этапа:
Инструментация: исходный код или скомпилированный байт-код модифицируется для добавления специальных счетчиков, которые отслеживают выполнение каждого оператора, ветви и т. д.
Формирование отчёта: во время выполнения тестов счётчики собирают данные; после завершения тестов инструмент анализирует собранные данные и генерирует отчёт в различных форматах (консольный, HTML, XML)
Стандартный инструмент для измерения покрытия в Python — coverage.py, интегрируемый с фреймворком pytest
Istanbul является стандартом для измерения покрытия в экосистеме JavaScript (используется совместно с Jest и Mocha ); nyc — его CLI.
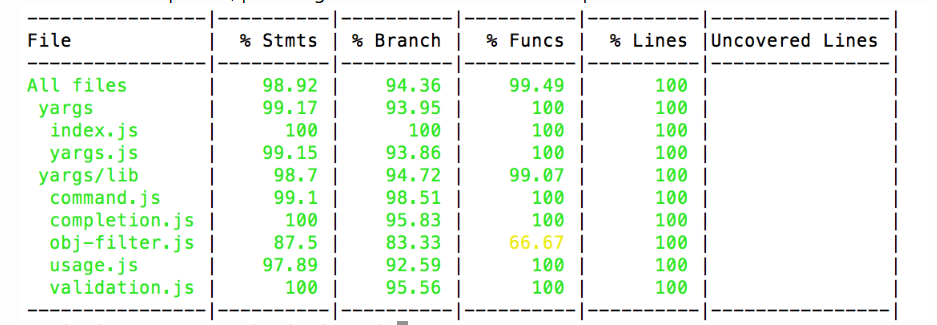
¶ Стратегии покрытия
¶ Дискуссия
¶ Аргументы «ЗА» 100% покрытие
Дисциплина и полнота: требование 100% покрытия заставляет разработчиков задумываться о тестировании всего нового кода, не оставляя «белых пятен» по недосмотру
Выявление «мертвого» кода: если в проекте, стремящемся к 100% покрытию, появляется непокрытый код, это сильный сигнал о том, что этот код, возможно, не используется и его можно безопасно удалить
Безопасность при рефакторинге: полное покрытие дает максимальную уверенность в том, что любые изменения, нарушающие существующую логику, будут немедленно обнаружены тестами
¶ Аргументы «ПРОТИВ» 100% покрытия
Закон убывающей доходности: усилия, необходимые для достижения последних нескольких процентов покрытия (например, с 95% до 100%), бывают огромными; а этот код, как правило, является либо тривиальным, либо чрезвычайно сложным для тестирования (специфичная для UI логика), и ценность таких тестов минимальна
Ложное чувство безопасности: 100% покрытие не гарантирует отсутствие багов; оно лишь подтверждает, что код был выполнен, а не то, что он был проверен на корректность
Стимул к написанию плохих тестов: когда 100% покрытие становится формальной целью, разработчики могут начать писать бесполезные тесты с тривиальными проверками
Зрелый подход заключается в использовании покрытия как инструмента, а не как самоцели
Для большинства проектов порог покрытия в 80-90% является хорошим ориентиром
Можно настроить CI-конвейер так, чтобы он блокировал слияние изменений, которые уменьшают текущий уровень покрытия. Это гарантирует, что новый код пишется с тестами.
¶ Риск-ориентированный подход
Следует концентрировать усилия по тестированию на тех областях системы, которые несут наибольший риск для бизнеса и пользователей
¶ Вероятность (Probability)
Высокая цикломатическая сложность: сложный код с большим количеством ветвлений и вложенных условий статистически содержит больше ошибок
Новизна или частота изменений: новый или часто изменяемый код более подвержен ошибкам, чем стабильный и устоявшийся
История дефектов: модули, в которых исторически находили много багов, являются кандидатами на более пристальное внимание
¶ Влияние (Impact)
Критичность для бизнеса: сбой в модуле обработки платежей имеет катастрофическое влияние, в то время как ошибка в верстке второстепенной страницы — не очень 
Модули с высоким риском должны иметь максимально возможное покрытие, проверенное с использованием строгой метрики (branch coverage)
Модули с низким риском могут иметь базовое покрытие