¶ Эволюция инженерных практик
¶ От QA к TestOps
Индустрия разработки ПО прошла длительный путь эволюции. Трансформировались подходы к обеспечению качества.
В эпоху каскадных моделей (Waterfall) тестирование существовало как изолированная фаза, наступающая после завершения разработки. Это приводило к тому, что разработчики не несли ответственности за работоспособность кода после передачи его тестировщикам.
С появлением Agile и DevOps барьеры между Development (Dev) и Operations (Ops) начали разрушаться. В то же время тестирование часто оставалось узким местом, не успевающим за скоростью релизных циклов.
TestOps (Testing Operations) — методология, направленная на оптимизацию операционной эффективности процесса тестирования. Если DevOps фокусируется на ускорении доставки кода в Production, то TestOps обеспечивает прозрачность, управляемость и надежность процессов валидации качества внутри этого потока
TestOps — это про управление тестовыми средами (чтобы они поднимались автоматически), тестовыми данными и инструментами отчетности
DevOps создает трубопровод для доставки кода, TestOps наполняет этот трубопровод интеллектуальными сенсорами контроля качества
| Характеристика | Традиционный QA | DevOps | TestOps |
|---|---|---|---|
| Основной фокус | Поиск дефектов | Скорость доставки и стабильность инфраструктуры | Операционная эффективность тестирования и качество данных |
| Место в жизренном цикле ПО | Изолированная фаза перед релизом | Весь жизненный цикл (Dev + Ops) | Интеграция в CI/CD пайплайн, непрерывное тестирование |
| Владение процессом | QA-отдел | Dev и Ops команды | Кросс-функциональное взаимодействие (Dev, QA, Ops) |
| Ключевые метрики | Количество багов, покрытие тестами | Lead Time, Deployment Frequency, MTTR | Pass/Fail rate, Flaky rate, время обратной связи, Test Reliability |
| Инструментарий | Ручные кейсы, локальная автоматизация | Jenkins, GitLab CI, Docker, K8s | Allure TestOps, ReportPortal, Sentry, Prometheus |
Вторым важным аспектом TestOps является изменение культуры владения качеством. В парадигме TestOps ответственность за тесты не лежит исключительно на QA-инженерах. Разработчики пишут модульные и интеграционные тесты, DevOps-инженеры обеспечивают инфраструктуру для их запуска, TestOps-инженеры создают инструменты для анализа результатов и управления этим процессом.

¶ Стратегии Shift Left и Shift Right
Современная стратегия обеспечения качества не может быть должна быть всеобъемлющей. Это реализуется через концепции сдвига влево (Shift Left) и сдвига вправо (Shift Right). Эти термины описывают перенос активностей по тестированию во времени относительно традиционной фазы QA.
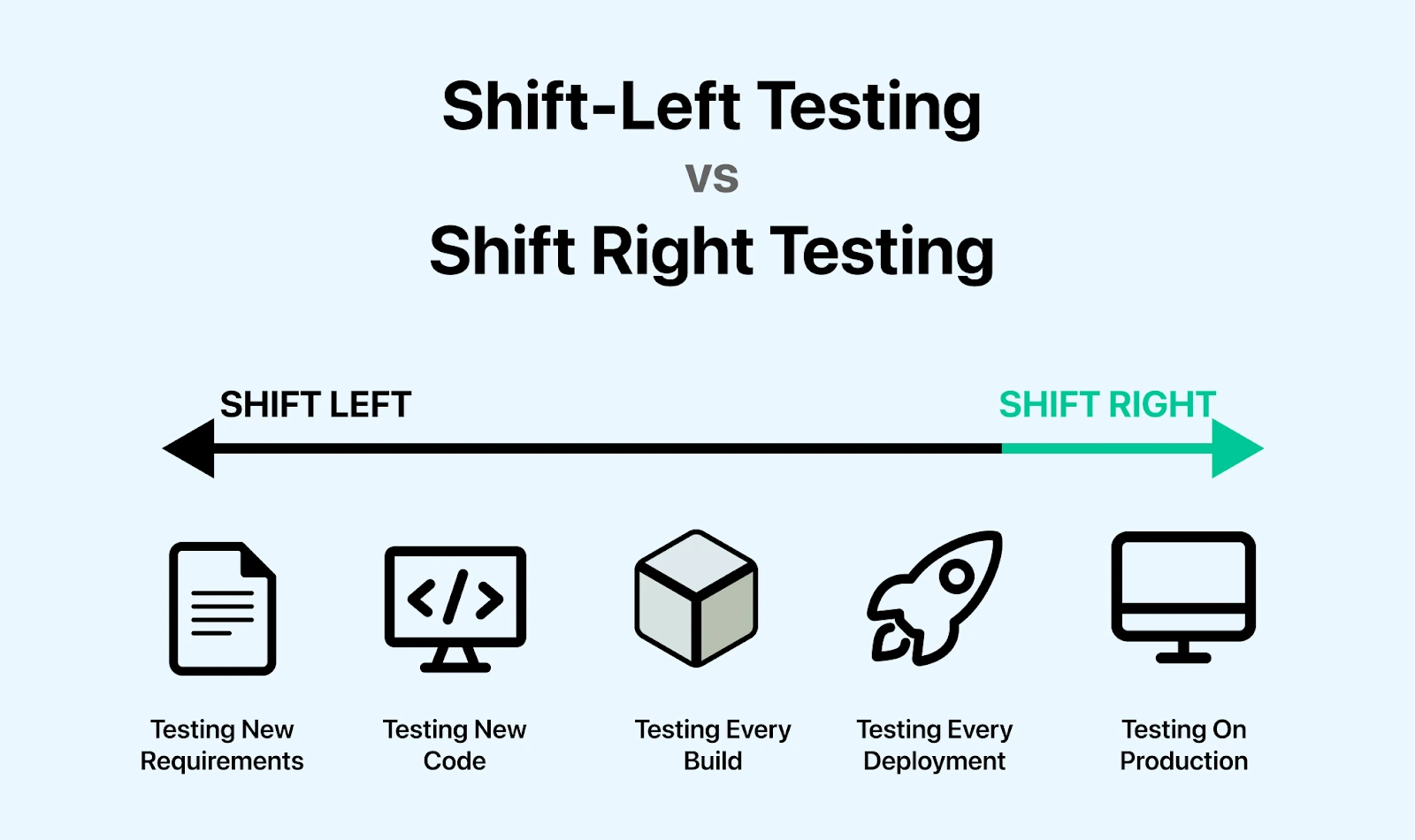
Shift Left (Превентивное качество)
Концепция Shift Left подразумевает перенос тестирования на самые ранние этапы разработки — непосредственно к моменту написания кода или даже проектирования.
Стоимость исправления ошибки растет экспоненциально по мере продвижения по стадиям жизненного цикла ПО. Баг, найденный на этапе требований, стоит 100 руб., на этапе unit-тестов — 1000 руб., а в Production — 10000 руб.
Инструменты: статический анализ кода (Linters, SAST), unit-тестирование, прекоммит-хуки (pre-commit hooks), сканирование зависимостей.
TestOps-аспект: автоматизация проверок в CI пайплайне на этапе Pull Request, блокировка слияния некачественного кода.
Shift Right (Тестирование в реальности)
Концепция Shift Right признает, что невозможно проверить все сценарии в искусственных условиях. Реальные пользователи и реальные данные создают ситуации, которые невозможно предугадать.
- Testing in Production (Feature Flags для скрытого запуска функционала)
- Canary Releases
- мониторинг пользовательского опыта (сбор данных о реальных задержках и ошибках в браузерах клиентов)
- Chaos Engineering (преднамеренное внесение сбоев для проверки устойчивости системы)
Данные, полученные справа, должны использоваться слева. Логи ошибок из Sentry с продакшена могут автоматически превращаться в новые тест-кейсы для регрессионного тестирования.
¶ Математические модели качества и производительности
¶ Закон Литтла
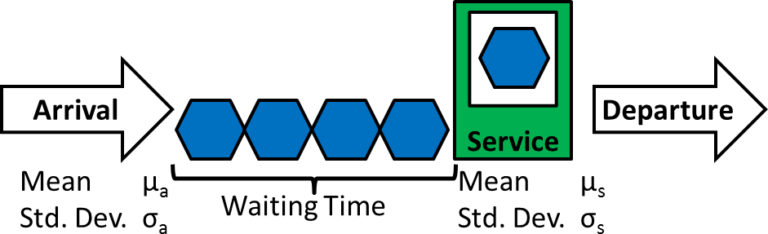
Инженерный подход к TestOps требует перехода от интуитивных ощущений (система работает медленно, тесты часто падают) к строгим математическим моделям. Для оптимизации CI/CD конвейеров и оценки достоверности результатов тестирования необходимо понимание основ теории массового обслуживания и статистики.
Любую систему CI/CD можно рассматривать как систему массового обслуживания (СМО). Заявки (Jobs/Builds) поступают в систему, встают в очередь и обрабатываются агентами (Runners). Фундаментальная теорема, описывающая поведение таких систем, известна как Закон Литтла (мы ее проходили, когда изучали нагрузочное тестирование).
Она устанавливает жесткую связь между тремя параметрами стационарной системы:
Где:
- (Work In Progress, WIP) — среднее количество задач в системе; в контексте CI/CD это количество активных веток, открытых Pull Requests (PR) или задач в очереди на сборку
- (Throughput) — средняя скорость поступления задач (интенсивность входящего потока); количество коммитов в час или количество запускаемых пайплайнов в день
- (Lead Time / Cycle Time) — среднее время пребывания задачи в системе; время с момента коммита до получения зеленой галочки или деплоя
Для разработчика самым критичным показателем является — время ожидания обратной связи. Если велико, то разработчик теряет контекст, переключается на другие задачи, и эффективность падает.
Согласно закону Литтла чтобы уменьшить есть два пути.
Уменьшить (WIP)
Ограничить количество одновременных задач. Это соответствует принципам Kanban (WIP limits). Если команда генерирует слишком много параллельных веток, то время ожидания сборки неизбежно вырастет, если пропускная способность системы константна.
Уменьшить
Увеличить пропускную способность, что достигается добавлением агентов CI, распараллеливанием тестов и оптимизацией времени их выполнения.
Если команда растет и частота коммитов увеличивается, а инфраструктура остается прежней, то количество задач в очереди будет расти, а следом за ним (по закону сохранения потока) вырастет и . Быстрый CI становится медленным при масштабировании команды.
¶ Влияние вариативности и утилизации
Закон Литтла описывает средние значения, но он не учитывает вариативность (случайные всплески нагрузки, задержки в тестах). Для более точного моделирования времени ожидания в очереди CI/CD используется аппроксимация Кингмана.
Где:
- — среднее время ожидания в очереди (перед тем как агент возьмет задачу)
- — коэффициент утилизации системы (загрузка ресурсов)
- , — скорость обслуживания, — коэффициент вариации интервалов поступления задач
- — коэффициент вариации времени обслуживания
- — среднее время обслуживания одной задачи
Фактор утилизации ()
При загрузке системы на 50% (), множитель равен . Очередь небольшая. При загрузке 80% (), множитель равен . Очередь растет. При загрузке 95% (), множитель равен . Время ожидания взлетает в 19 раз.
Нельзя загружать CI-агенты на 100% в целях экономии. Для обеспечения быстрого TestOps необходимо держать запас мощности, чтобы не превышало 70-80%
Фактор вариативности ()
Коэффициент вариации (стандартное отклонение / среднее).Если тесты стабильны и всегда идут ровно 5 минут, . Если в системе есть нестабильные тесты, которые иногда проходят за 1 минуту, а иногда висят до 30 минут, вариативность резко возрастает.
Высокая вариативность времени выполнения тестов линейно увеличивает время ожидания для всех задач в очереди, даже для стабильных сборок. Борьба с flaky-тестами важна не только для достоверности, но и для производительности всей очереди CI/CD.
¶ Биномиальное распределение и вероятность обнаружения дефектов
Проблема нестабильных тестов требует вероятностного подхода. Flaky-тест — случайная величина с распределением Бернулли. Пусть — вероятность того, что тест упадет при наличии дефекта или ложного срабатывания.
При использовании стратегии автоматического перезапуска упавших тестов мы пытаемся сгладить нестабильность инфраструктуры. Однако это создает риск пропуска реальных багов. Рассмотрим вероятность того, что тест пройдет успешно хотя бы один раз за попыток, при условии, что он имеет вероятность сбоя .
Эта вероятность описывается формулой:
Предположим, что есть тест, который падает в 10% случаев (). Это может быть как реальный плавающий баг (состояние гонки), так и проблема теста.
Без автоматических перезапусков (): вероятность прохождения . Мы заметим проблему в 10% случаев. С 3 перезапусками (): вероятность прохождения . В 99.9% случаев конвейер будет зеленым. Мы практически гарантированно скроем проблему, если она воспроизводится редко.

масштабируем это на уровень тестового набора из тестов. Вероятность того, что весь набор тестов пройдет успешно, равна произведению вероятностей успеха каждого теста (при условии их независимости):
Если у нас 500 тестов (), и каждый имеет небольшую нестабильность (, 1%), то при отсутствии автоматических перезапусков ():
Вероятность успешного прогона всего 0.6%.
Если добавим 3 перезапуска ():
Надежность повышается до 99.95%.
Математика показывает фундаментальный конфликт между стабильностью конвейера (которую перезапуски повышают) и чувствительностью к багам (которую перезапуски убивают)
Для определения необходимого размера выборки (количества прогонов) для подтверждения стабильности теста () можно использовать формулу нормальной аппроксимации биномиального распределения для размера выборки :
Где и — вероятности ошибок I и II рода.

(базовый уровень): насколько плох был тест (или порог, который мы считаем плохим). Допустим, он падал в 5% случаев (). (целевой уровень): каким хотим его видеть. По хорошему — 0% падений (или хотя бы меньше 1%).
(разница): .
Это позволяет научно обосновать, сколько раз нужно запустить тест, чтобы объявить его исправленным после рефакторинга
¶ Наблюдаемость в тестировании
В классическом тестировании результатом является бинарный статус: Pass или Fail. В TestOps этого недостаточно. Нужно знать почему тест упал, как он выполнялся и каково было состояние системы в этот момент. Наблюдаемость (Observability) строится на трех компонентах: метрики, логи и трассировка.
¶ Prometheus и количественная оценка качества
Prometheus стал стандартом для сбора метрик в облачных средах. В контексте тестирования он позволяет собирать данные не только о состоянии Production, но и о самом процессе тестирования.
| Тип метрики | Описание | Примеры использования в TestOps |
|---|---|---|
| Counter | Монотонно возрастающий счетчик. Может только увеличиваться или сбрасываться при рестарте | test_failures_total (общее число падений),assertions_count_total (число проверок), http_requests_total (число запросов к мокам) |
| Gauge | Значение, которое может меняться вверх и вниз | tests_running_current (число тестов в данный момент),queue_size (размер очереди CI), memory_usage_bytes (потребление памяти контейнером с тестами) |
| Histogram | Распределение значений по интервалам. Используется для расчета квантилей (p95, p99) | test_execution_duration_seconds (длительность теста). Позволяет увидеть, что 95% тестов проходят за 1 с, но 5% — за 30 с |
Пример
monitoring/
├── docker-compose.yml
├── prometheus.yml
└── app/
├── Dockerfile
└── main.py
services:
app:
build: ./app
ports:
- "8000:8000"
networks:
- monitoring
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
networks:
- monitoring
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
networks:
- monitoring
networks:
monitoring:
driver: bridge
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'python-app'
static_configs:
- targets: ['app:8000']
from prometheus_client import start_http_server, Counter, Histogram, Gauge
import time
import random
TESTS_EXECUTED = Counter('tests_executed_total', 'Total tests executed', ['status', 'suite'])
TEST_DURATION = Histogram(
'test_duration_seconds',
'Duration of tests in seconds',
['suite'],
buckets=(0.1, 0.5, 1.0, 2.0, 5.0, 10.0, float("inf"))
)
ACTIVE_TESTS = Gauge('tests_active_count', 'Number of tests currently running')
def run_simulated_test(test_name, suite_name):
ACTIVE_TESTS.inc()
start_time = time.time()
status = "passed"
try:
with TEST_DURATION.labels(suite=suite_name).time():
duration = random.lognormvariate(-0.5, 0.5)
time.sleep(duration)
if random.random() > 0.85:
raise Exception("Fail!")
except Exception:
status = "failed"
finally:
ACTIVE_TESTS.dec()
TESTS_EXECUTED.labels(status=status, suite=suite_name).inc()
print(f"Test {test_name} finished: {status}")
if __name__ == '__main__':
# метрики будут доступны по адресу http://localhost:8000/metrics
start_http_server(8000)
print("Prometheus exporter running on port 8000...")
while True:
run_simulated_test(f"test_{random.randint(1,100)}", "login_suite")
time.sleep(random.uniform(0.1, 0.5))
Теперь можно строить визуализации в Grafana с применением языка PromQL.
¶ Трассировка и контекст ошибок в Sentry
Метрики говорят, что что-то сломалось. Логи и стектрейсы говорят, почему это произошло. Sentry — платформа для мониторинга ошибок.
Пример (conftest.py)
import pytest
import sentry_sdk
import os
from sentry_sdk.integrations.logging import LoggingIntegration
def pytest_sessionstart(session):
dsn = os.getenv("PYTEST_SENTRY_DSN")
if dsn:
sentry_sdk.init(
dsn=dsn,
environment="ci-test",
integrations=[LoggingIntegration(level=None, event_level=None)],
traces_sample_rate=1.0,
release=os.getenv("CI_COMMIT_SHA")
)
@pytest.hookimpl(tryfirst=True, hookwrapper=True)
def pytest_runtest_makereport(item, call):
outcome = yield
rep = outcome.get_result()
# обрабатываем только фазу вызова теста (call) и только падения (failed)
if rep.when == "call" and rep.failed:
with sentry_sdk.push_scope() as scope:
# обогащаем событие метаданными
scope.set_tag("test_name", item.name)
scope.set_tag("test_file", item.fspath)
scope.set_tag("ci_job_id", os.getenv("CI_JOB_ID"))
# если тест помечен маркером @pytest.mark.flaky
if item.get_closest_marker("flaky"):
scope.set_tag("is_flaky_marked", "true")
if call.excinfo:
sentry_sdk.capture_exception(call.excinfo.value)
else:
sentry_sdk.capture_message(f"Test failed: {item.name}")
¶ Инжиниринг CI/CD пайплайнов
Конвейер CI/CD — производственная линия ПО. Эффективность TestOps напрямую зависит от архитектуры этой линии.
Частая ошибка — путаница между кэшем (Cache) и артефактами (Artifacts). Это приводит к замедлению пайплайнов и перерасходу дискового пространства.
| Характеристика | Cache | Artifacts |
|---|---|---|
| Назначение | Ускорение сборки за счет сохранения временных файлов (зависимости, скомпилированные объекты) | Передача данных между стадиями и сохранение результатов для пользователя |
| Доступность | Может быть недоступен; если кэша нет, все скачается заново | Гарантированная доступность; если артефакт не загрузился, то конвейер падает |
| Область действия | Между разными запусками пайплайна (один и тот же ключ) | Только внутри одного пайплайна |
| Примеры | .cache/pip, node_modules, .m2/repository. |
junit.xml, coverage.html, скомпилированный бинарь .exe. |
Для Python критически важно кэшировать директорию, куда pip складывает скачанные пакеты. GitLab Runner ищет кэш только внутри проектной директории. Поэтому нужно переопределять переменную PIP_CACHE_DIR.
variables:
# указываем pip хранить кэш внутри папки проекта
PIP_CACHE_DIR: "$CI_PROJECT_DIR/.pip-cache"
cache:
# используем checksum файла requirements.txt в качестве ключа кэша
key:
files:
- requirements.txt
paths:
-.pip-cache/
stages:
- test
run_unit_tests:
stage: test
image: python:3.13-slim
before_script:
- pip install virtualenv
- virtualenv venv
- source venv/bin/activate
- pip install -r requirements.txt
script:
- pytest tests/ --junitxml=report.xml
artifacts:
when: always
reports:
junit: report.xml
expire_in: 1 week
Для снижения времени выполнения ( в законе Литтла) необходимо использовать параллелизм. GitHub Actions предоставляет механизм matrix strategy, позволяющий запускать тесты одновременно в разных конфигурациях.
name: Cross-Platform Testing
on: [push, pull_request]
jobs:
test:
name: Test Py${{ matrix.python-version }} on ${{ matrix.os }}
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
os: [ubuntu-latest, windows-latest]
python-version: ['3.8', '3.9', '3.10']
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
cache: 'pip'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run Pytest
run: pytest --junitxml=test-results-${{ matrix.os }}-${{ matrix.python-version }}.xml --durations=10
- name: Upload Test Artifacts
if: always()
uses: actions/upload-artifact@v4
with:
name: junit-results-${{ matrix.os }}-${{ matrix.python-version }}
path: test-results-*.xml
JUnit XML — универсальный язык обмена данными о тестах. Современные CI системы (GitLab, GitHub, Azure, Jenkins) умеют парсить этот формат.
Структура:
<testsuites>
<testsuite name="pytest" errors="0" failures="1" skipped="0" tests="3" time="0.123">
<testcase classname="tests.test_auth" name="test_login_success" time="0.045"/>
<testcase classname="tests.test_auth" name="test_login_failure" time="0.056">
<failure message="AssertionError: 403!= 200">...</failure>
</testcase>
</testsuite>
</testsuites>
В TestOps можем использовать эти файлы не только для отображения в UI, но и для программного анализа. Например, для вычисления Flakiness Rate (коэффициента нестабильности)
Можно написать скрипт, который запускается в конце CI конвейера, сравнивает текущие результаты с историческими (скачанными из AWS S3 или предыдущих артефактов) и блокирует слияние, если найдены новые flaky-тесты:
from junitparser import JUnitXml, Failure
def detect_flaky_tests(current_xml_path, previous_xml_path):
current = JUnitXml.fromfile(current_xml_path)
previous = JUnitXml.fromfile(previous_xml_path)
current_failures = {case.name for suite in current for case in suite if isinstance(case.result, Failure)}
previous_failures = {case.name for suite in previous for case in suite if isinstance(case.result, Failure)}
# тест упал сейчас, но проходил раньше - потенциально новый баг
new_failures = current_failures - previous_failures
# тест прошел сейчас, но падал раньше - потенциально flaky
potential_flaky = previous_failures - current_failures
print(f"New failures: {len(new_failures)}")
print(f"Potential flaky: {len(potential_flaky)}")
¶ Управление нестабильными тестами
Основные категории неставильности.
Асинхронность и Race Conditions
Тест проверяет наличие элемента на UI до того, как AJAX-запрос завершился. Лечится переходом от фиксированных sleep() к умным ожиданиям wait_until().
Загрязнение состояния
Предыдущий тест изменил глобальную переменную или запись в БД и не очистил за собой. При параллельном запуске это приводит к хаотичным падениям. Лечится правильным использованием фикстур.
Зависимость от порядка
Тест проходит только если запускается после другого теста.
Инфраструктурные проблемы
Network timeouts, нехватка ресурсов на раннере.
¶ Стратегии обнаружения и изоляции
Стресс-тестирование
Перед тем как влить новый тест в ветку main его нужно прожарить. Плагин pytest-flakefinder или команда pytest --count=50 позволяют запустить тест 50 раз подряд. Если он упал хотя бы раз, то он flaky и требует доработки.
Карантин
Если тест в main начал демонстрировать нестабильность, то его нельзя просто удалить (потеря покрытия) или игнорировать (красный билд). Его нужно поместить в карантин. Маркировка теста декоратором @pytest.mark.flaky или @pytest.mark.quarantine.
Тесты из карантина запускаются отдельным Job с
allow_failure: true. Мы видим их результаты, но они не блокируют релиз.
Ответственный инженер обязан вывести тест из карантина (починить или удалить) в течение SLA
Интеллектуальные перезапуски
Плохо: глобальный pytest --reruns 3 для всех тестов. Это скрывает реальные баги. Хорошо: перезапуски только для специфических исключений (NetworkError, TimeoutError), но не для AssertionError.
pytest --reruns 5 --only-rerun HTTPError
Для приоритизации работ по техническому долгу в TestOps вводится метрика Flakiness Score:
Где Flip — изменение статуса (Pass -> Fail или Fail -> Pass) на одном и том же коммите при перезапусках. Тесты с высоким Score являются первоочередными кандидатами на удаление или полное переписывание.
¶ Заключение
Внедрение этих практик позволяет достичь главной цели инженерии ПО: поставки качественного продукта с максимальной скоростью и минимальными рисками