¶ Введение
Индустрия разработки ПО находится в точке пересмотра подходов к обеспечению качества. Традиционная парадигма автоматизации тестирования (детерминированные скрипты) достигла своего предела эффективности. Такая автоматизация сталкивается с проблемой, известной как "парадокс обслуживания": по мере роста покрытия кодовой базы тестами экспоненциально растут затраты на поддержку тестовой инфраструктуры, что в конечном итоге нивелирует выгоды от автоматизации.
Инженеры вынуждены тратить 50% рабочего времени не на создание новых проверочных сценариев, а на выявление и исправление ложных срабатываний, вызванных незначительными изменениями в UI или структуре приложения
Попыткой решения проблемы стало внедрение методов искусственного интеллекта и машинного обучения в процессы тестирования. Это смена парадигмы от "автоматизированного тестирования" (automated testing), где человек пишет скрипты, к "автономному тестированию" (autonomous testing), где алгоритмы самостоятельно генерируют, исполняют и поддерживают тесты.
Источник с инфографикой, Test Guild Blog by Joe Colantonio
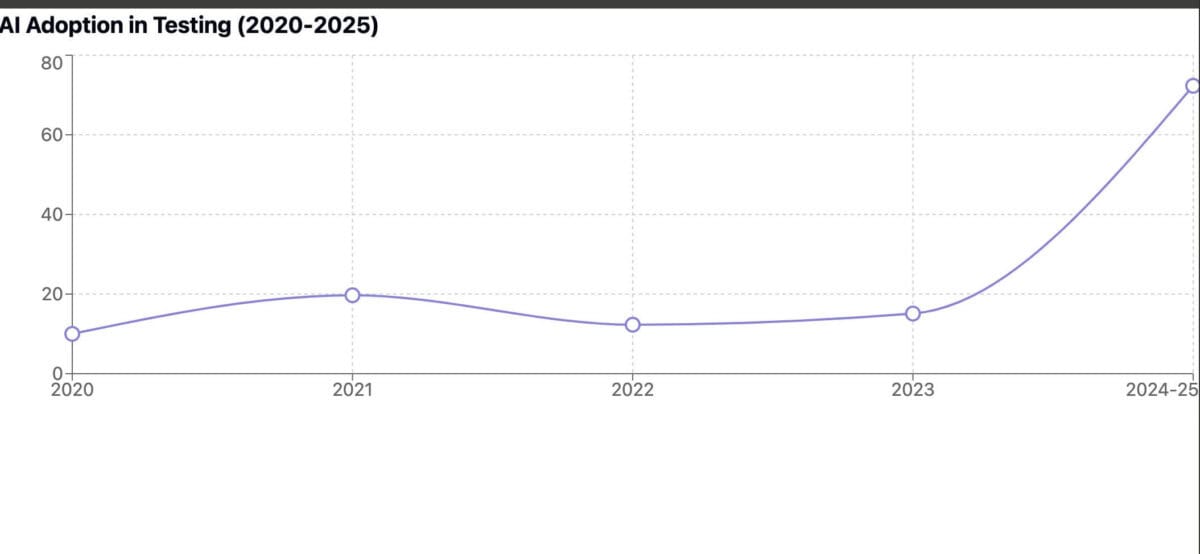
В конце 2025 года весь цикл жизни ПО включает применение AI-инструментов
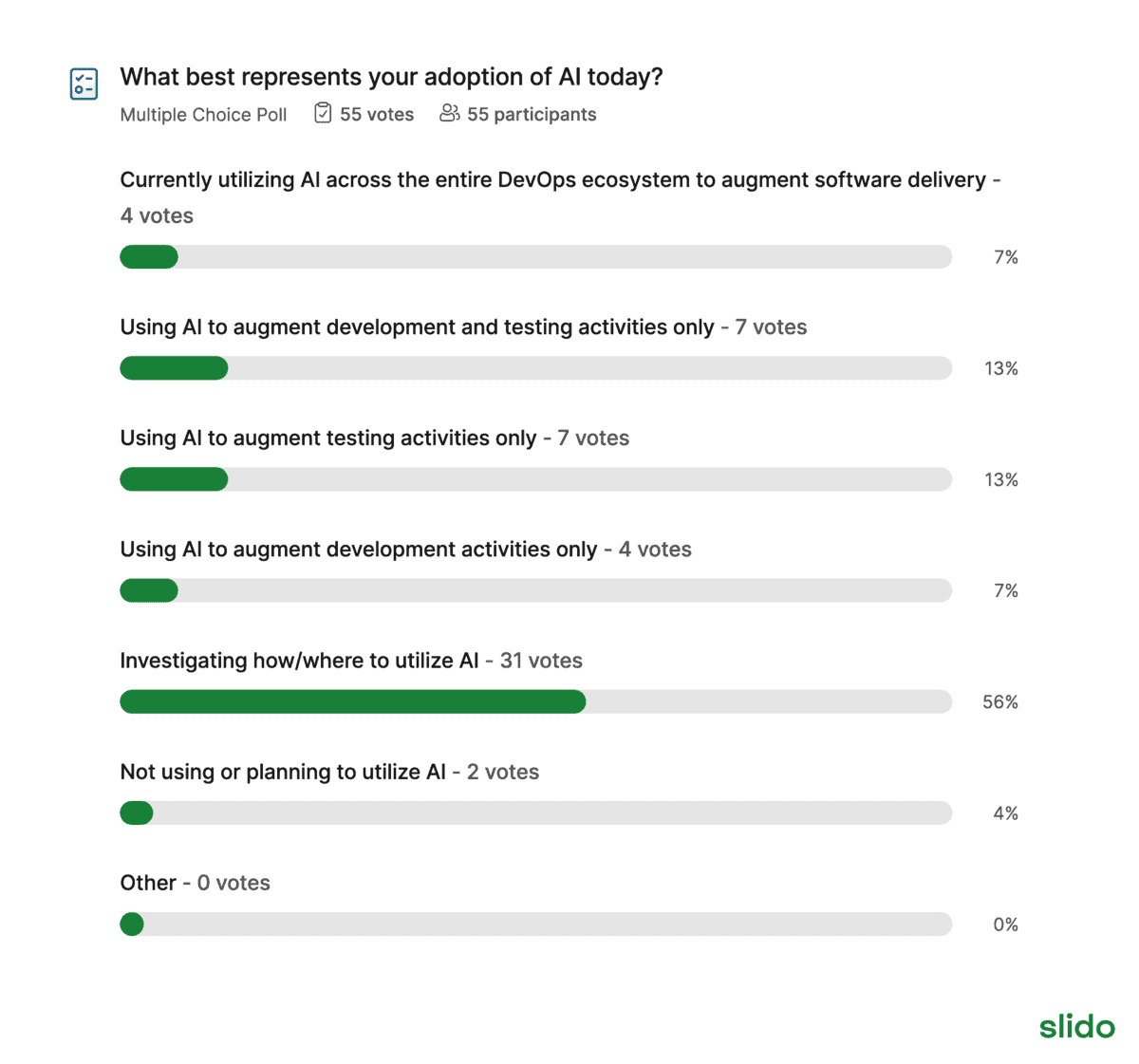
Три реальных варианта применения ИИ в тестировании
- автогенерация тестов (autogeneration)
- самовосстановление (self-healing)
- умная отчетность (smart reporting)
¶ Автогенерация тестов
Автоматическая генерация тестов (Test Case Generation) представляет собой задачу создания набора входных данных и ожидаемых результатов, которые максимизируют покрытие тестируемого кода или вероятность обнаружения дефектов.
Два подхода:
- поиск (Search-Based Software Testing, SBST)
- генерация на основе больших языковых моделей (LLM-based generation)
¶ Search-Based Software Testing
Подход SBST формулирует задачу генерации тестов как задачу оптимизации. Целевая функция (fitness function, которую минимизируем) определяет, насколько "хорошим" является конкретный тестовый набор, а алгоритм поиска (как правило, генетический) пытается найти глобальный максимум этой функции в пространстве всех возможных входных данных.
В контексте SBST каждый тестовый случай или набор тестов рассматривается как "хромосома" или "индивид". Процесс генерации имитирует биологическую эволюцию:
Инициализация (Initialization)
Создается начальная популяция случайных тестов. Для объектно-ориентированных языков это означает генерацию последовательностей вызовов конструкторов и методов со случайными аргументами.
Оценка приспособленности (Fitness Evaluation)
Каждый тест запускается, измеряется его эффективность (покрытие кода).
Селекция (Selection)
Наиболее эффективные тесты отбираются для размножения.
Скрещивание (Crossover)
Обмен частями кода между двумя тестами. Например первая половина вызовов методов берется из теста А, а вторая — из теста Б.
Мутация (Mutation)
Случайные изменения в тесте: замена аргумента, добавление/удаление вызова метода, изменение порядка инструкций.
Цикл повторяется до тех пор, пока не будет достигнуто целевое покрытие или не исчерпан бюджет времени
Для критерия покрытия ветвлений (branch coverage) целевая функция обычно состоит из двух компонентов: уровня подхода (approach level) и дистанции ветвления (branch distance). Уровень подхода измеряет, сколько контрольных узлов тест прошел успешно на пути к целевому ветвлению. Дистанция ветвления оценивает, насколько близко условие в целевом узле было к переключению в требуемое состояние.
Для нормализации дистанции в диапазон используется функция или аналогичная .Общая функция приспособленности для конкретной цели минимизируется и имеет вид:
Чем меньше значение, тем ближе тест к покрытию цели
Пример: взлом кофемашины
class CoffeeMachine:
def __init__(self):
self.is_on = False
self.beans = 0
def turn_on(self):
self.is_on = True
def add_beans(self, amount):
if not self.is_on:
return
self.beans += amount
if self.beans > 100:
raise Exception("Бум!") # цель
Инициализация (Случайные скрипты)
Алгоритм генерирует случайные вызовы методов со случайными аргументами.
Индивид А:
def test_a():
cm = CoffeeMachine()
cm.add_beans(50)
# результат: is_on = False
# уперлись в "if not self.is_on"
Индивид B:
def test_b():
cm = CoffeeMachine()
cm.turn_on()
# результат: is_on = True
# но метод add_beans вообще не вызван
Алгоритм берет части кода от обоих родителей. Например, от Индивида B берется подготовка состояния (turn_on), а от Индивида A — действие (add_beans).
Индивид C:
def test_c():
cm = CoffeeMachine()
cm.turn_on()
cm.add_beans(50)
Оценка приспособленности:
- cm.turn_on() — состояние is_on = True
- cm.add_beans(50) — условие if not self.is_on пройдено успешно
- Approach Level = 0 (добрались до финального if)
- beans > 100, у нас 50; Branch Distance:
Алгоритм выбирает Индивида C и применяет операторы мутации кода (получается Индивид D).
def test_d():
cm = CoffeeMachine()
cm.turn_on()
cm.add_beans(60)
cm.add_beans(60)
Выводы делайте сами 
Важный момент: когда хотим максимизировать Branch Coverage всего класса или программы, то задача меняется. Ищем не одного идеального индивида, а идеальный набор или популяцию (Test Suite).
Вместо одной функции приспособленности алгоритм составляет список всех целей (всех ветвлений if/else в коде)
На практике используется Python Generation for Unit Testing (Pynguin).
class CoffeeMachine:
def __init__(self):
self.is_on = False
self.beans = 0
def turn_on(self):
self.is_on = True
def add_beans(self, amount):
if not self.is_on:
return
self.beans += amount
if self.beans > 100:
raise Exception("Бум!")
Вот так заряжется пингвин:
pip install pynguin
pynguin --project-path . --output-path ./tests --module-name coffee --algorithm DYNAMOSA
Результат:
# Test cases automatically generated by Pynguin (https://www.pynguin.eu).
# Please check them before you use them.
import pytest
import coffee as module_0
def test_case_0():
coffee_machine_0 = module_0.CoffeeMachine()
assert coffee_machine_0.beans == 0
coffee_machine_1 = module_0.CoffeeMachine()
assert coffee_machine_1.beans == 0
coffee_machine_0.add_beans(coffee_machine_1)
coffee_machine_2 = module_0.CoffeeMachine()
assert coffee_machine_2.beans == 0
var_0 = coffee_machine_2.turn_on()
coffee_machine_2.add_beans(var_0)
def test_case_1():
coffee_machine_0 = module_0.CoffeeMachine()
assert coffee_machine_0.beans == 0
coffee_machine_0.turn_on()
def test_case_2():
coffee_machine_0 = module_0.CoffeeMachine()
assert coffee_machine_0.beans == 0
coffee_machine_1 = module_0.CoffeeMachine()
assert coffee_machine_1.beans == 0
coffee_machine_0.add_beans(coffee_machine_1)
coffee_machine_1.turn_on()
float_0 = 1294.8
with pytest.raises(Exception):
coffee_machine_1.add_beans(float_0)
def test_case_3():
coffee_machine_0 = module_0.CoffeeMachine()
assert coffee_machine_0.beans == 0
coffee_machine_0.add_beans(coffee_machine_0)
coffee_machine_1 = module_0.CoffeeMachine()
assert coffee_machine_1.beans == 0
coffee_machine_1.turn_on()
float_0 = -976.09395
var_0 = coffee_machine_1.add_beans(float_0)
assert coffee_machine_1.beans == pytest.approx(-976.09395, abs=0.01, rel=0.01)
Информация о покрытии в файле pynguin-report/statistics.csv (в данном случае, значение 1.0)
Использование алгоритма DynaMOSA (Dynamic Many-Objective Sorting Algorithm) в Pynguin позволяет достичь покрытия ветвлений до 68% на проектах с открытым исходным кодом, что значительно превосходит случайное тестирование
SBST-инструменты реально исполняют код! Они генерируют случайные вызовы методов. Случайный тест может навредить окружению (действия с файлами, сетью и т. д.). Используйте этот подход в изолированных средах.
¶ LLM-based generation
LLM (Large Language Models) обладают семантическим пониманием кода, что позволяет им генерировать тесты, которые не только обеспечивают покрытие, но и являются понятными для человека, включают осмысленные утверждения и моки.
Few-Shot Learning
Предоставление модели примеров пар "код функции — код теста". Это задает стиль (использование pytest вместо unittest, использование фикстур) и помогает модели следовать паттернам проекта. Исследование на эту тему
Chain-of-Thought (CoT)
Принуждение модели к пошаговому рассуждению. Вместо прямого запроса кода промпт строится так, чтобы модель сначала проанализировала логику функции, выделила классы эквивалентности и граничные значения. Только потом реализовала тест. Это снижает вероятность логических ошибок и галлюцинаций.
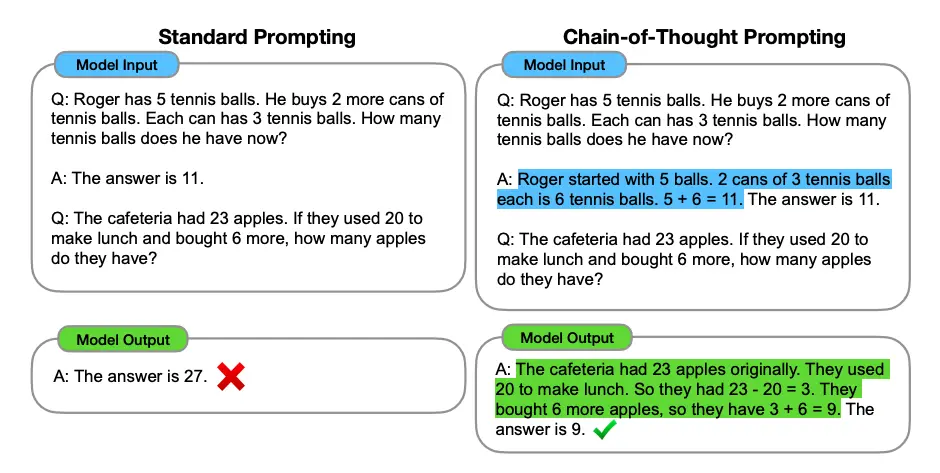
Пример шаблона CoT для генерации тестов:
- проанализируй входные параметры функции и их ограничения
- перечисли сценарии тестирования (позитивные, негативные, граничные)
- напиши код на pytest, реализующий эти сценарии
- убедись, что все внешние зависимости замокированы
¶ Самовосстановление тестов
Помним, что основной проблемой автоматизации UI-тестов является хрупкость.
До 70% сбоев в CI/CD конвейерах вызваны не ошибками в продукте, а изменениями в верстке (изменение ID, классов, структуры DOM), которые делают тестовые локаторы невалидными
Технологии Self-healing призваны решить проблему путем динамической адаптации тестов к изменениям интерфейса. Традиционный подход полагается на жесткие селекторы (xpath=//div[@id='submit']). Предлагается использование ансамбля локаторов для каждого элемента. Вместо одного пути, система хранит набор атрибутов: ID, имя, классы, текст, позицию, соседей. В случае сбоя основного локатора запускается процедура "лечения".
Каждый атрибут локатора имеет вес , отражающий его надежность. Для кандидата на странице вычисляется оценка соответствия искомому элементу:
где — функция, возвращающая 1, если -й атрибут совпадает, и 0 (или значение сходства) в противном случае. Элемент с максимальным , превышающим определенный порог, считается искомым.
Для вычисления используются алгоритмы нечеткого сравнения.
Расстояние Левенштейна (Levenshtein Distance)
Подходит для текстовых атрибутов. Позволяет найти элемент, даже если в тексте была исправлена опечатка или изменено одно слово. Нормированная метрика сходства выглядит так:
где — минимальное число операций вставки, удаления и замены для превращения строки в
Косинусное сходство (Cosine Similarity)
Векторы признаков и (bag-of-words из CSS классов) сравниваются по углу между ними в многомерном пространстве:
Коэффициента Жаккара (Intersection over Union)
где — мощность пересечения множеств (количество общих элементов), — мощность объединения множеств (общее количество уникальных элементов в обоих наборах).
Пример.
import Levenshtein
from playwright.sync_api import sync_playwright, Page, Locator
class SelfHealingAgent:
def __init__(self, page: Page):
self.page = page
# веса атрибутов
self.weights = {
"id": 0.5,
"class": 0.1,
"text": 0.4
}
self.threshold = 0.65 # порог уверенности
def _calculate_levenshtein_sim(self, s1: str, s2: str) -> float:
if not s1 or not s2:
return 0.0
dist = Levenshtein.distance(s1, s2)
max_len = max(len(s1), len(s2))
return 1 - (dist / max_len)
def _generate_xpath(self, element_handle) -> str:
return element_handle.evaluate("""(element) => {
if (element.id !== '')
return '//*[@id=\"' + element.id + '\"]';
if (element === document.body)
return element.tagName;
var ix = 0;
var siblings = element.parentNode.childNodes;
for (var i = 0; i < siblings.length; i++) {
var sibling = siblings[i];
if (sibling === element)
return arguments.callee(element.parentNode) + '/' + element.tagName.toLowerCase() + '[' + (ix + 1) + ']';
if (sibling.nodeType === 1 && sibling.tagName === element.tagName)
ix++;
}
}""")
def _calculate_score(self, element_handle, target_meta: dict) -> float:
current_score = 0.0
# сравнение ID
try:
el_id = element_handle.get_attribute("id") or ""
if el_id == target_meta.get("id"):
current_score += self.weights["id"] * 1.0
except:
pass
# сравнение текста
try:
el_text = element_handle.inner_text() or ""
text_sim = self._calculate_levenshtein_sim(target_meta.get("text"), el_text)
current_score += self.weights["text"] * text_sim
except:
pass
# сравнение классов (пересечение множеств - IoU)
try:
el_classes = set((element_handle.get_attribute("class") or "").split())
target_classes = set(target_meta.get("classes", []))
if target_classes:
intersection = len(el_classes & target_classes)
union = len(el_classes | target_classes)
class_sim = intersection / union if union > 0 else 0
current_score += self.weights["class"] * class_sim
except:
pass
return current_score
def find_and_heal(self, selector: str, target_meta: dict) -> Locator:
try:
# попытка найти элемент
locator = self.page.locator(selector)
locator.wait_for(state="attached", timeout=2000)
return locator
except Exception as e:
print("Локатор не найден. Нужно лечиться!")
return self._heal(target_meta)
def _heal(self, target_meta: dict):
candidates = self.page.query_selector_all(target_meta["tag"])
best_candidate = None
max_score = 0.0
print("Анализ кандидатов")
for candidate in candidates:
score = self._calculate_score(candidate, target_meta)
if score > max_score:
max_score = score
best_candidate = candidate
if max_score >= self.threshold:
print(f"Элемент восстановлен! Оценка: {max_score}")
xpath = self._generate_xpath(best_candidate)
return self.page.locator(f"xpath={xpath}")
else:
raise Exception(f"Self-healing не получился. Максимальная оценка: {max_score}")
def run():
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
# Стало:
page.set_content("""
<div class="container">
<button id="btn-send-new" class="btn primary">Отправить</button>
<button id="cancel" class="btn secondary">Отмена</button>
</div>
""")
old_selector = "#submit-btn"
historical_meta = {
"tag": "button",
"id": "submit-btn",
"text": "Отпрвить",
"classes": ["btn", "primary"]
}
agent = SelfHealingAgent(page)
element = agent.find_and_heal(old_selector, historical_meta)
if element:
element.click()
browser.close()
if __name__ == "__main__":
run()
¶ Умная отчетность
¶ Кластеризация логов
Третий уровень AI-трансформации касается анализа результатов тестирования. В современных CI/CD процессах генерируются тонны логов. Ручной анализ причин падения сборки является трудоемким и подвержен ошибкам. Smart Reporting предполагает использование методов обработки естественного языка (Natural Language Processing, NLP) и кластеризации для автоматизации этого процесса.
Цель Smart Reporting — автоматически определить корневую причину (Root Cause Analysis, RCA) падения теста и классифицировать ее: ошибка продукта, проблема инфраструктуры, или хрупкий тест
Стек-трейсы и логи содержат много шума: адреса памяти, временные метки, уникальные идентификаторы потоков. Для корректной работы алгоритмов NLP необходимо провести нормализацию данных.
Используются регулярные выражения для замены динамических данных на специальные токены:
- удаление адресов памяти (0x7f...): re.sub(r'0x[0-9a-fA-F]+', '', log)
- удаление временных меток и цифр: re.sub(r'\d+', '', log)
Это позволяет алгоритму в будущем понять, что ошибки Error at 0x123 и Error at 0x456 идентичны по семантике.
Для анализа текстовые логи преобразуются в числовые векторы. Можно использовать TF-IDF (Term Frequency — Inverse Document Frequency). Он позволяет выделить уникальные термины ошибки (NullPointerException), подавляя часто встречающиеся слова (info, log); это классика:
N — общее число записей в журнале, а знаменатель — число записей, содержащих термин t.
Формула со сглаживанием:
Сглаживание используется для решения двух основных проблем:
- предотвращение деления на ноль для неизвестных терминов
- предотвращение нулевого веса для терминов, присутствующих во всех записях
Когда получены векторные представления обычно применяется алгоритм DBSCAN.
Он не требует указания количества кластеров (число типов ошибок неизвестно) и выделяет шум:
- логи с одинаковой причиной падения образуют плотный кластер
- уникальная ошибка (новый баг) определяется как выброс (шум)
¶ LogBERT
Можно использовать более современный подход — LogBert.
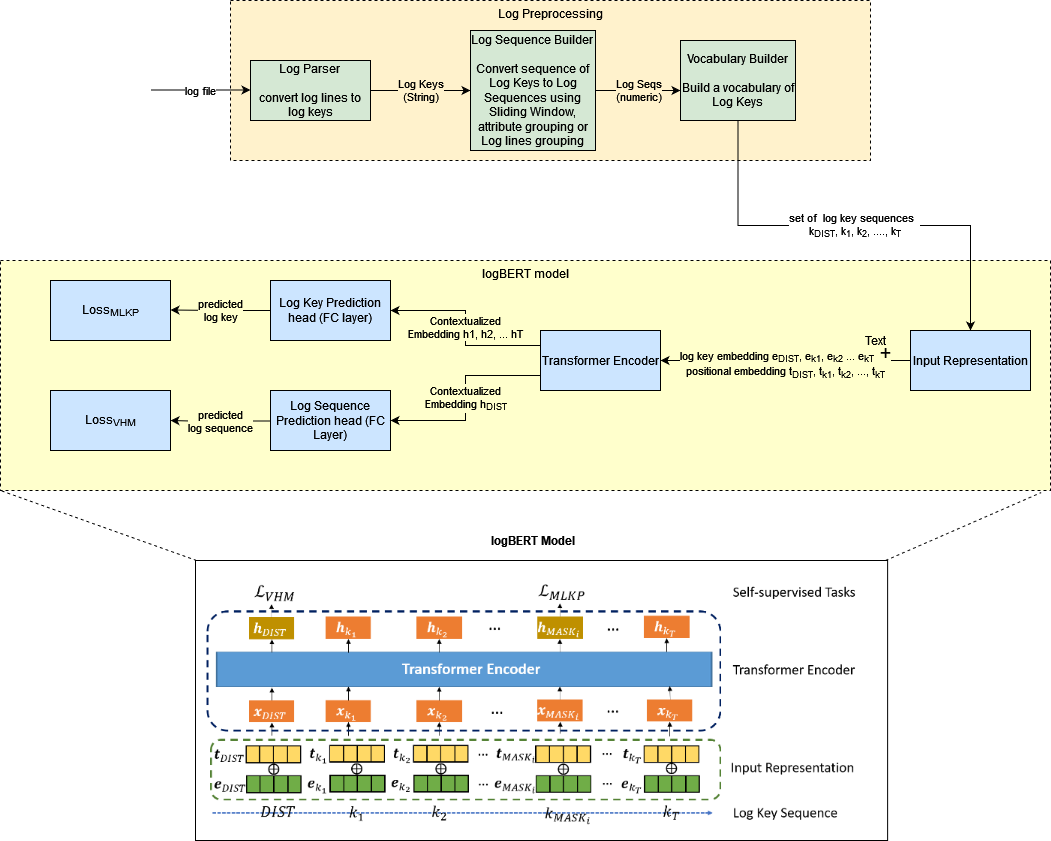
Log File
Есть текстовый лог (2025-12-11 Error: Connection failed).
Log Parser
Система убирает шум (даты, IP-адреса) и оставляет суть события. Строка превращается в Log Key.
Log Sequence Builder
Система собирает события в последовательности.
Vocabulary Builder
Система создает словарь всех возможных событий и присваивает им номера. Теперь логи — последовательности чисел.
Input Representation
Система берет последовательность ключей логов () и добавляет к ним информацию о позиции (Positional Embedding).
Transformer Encoder
Обучается понимать взаимосвязи между событиями.
Система решает две задачи, которые критически важны для QA и отчетов
Masked Log Key Prediction
Система скрывает одно событие из цепочки и пытается угадать, что там должно быть, основываясь на соседних событиях. Система видит: Старт -> Загрузка -> [MASK] -> Успех. Обычно здесь идет "Обработка данных". Если в реальном тесте произошла "Ошибка 404" — сигнал о баге.
— Negative Log Loss (кросс-энтропия)
Volume Hypersphere Minimization
Система учится понимать, как выглядит нормальная сессия работы ПО. Она пытается собрать все нормальные логи в одну плотную гиперсферу.
— векторное представление всей последовательности логов, — центр гиперсферы (фиксированная точка в пространстве, обычно получается усреднением нормальных логов после нескольких прогонов).
Если приходит новый лог, который находится далеко от гиперсферы, то система помечает всю сессию как аномальную.
Часто две задачи решаются одновременно:
— коэффициент веса для баланса между двумя задачами.
¶ Выводы
Интеграция технологий искусственного интеллекта в тестирование программного обеспечения — необратимый процесс.
AI-агенты уже стали коллегами
Автогенерация на базе генетических алгоритмов и LLM решает проблему покрытия тест-кейсами. Механизмы самовосстановления способствуют повышению стабильности тестов. Интеллектуальная отчетность превращает логи в знание.