¶ Введение
Тестирование традиционно воспринимается как "черный ящик" в процессе разработки. Руководители проектов задают вопросы: "Насколько хорошо мы тестируем?", "Готов ли продукт к релизу?", "Где узкие места?". Без объективных метрик ответы на эти вопросы остаются субъективными.

Вот к чему приводит тестирование без метрик:
- команда не может объективно сказать, улучшается ли качество от спринта к спринту
- решение "релизить или не релизить" принимается на основе ощущений, а не данных
- непонятно, какие области продукта требуют большего внимания
- без цифр трудно доказать необходимость расширения команды тестирования
- проблемы в процессах остаются незамеченными
Немного истории:
- начало 1980-х: gервые попытки измерения качества (COCOMO от Barry Boehm)
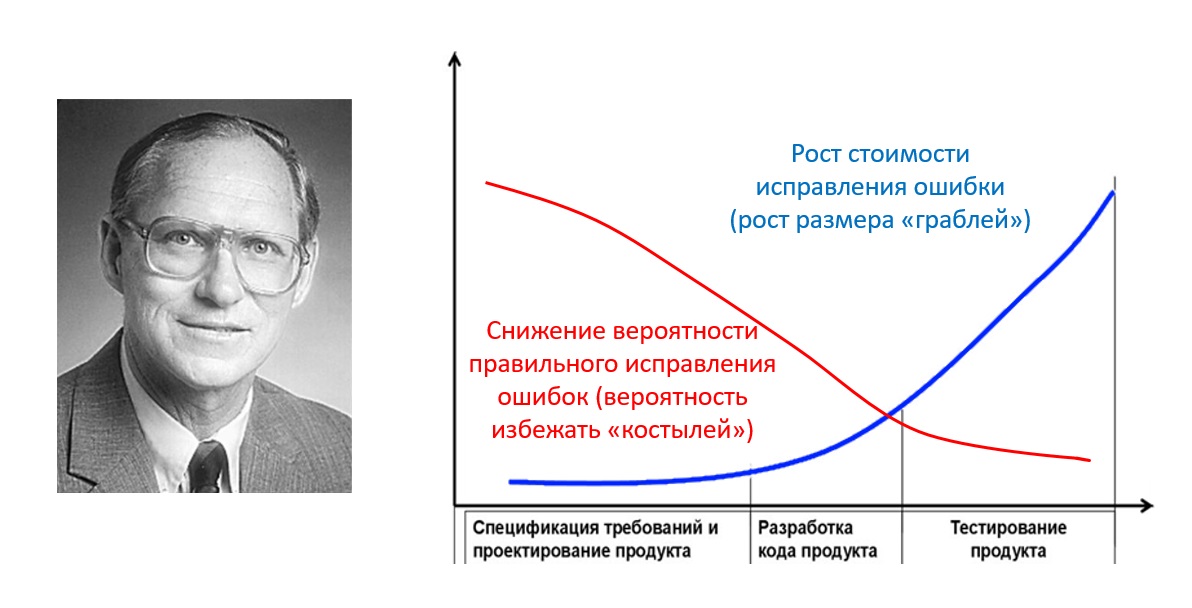
- Конец 1980-х — начало 1990-х: появление моделей зрелости (CMM от SEI), организации начинают собирать метрики
-
1990-е годы: распространение автоматизированного тестирования, возникают метрики покрытия кода
-
2000-е годы: Agile-трансформация меняет подход к метрикам (акцент на скорости обратной связи, то есть расчетов этих метрик)
-
2010-е — настоящее время: DevOps и непрерывная поставка требуют метрик в реальном времени, появляются DORA-метрики
| Цель | Метрики |
|---|---|
| Оценка полноты тестирования | Coverage (код, требования) |
| Оценка качества продукта | Defect Detection Efficiency, Defect density |
| Оценка эффективности процесса | MTTR, MTTD, test pass rate |
| Прогнозирование | Trend analysis, velocity |
Методология Goal-Question-Metric (GQM, by Victor Basili) является стандартом для определения метрик
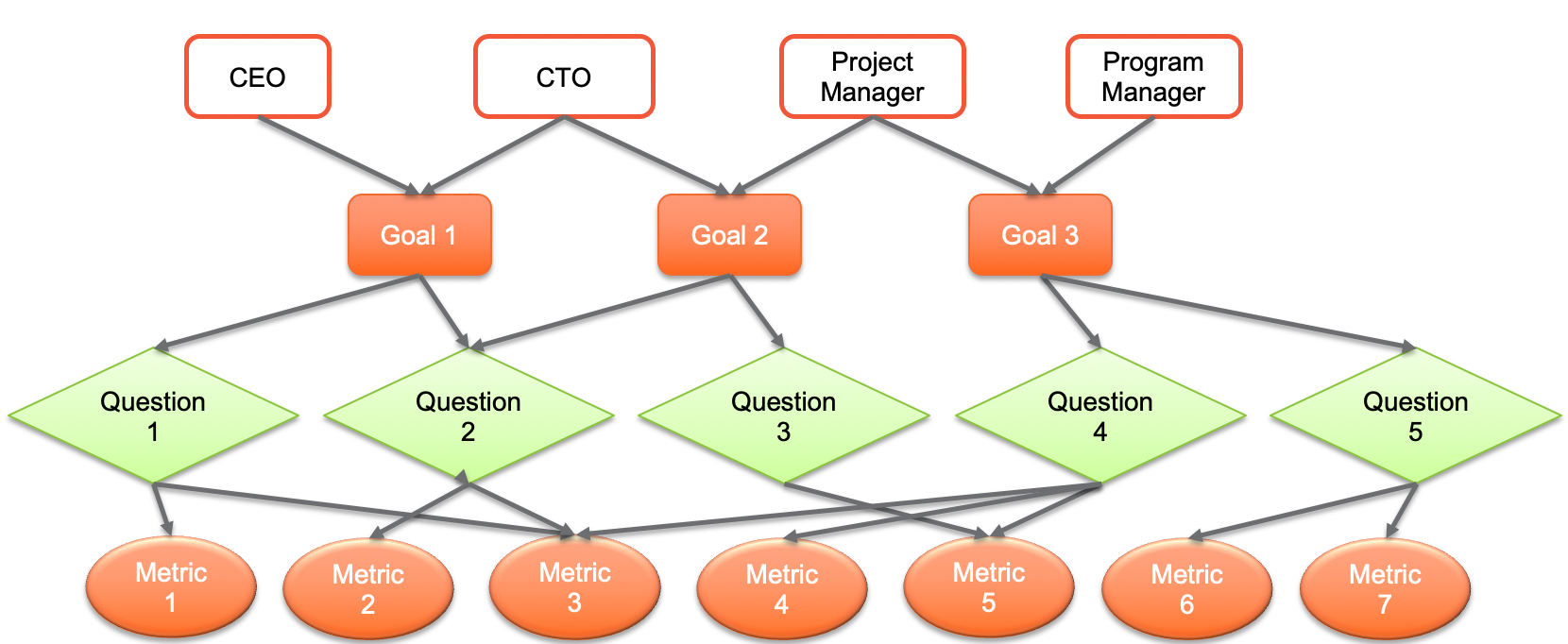
Пример бизнес-цели: cнизить количество критических дефектов в Production
Пример одного вопроса: какой процент критических дефектов обнаруживается до релиза?
Пример другого вопроса: как быстро исправляются критические дефекты?
Ответы: эффективность обнаружения дефектов, MTTR
Метрики могут приносить вред, если использовать их неправильно
Закон Гудхарта
Когда мера становится целью, она перестаёт быть хорошей мерой

Если KPI тестировщика — количество найденных багов, то он начнёт заводить баги на каждую мелочь, а не искать критические проблемы.
Vanity Metrics (метрики тщеславия)
Некоторые метрики хорошо выглядят в отчетах, но не помогают принимать решения:
- написали 10 000 тестов, но сколько из них находят реальные баги?
- покрытие кода 95%, но покрыты ли критические сценарии?
Gaming the Metrics (манипулирование метриками)
Команды оптимизируют метрику, а не то, что она должна измерять:
- удаление сложных тестов для повышения количества пройденных тестов
- написание тривиальных тестов для повышения покрытия
Метрики без контекста
Сравнение метрик между командами без учета специфики проектов является бессмысленным. Defect Density в банковском ПО и мобильной игре несравнимы.
Метрики должны направлять поведение, а не наказывать за плохие показатели
¶ Что и как измеряем в тестировании
По типу измерения:
- количественные: число тестов, дефектов, строк кода
- объективность, простота сбора
- не учитывают контекст и важность
- качественные: severity, priority, risk level
- учитывают бизнес-контекст
- субъективность оценки
По времени сбора:
-
опережающие (leading indicators): test coverage, code complexity, technical debt
- предсказывают будущие проблемы
- позволяют принять превентивные меры
- снижение покрытия кода предвещает рост дефектов в Production
-
запаздывающие (lagging indicators): production defects, customer complaints, SLA violations
- отражают уже произошедшие события
- полезны для анализа трендов
- количество инцидентов в Production за квартал
По области применения:
- Product metrics — характеризуют качество продукта (defect density)
- Process metrics — характеризуют эффективность процесса (MTTR)
- Project metrics — характеризуют выполнение плана (test execution rate)
Базовые метрики собираются напрямую из системы:
- количество строк кода (KLOC)
- количество тест-кейсов
- количество дефектов
- время выполнения тестов
Производные метрики рассчитываются на основе базовых:
- Defect Density = Defects / KLOC
- Test Pass Rate = Passed / Total × 100%
- Automation Rate = Automated Tests / Total Tests × 100%
Производные метрики более информативны, они позволяют сравнивать разные проекты
Фишка GQM: так как метрики являются результатом анализа цели, они также формулируются по SMART
- Specific — конкретная, измеряемая величина
- Measurable — возможность автоматического сбора
- Achievable — достижимые целевые значения
- Relevant — связь с бизнес-целями
- Time-bound — привязка к временным рамкам
Плохая метрика: улучшить качество тестирования (и что?). Она не конкретна, не измерима, нет временных рамок.
Хорошая метрика: достичь DDE ≥ 90% для критических дефектов к концу Q2 2026
- Specific: конкретная метрика (DDE, Defect Detection Efficiency)
- Measurable: можно посчитать автоматически
- Achievable: 90% реалистично (текущий уровень 85%)
- Relevant: критические дефекты влияют на бизнес
- Time-bound: конец Q2 2026
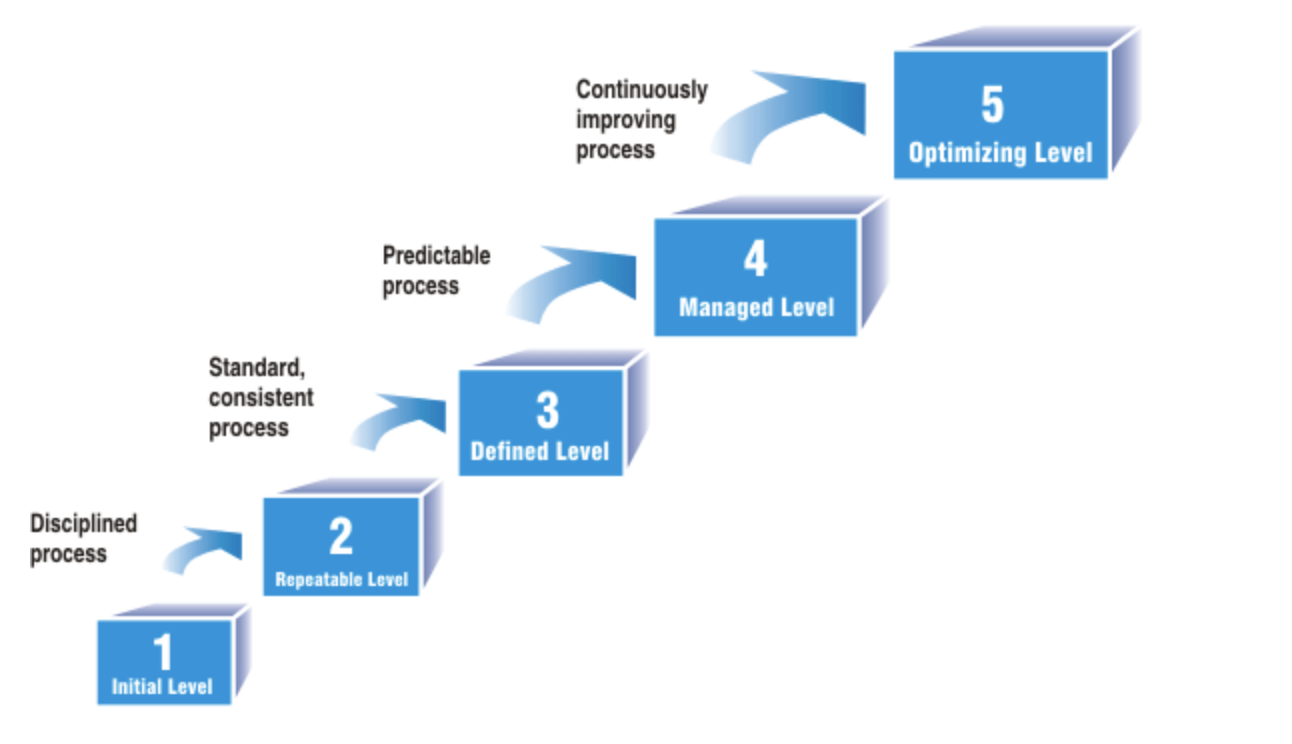
Организации проходят через уровни зрелости в работе с метриками.
1. Ad-hoc (на лету)
Метрики собираются хаотично, по запросу руководства. Нет единого понимания, что измерять.
2. Базовый
Регулярный сбор базовых метрик (количество тестов, дефектов). Ручной сбор в Excel (например).
3. Стандартизированный
Единые метрики для всех проектов. Автоматический сбор. Регулярная отчетность.
4. Управляемый
Метрики используются для принятия решений. Анализ трендов. Прогнозирование.
5. Оптимизирующий Непрерывное улучшение на основе метрик. A/B-тестирование процессов. Предиктивная аналитика.
Это и есть модель CMM, описанная ранее. В контексте процессов сбора и анализа метрик.
Основной метрикой для измерения эффективности тестирования является DDE
где:
- — дефекты, найденные до релиза
- — дефекты, обнаруженные в Production
На DDE влияют:
- полнота тестового покрытия
- качество тест-дизайна
- квалификация тестировщиков
- время, которое отводится на тестирование
¶ Покрытие требований и покрытие кода
Покрытие — одна из наиболее часто используемых метрик в тестировании. Существует фундаментальное различие между покрытием требований и покрытием кода.
Покрытие требований — процент требований, для которых существуют тест-кейсы:
где:
- — количество требований, покрытых тестами
- — общее количество требований
Покрытие требований отвечает на вопрос: все ли бизнес-требования проверены? Это метрика полноты тестирования с точки зрения заказчика. Даже если код покрыт на 100%, но пропущено критическое бизнес-требование, то продукт не готов к релизу
Уровни покрытия требований:
- базовое покрытие — для каждого требования есть хотя бы один тест-кейс
- глубокое покрытие — каждое требование покрыто позитивными и негативными сценариями
- полное покрытие — покрыты все комбинации, граничные условия, интеграционные сценарии
где:
- — фактическое количество тест-кейсов для требования
- — ожидаемое количество (определяется техниками тест-дизайна)
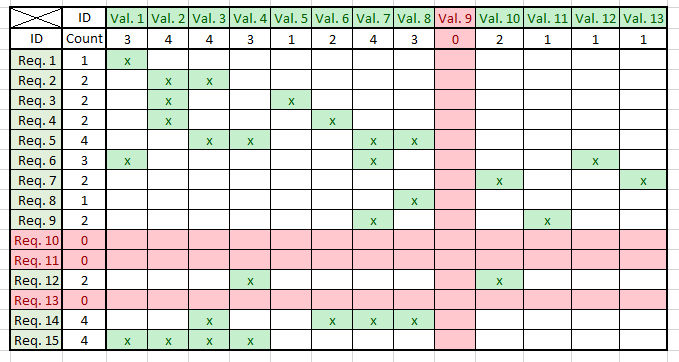
Обычно работаем с матрицами трассируемости (Traceability Matrix):
Покрытие кода отвечает на вопрос: какая часть кода была выполнена во время тестирования?. Это техническая метрика, которая помогает найти непротестированные участки кода.
Покрытие не равно качество тестов: тест может выполнить код, но не проверить корректность результата
def test_bad_coverage():
result = calculate_price(100, 0.2)
Невозможно покрыть все пути. Для кода с N условий существует до путей выполнения.
Нужно учитывать данные. Один и тот же код может работать по-разному с разными входными данными.
Увеличение покрытия с 80% до 90% требует значительно больше усилий, чем с 60% до 70%. Последние 10-15% часто покрывают редко используемый код (обработка ошибок, граничные случаи)
Высокое покрытие требований не гарантирует высокое покрытие кода и наоборот
Помните, что не все требования и не весь код одинаково важны. Риск-ориентированный подход предполагает приоритизацию тестирования на основе:
где:
- — вероятность возникновения дефекта (сложность кода, частота изменений)
- — влияние дефекта на бизнес (критичность функции, количество пользователей)
¶ Метрики дефектов и производительности
Метрики дефектов — пульс качества продукта. Они позволяют оценить текущее состояние, прогнозировать риски и измерять эффективность процессов тестирования и разработки.
Test Pass Rate (Процент успешных тестов)
где:
- — количество успешно пройденных тестов
- — общее количество выполненных тестов
Один и тот же TPR по разному интерпретируется в разных ситуациях:
- регрессионное тестирование: падение ниже 95% — сигнал тревоги
- тестирование новой функциональности: TPR 70-80% в начале итерации — нормально
- smoke-тесты: TPR должен быть 100%, любое падение — критично
Defect Density (Плотность дефектов)
где:
- — общее количество дефектов
- — размер продукта (KLOC, function points, story points)
Абсолютное число дефектов не информативно. 100 багов в проекте на 500 KLOC — отлично, в проекте на 10 KLOC — жесть
Defect Density по severity (по серьезности)
Не все дефекты равны. Один Critical баг может стоить компании миллионы, тогда как сотня Trivial багов — раздражение пользователей.
где — вес severity.
Классификация severity (IEEE 1044):
| Уровень | Описание | Пример | SLA на исправление |
|---|---|---|---|
| Critical | Система неработоспособна | Вылет при старте, потеря данных | 4-24 часа |
| Major | Основная функциональность недоступна | Невозможно оплатить заказ | 1-3 дня |
| Minor | Функциональность работает с ограничениями | Отчет генерируется медленно | 1-2 недели |
| Trivial | Косметические дефекты ("бантики") | Опечатка в интерфейсе | Backlog |
Различайте Severity и Priority
- Severity — техническая оценка влияния дефекта на систему
- Priority — бизнес-оценка срочности исправления
Опечатка в названии компании на главной странице — Trivial severity, но Critical priority для бренда.
Mean Time To Detect (Среднее время обнаружения)
где:
- — время обнаружения дефекта
- — время внесения дефекта (дата коммита)
- — количество дефектов
Mean Time To Repair/Resolve (Среднее время исправления)
где:
- — время закрытия дефекта
- — время обнаружения дефекта
- — количество дефектов
MTTR (Mean Time To Recovery/Restore) — одна из четырех ключевых метрик DORA (DevOps Research and Assessment), определяющих эффективность команды:
| Метрика | Elite | High | Medium | Low |
|---|---|---|---|---|
| MTTR | < 1 часа | < 1 дня | < 1 недели | > 1 месяца |
| Deployment Frequency | По требованию | 1/день-1/неделя | 1/неделя-1/месяц | < 1/месяц |
| Lead Time for Changes | < 1 дня | 1 день-1 неделя | 1 неделя-1 месяц | > 1 месяца |
| Change Failure Rate | 0-15% | 16-30% | 31-45% | > 45% |
Декомпозиция помогает выявить узкие места: если основное время уходит на воспроизведение, то нужно прокачивать баг-репорты; если на код-ревью, то нужно оптимизировать этот процесс
¶ Инструменты: Allure, TestRail, Xray
| Инструмент | Тип | Основное назначение |
|---|---|---|
| Allure | Reporting Framework | Визуализация результатов автотестов |
| TestRail | TMS (Test Management System) | Управление тест-кейсами и планами |
| Xray | TMS (Jira Plugin) | Интеграция тестирования в Jira |
Allure — open-source фреймворк для создания наглядных отчётов о тестировании. Разработан компанией Qameta и получил широкое распространение благодаря гибкости и качеству визуализации.
Код ниже является результатом генерации с применением LLM
import allure
import pytest
from typing import Optional
# Имитация тестируемого модуля
class Calculator:
"""Простой калькулятор для демонстрации."""
def add(self, a: float, b: float) -> float:
return a + b
def divide(self, a: float, b: float) -> float:
if b == 0:
raise ValueError("Division by zero")
return a / b
def sqrt(self, x: float) -> float:
if x < 0:
raise ValueError("Cannot calculate square root of negative number")
return x ** 0.5
# Allure позволяет группировать тесты по Epic -> Feature -> Story
@allure.epic("Calculator Module")
@allure.feature("Basic Operations")
class TestCalculatorBasic:
"""Тесты базовых операций калькулятора."""
@pytest.fixture
def calculator(self):
"""Фикстура для создания экземпляра калькулятора."""
return Calculator()
@allure.story("Addition")
@allure.severity(allure.severity_level.CRITICAL)
@allure.title("Test addition of two positive numbers")
def test_add_positive_numbers(self, calculator):
"""Проверка сложения положительных чисел."""
with allure.step("Prepare test data"):
a, b = 5, 3
expected = 8
with allure.step(f"Calculate {a} + {b}"):
result = calculator.add(a, b)
with allure.step("Verify result"):
assert result == expected, f"Expected {expected}, got {result}"
@allure.story("Addition")
@allure.severity(allure.severity_level.NORMAL)
@allure.title("Test addition with negative numbers")
@pytest.mark.parametrize("a,b,expected", [
(-5, 3, -2),
(5, -3, 2),
(-5, -3, -8),
])
def test_add_with_negatives(self, calculator, a, b, expected):
"""Параметризованный тест сложения с отрицательными числами."""
result = calculator.add(a, b)
assert result == expected
@allure.story("Division")
@allure.severity(allure.severity_level.CRITICAL)
@allure.title("Test division of two numbers")
def test_divide(self, calculator):
"""Проверка деления."""
with allure.step("Perform division 10 / 2"):
result = calculator.divide(10, 2)
with allure.step("Check result equals 5"):
assert result == 5
@allure.story("Division")
@allure.severity(allure.severity_level.BLOCKER)
@allure.title("Test division by zero raises exception")
def test_divide_by_zero(self, calculator):
"""Проверка исключения при делении на ноль."""
with allure.step("Attempt to divide by zero"):
with pytest.raises(ValueError) as exc_info:
calculator.divide(10, 0)
with allure.step("Verify error message"):
assert "Division by zero" in str(exc_info.value)
@allure.epic("Calculator Module")
@allure.feature("Advanced Operations")
class TestCalculatorAdvanced:
"""Тесты продвинутых операций."""
@pytest.fixture
def calculator(self):
return Calculator()
@allure.story("Square Root")
@allure.severity(allure.severity_level.NORMAL)
@allure.title("Test square root calculation")
def test_sqrt_positive(self, calculator):
"""Проверка извлечения квадратного корня."""
# Добавление вложений (attachments) в отчёт
test_cases = [(4, 2), (9, 3), (16, 4), (25, 5)]
allure.attach(
str(test_cases),
name="Test Cases",
attachment_type=allure.attachment_type.TEXT
)
for x, expected in test_cases:
with allure.step(f"Calculate sqrt({x})"):
result = calculator.sqrt(x)
assert result == expected, f"sqrt({x}) should be {expected}"
@allure.story("Square Root")
@allure.severity(allure.severity_level.MINOR)
@allure.title("Test square root of negative number")
@allure.issue("BUG-123", "https://jira.example.com/browse/BUG-123")
@allure.testcase("TC-456", "https://testrail.example.com/index.php?/cases/view/456")
def test_sqrt_negative_raises_error(self, calculator):
"""Проверка ошибки при отрицательном аргументе."""
with pytest.raises(ValueError) as exc_info:
calculator.sqrt(-1)
assert "negative" in str(exc_info.value).lower()
pip install allure-pytest pytest
pytest <файл> --alluredir=allure-results
npm install -g allure-commandline
allure serve allure-results
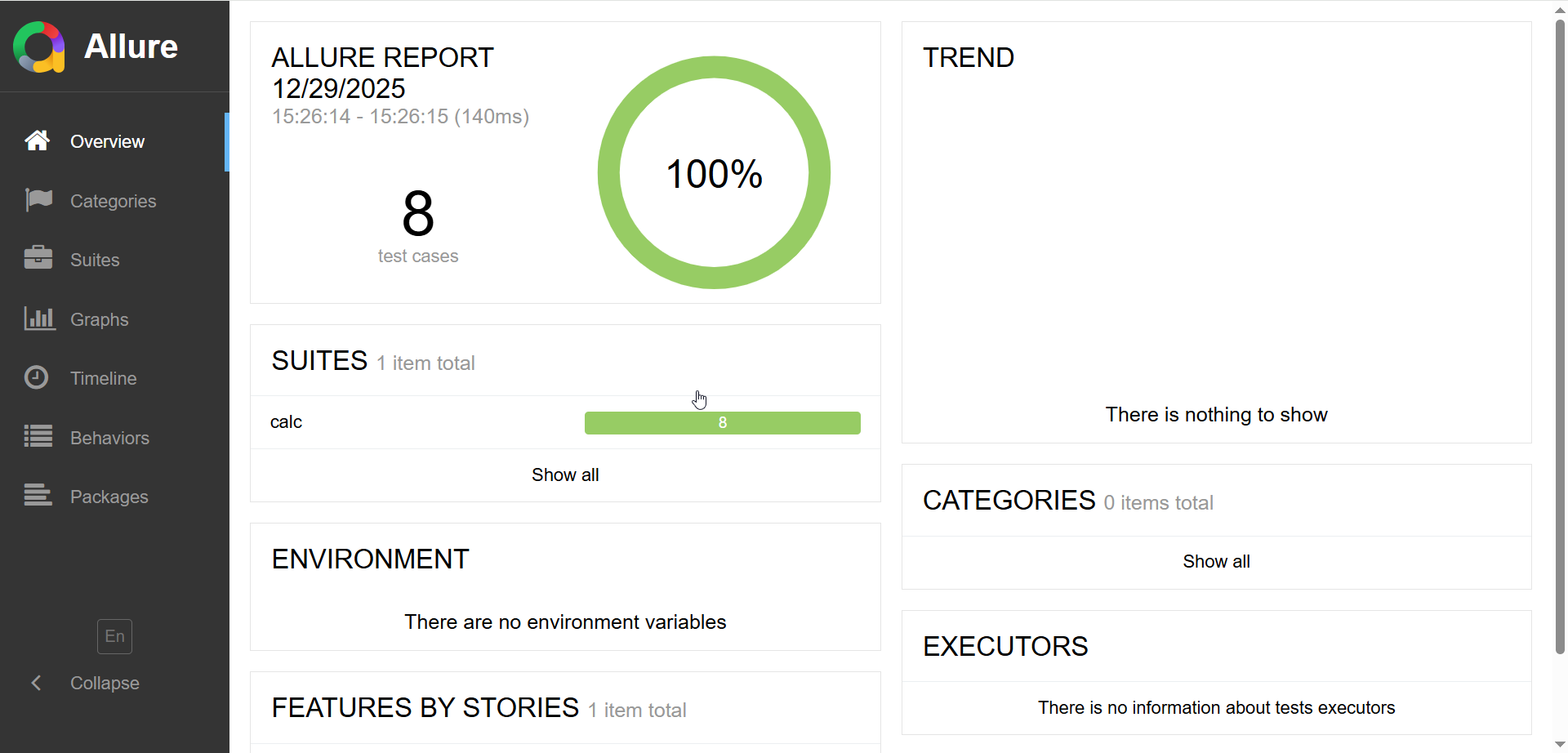
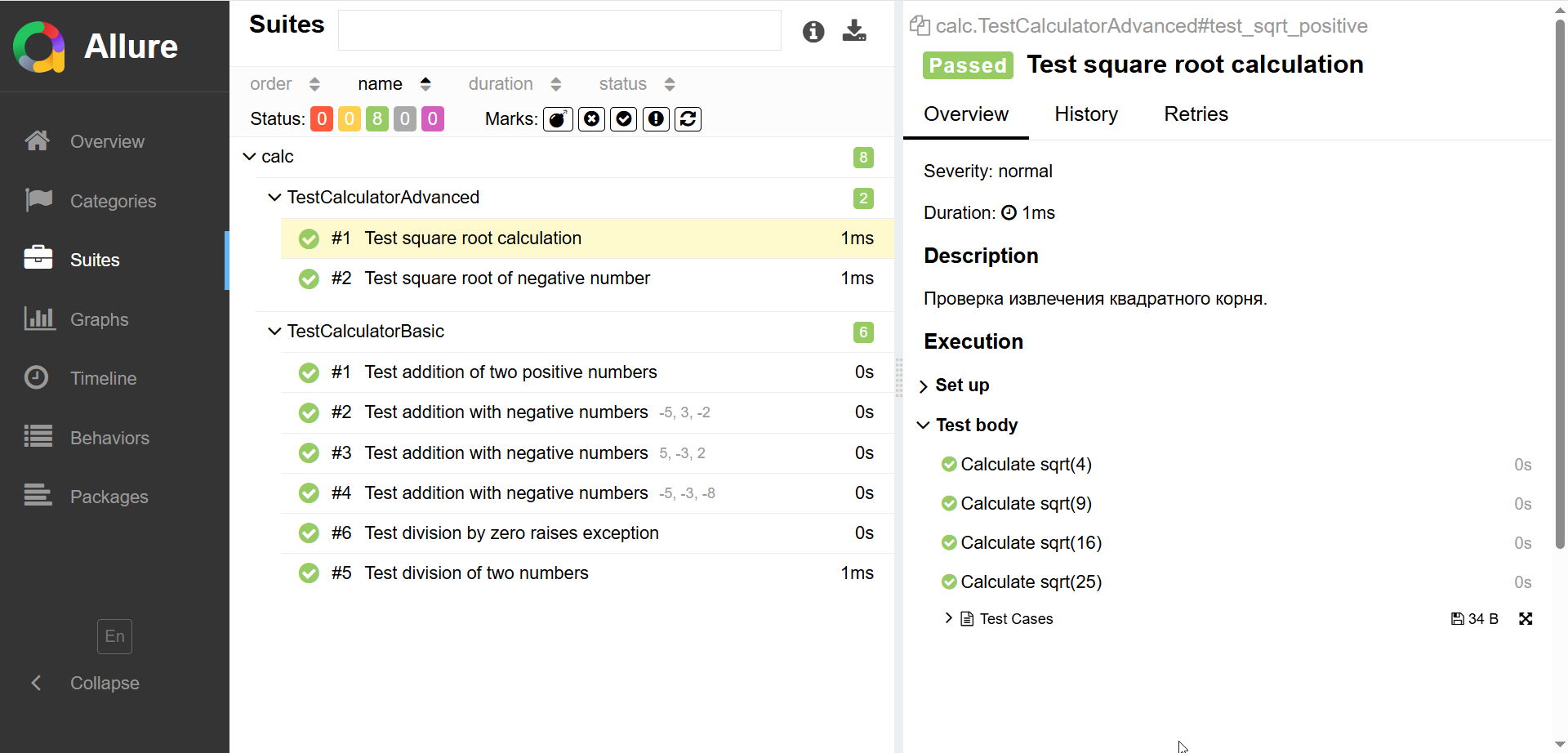
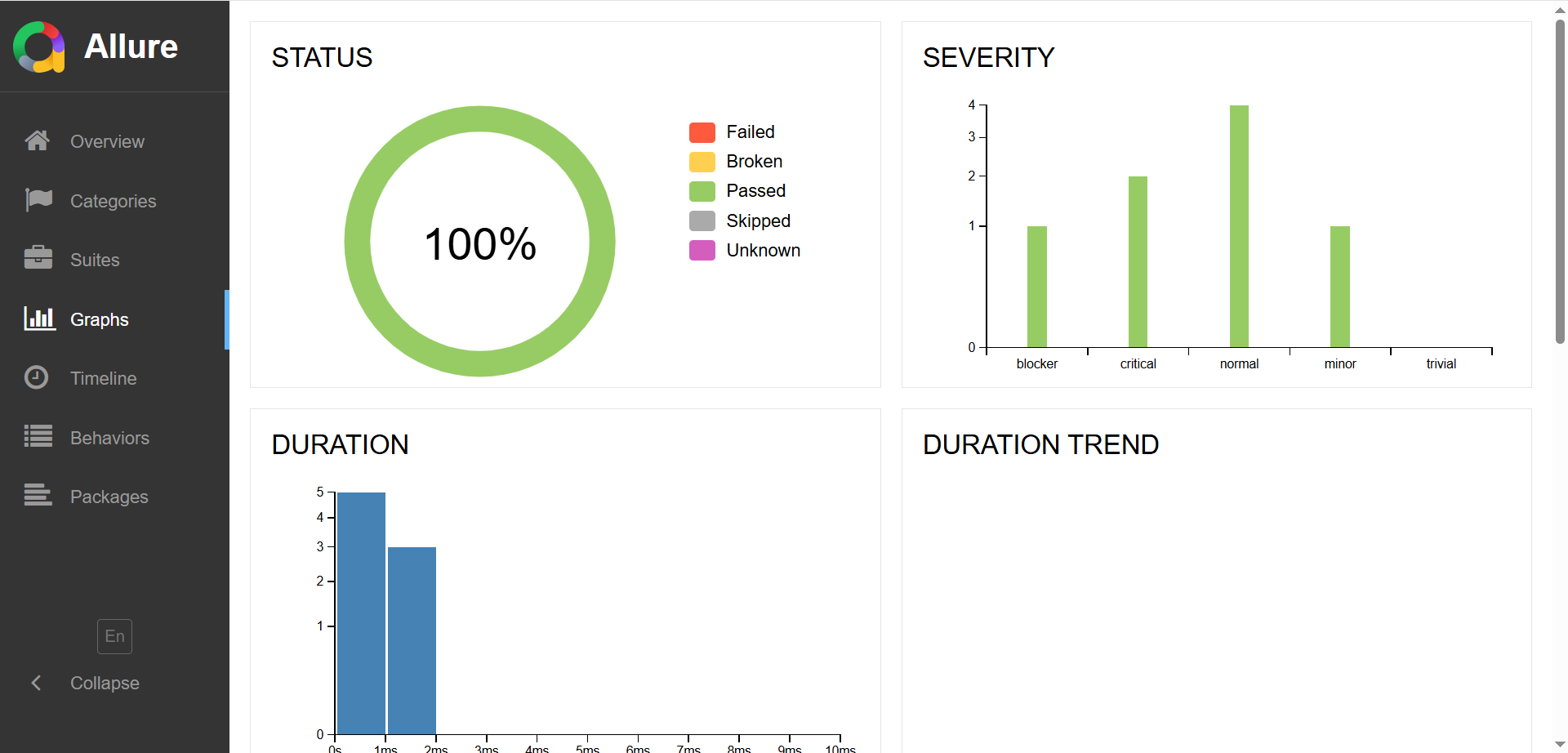
В Allure можно ссылаться задачи из Jira и тест-кейсы в TestRail
TestRail — standalone система управления тестированием (TMS). Один из наиболее зрелых и функциональных инструментов на рынке.
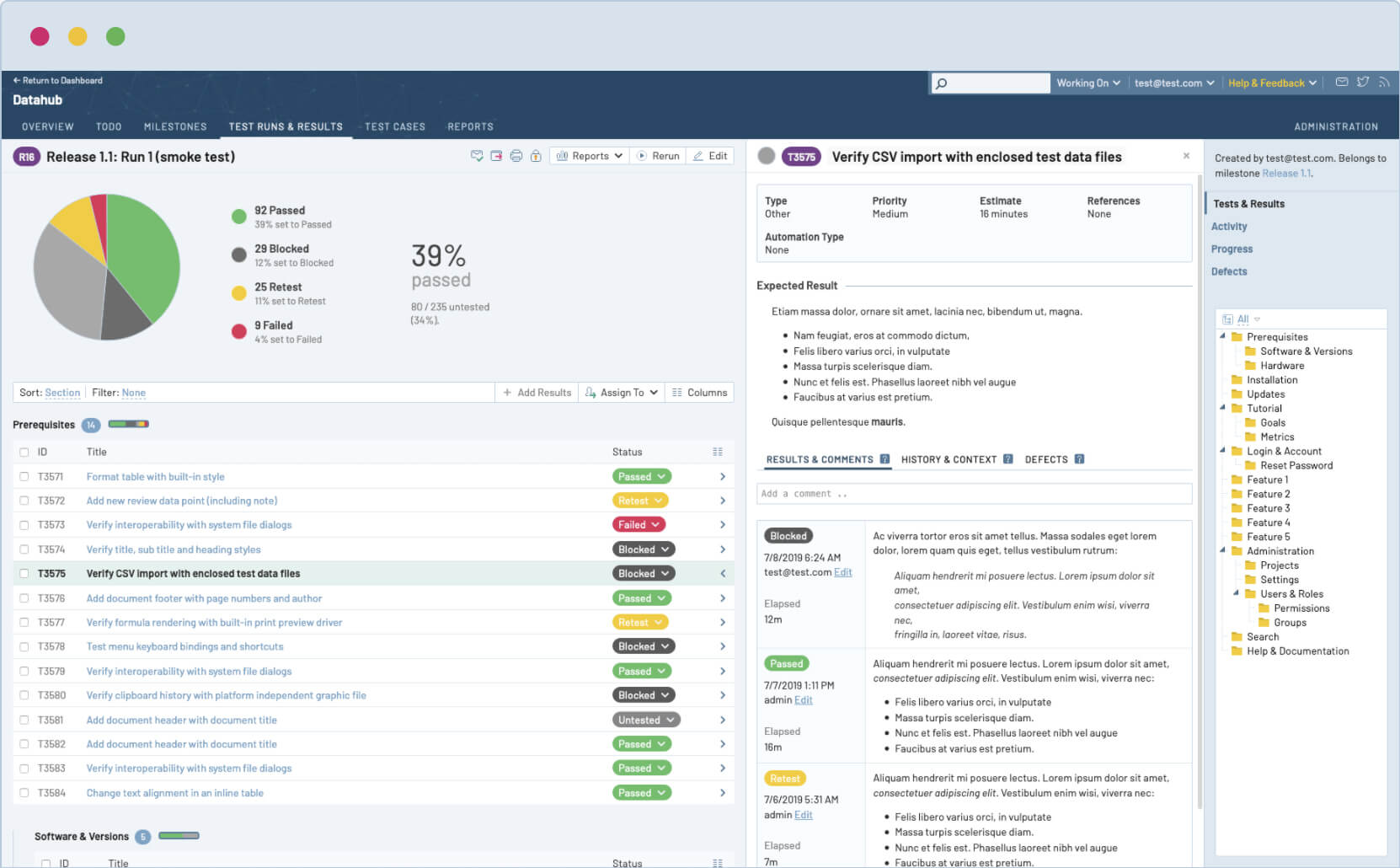
Развертывание TestRail с применением Docker (self-hosted)
Xray — плагин для Jira, превращающий ее в полноценную систему управления тестированием.
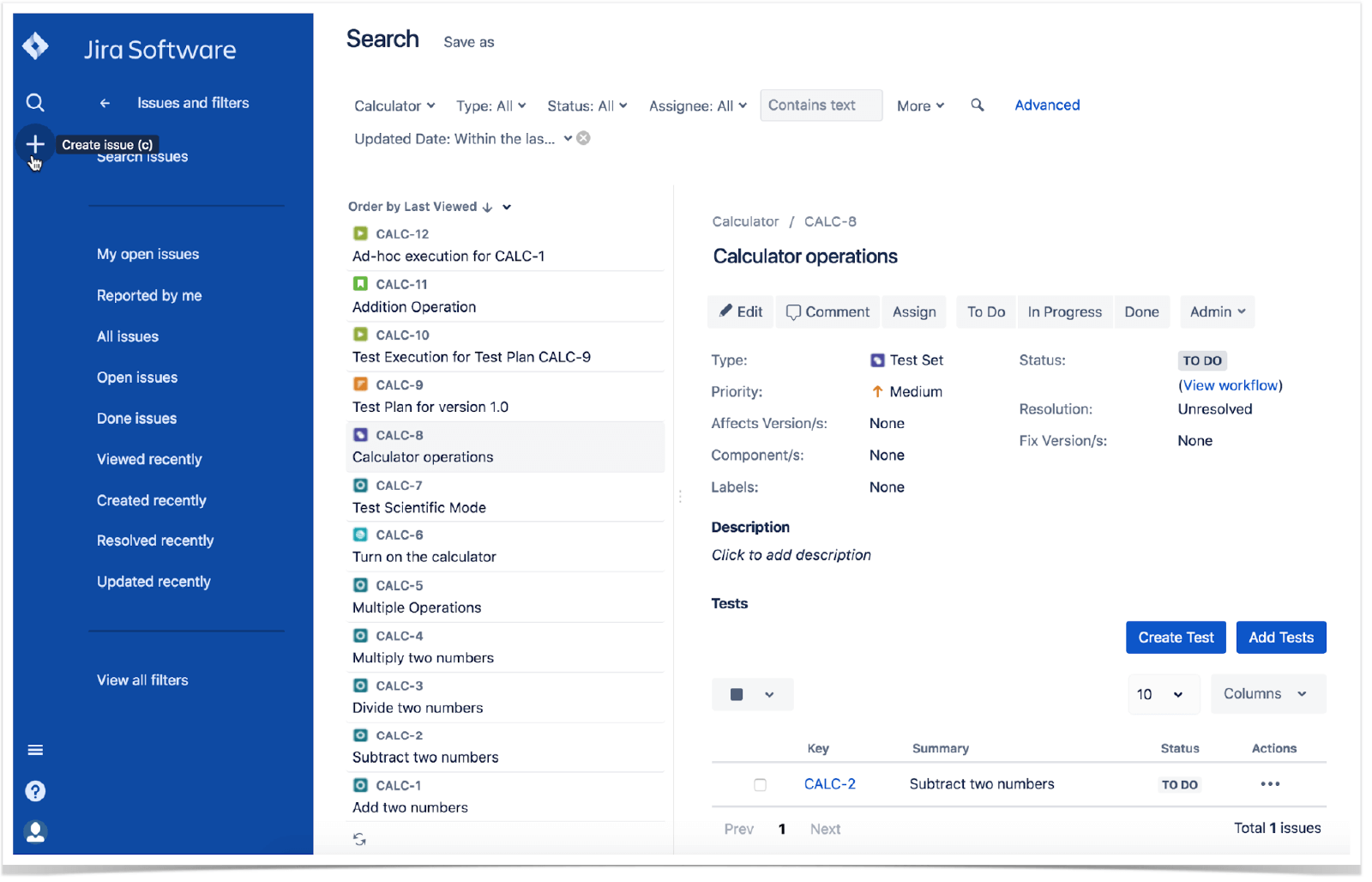
Что выбираем:
- Allure — для автоматизированного тестирования, open-source проектов
- TestRail — для enterprise, когда нужен только TMS (особенно self-hosted)
- Xray — когда команда уже использует Jira в качестве менеджера задач
¶ Заключение
Метрики — основа принятия решений в тестировании. Без измерений невозможно объективно оценить качество и прогресс.
Покрытие требований и кода — взаимодополняющие метрики. Высокое значение одной не гарантирует высокое значение другой.
MTTD и MTTR — показатели эффективности процесса. Снижение этих метрик напрямую влияет на стоимость качества.
DDE и Defect Density — показатели качества продукта
Инструменты должны выбираться под задачи команды, а не наоборот