¶ Введение
Тестирование программного обеспечения можно классифицировать по множеству аспектов.
.png)
Функциональное тестирование проверяет поведение и работоспособность системы на соответствие заранее определенным спецификациям, концентрируясь на требованиях пользователя. Его цель — найти ошибки в пользовательских сценариях при небольшом количестве одновременных пользователей. Основной результат такого тестирования бинарный: "пройдено" или "не пройдено".
Функциональные тесты отвечают на вопрос: "Выдает ли функция X результат Y при вводе Z?". Это вопрос логической корректности.
Тестирование производительности (тестирование скорости и надежности, также "нагрузочное тестирование") оценивает эффективность, стабильность и масштабируемость системы под нагрузкой, фокусируясь на ожиданиях пользователей и нефункциональных требованиях. Оно использует небольшое количество пользовательских сценариев, но с большим числом одновременных пользователей.
Нагрузочное тестирование задает другой вопрос: "Что произойдет со временем отклика функции X, когда N пользователей попытаются использовать ее одновременно?"
Это вопрос о поведении системы в условиях стресса, где результаты не являются бинарными, а существуют в контексте ожидаемой деградации производительности.
Ключевым отличием являются метрики. Функциональные тесты полагаются на утверждения (assertions), а тесты производительности сосредоточены на измеримых показателях, таких как время задержки (latency), загрузка ЦП и частота ошибок.
Тестирование производительности часто является исследовательской и статистической дисциплиной, в то время как функциональное тестирование носит более предписывающий характер. Цель состоит в понимании эксплуатационных границ системы.
¶ Спектр тестирования производительности
Нагрузочное тестирование
Фундаментальный тест на производительность. Определяет, как система ведет себя при ожидаемых нормальных и пиковых нагрузках, подтверждая, что она соответствует целям производительности, определенным в соглашениях об уровне обслуживания (Service Level Agreement, SLA). Это отправная точка для определения "удовлетворительной" производительности. Система должна прежде всего быть способна справляться с ожидаемой нагрузкой.
Стресс-тестирование (Stress Testing)
После установления базовой производительности обычно узнают пределы системы. Цель — найти точку отказа системы и наблюдать за ее устойчивостью и обработкой ошибок. Система намеренно выводится за пределы своих эксплуатационных возможностей, чтобы можно было увидеть, как и когда она выйдет из строя. Ключевым аспектом является оценка способности системы к корректному восстановлению после сбоя.
Тестирование на выносливость (Soak/Endurance Testing)
Подаем нормальную, ожидаемую нагрузку в течение длительного периода (часы или даже дни). Цель — выявить скрытые проблемы, которые проявляются только со временем (утечки памяти, истощение ресурсов, деградация производительности). Система, которая работает стабильно в течение часа, может отказать через 24 часа из-за медленных утечек ресурсов.
Спайк-тестирование (Spike Testing)
Тест имитирует внезапные и резкие скачки нагрузки. В реальном мире (распродажа 11/11) нагрузка не всегда предсказуема. Следует процерять способность системы справляться с неожиданными всплесками и также ее способность восстанавливаться до нормального уровня производительности после того, как всплеск спадет.
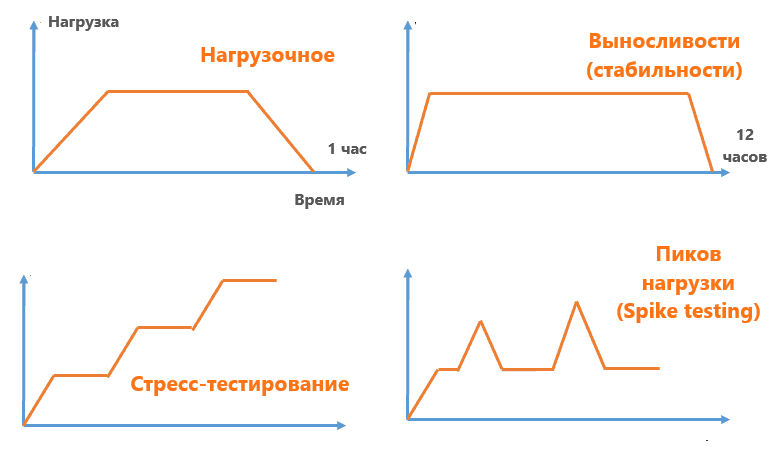
Комплексная стратегия тестирования производительности включает все эти виды тестирования для создания многомерной картины надежности системы
¶ Модель рабочей нагрузки
Модель рабочей нагрузки (workload model) — упрощенное, воспроизводимое приближение реальных сценариев использования системы. Представляет собой сочетание типов пользователей, тестовых сценариев и частоты их выполнения.
Существуют две модели появления пользователей.
Закрытая модель (Closed Model)
В системе находится фиксированное количество одновременных пользователей. Новый пользователь начинает свой сценарий только после того, как "освобождается место". Основное внимание уделяется количеству одновременных пользователей. Эта модель подходит для систем с известной, контролируемой пользовательской базой.
Открытая модель (Open Model)
Новые пользователи прибывают с определенной скоростью, независимо от того, сколько пользователей уже активно в системе. Если система замедляется, то пользователи начинают накапливаться. Это имитирует поведение приложений, когда невозможно контролировать скорость подключения пользователей.
Принципы моделирования рабочей нагрузки:
- определение профилей пользователей: необходимо сегментировать пользователей на основе их поведения ("просматривающие", "покупающие")
- определение соотношения транзакций: нужно установить примерное соотношение действий для каждого профиля (77% просто просматривают, 20% ищут, 3% покупают)
- включение времени на размышление (Think Time): целесообразно включать реалистичную задержку между действиями пользователя (чтение страницы перед кликом)
¶ Количественная оценка поведения системы
Метрики в нагрузочном тестировании – количественные показатели, которые помогают объективно оценить производительность системы и принять обоснованные решения о необходимости оптимизации.
¶ Метрики производительности для пользователей
Они напрямую влияют на удовлетворенность пользователей и на бизнес-показатели. Помогают понять, насколько комфортно пользователям работать с системой.
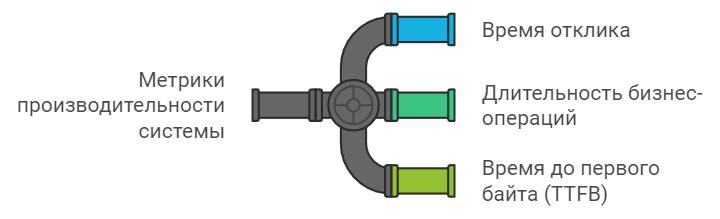
- Время отклика – время между запросом и ответом системы (для веб-магазина критично, чтобы страница товара загружалась не более 2 секунд, а оформление заказа занимало не более 5 секунд)
- Время выполнения бизнес-операций – длительность выполнения важных для бизнеса действий (полный цикл оформления заказа от добавления в корзину до подтверждения оплаты должен занимать не более 3 минут)
- Задержка первого байта (Time to first byte, TTFB) – время получения первого байта ответа от сервера (для SEO-оптимизации и удобства пользователей TTFB не должен превышать 200 мс)
¶ Метрики системной производительности
Помогают понять, насколько эффективно система использует доступные ресурсы и где могут возникнуть узкие места при увеличении нагрузки.
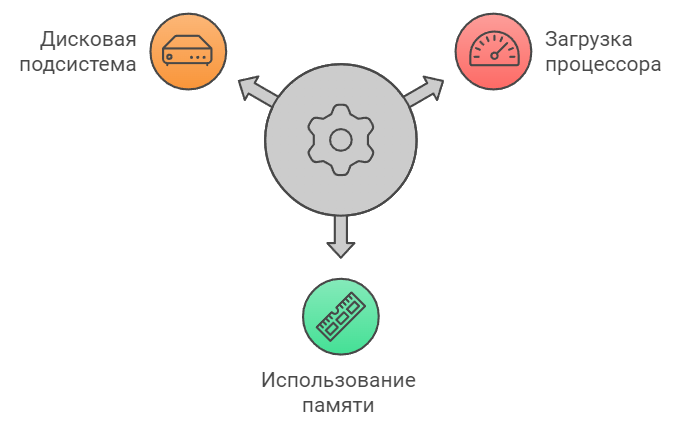
- Загрузка процессора – процент использования CPU (при пиковой нагрузке загрузка не должна превышать 80%, чтобы оставался запас для обработки внезапных всплесков)
- Использование памяти – объем используемой оперативной памяти (система не должна использовать более 70% доступной памяти)
- Использование дисковой подсистемы – скорость и объем операций ввода-вывода (время отклика дисковой подсистемы не должно превышать 20 мс)
¶ Метрики пропускной способности
Показывают, сколько операций система может обработать и как она справляется с увеличением нагрузки. Критически важны для планирования масштабирования.
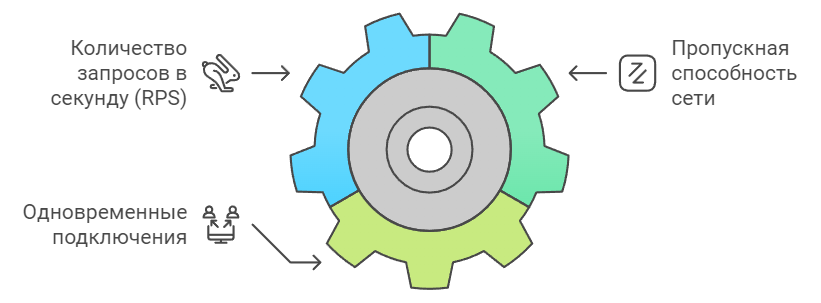
- Количество запросов в секунду (Requests per Second, RPS) – сколько запросов система обрабатывает за единицу времени (API платежной системы должен стабильно обрабатывать 1000 RPS с возможностью краткосрочных пиков до 2000 RPS)
- Пропускная способность сети – объем данных, передаваемых по сети (cистема видеостриминга должна обеспечивать передачу минимум 100 Мбит/с на каждые 1000 активных пользователей)
- Количество одновременных подключений – число активных пользовательских сессий (онлайн-платформа должна поддерживать 10 000 одновременных подключений без деградации производительности)
¶ Метрики стабильности и надежности
Помогают оценить, насколько стабильно система работает под нагрузкой и как часто возникают ошибки.
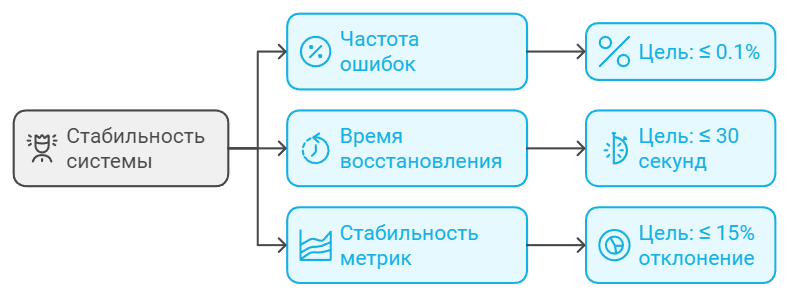
- Частота ошибок – процент неуспешных операций (в платежной системе допустимый процент ошибок не должен превышать 0.1% от общего числа транзакций)
- Время восстановления – как быстро система возвращается к нормальной работе после сбоев (система должна восстанавливать нормальную производительность в течение 30 секунд после падения нагрузки)
- Стабильность метрик – насколько стабильны основные показатели во времени (отклонение времени отклика не должно превышать 15% от среднего значения в течение суток)
При проведении нагрузочного тестирования важно не только собирать эти метрики, но и анализировать их взаимосвязь
Увеличение времени отклика может быть связано с ростом использования памяти, а увеличение частоты ошибок – с достижением предела пропускной способности сети.
Система может иметь хорошее среднее время отклика, в то время как небольшой процент пользователей испытывает экстремальные задержки.
В нагрузочном тестировании процентили — статистические показатели, которые описывают распределение времени отклика системы и позволяют оценить производительность с точки зрения пользовательского опыта более точно. Процентиль показывает, какой процент запросов выполнился быстрее определённого значения.
Процентили применяются к метрикам, измеряющим время
Если 90-й процентиль времени отклика составляет 500 миллисекунд, это означает, что 90% всех запросов к системе были обработаны за 500 мс или быстрее, а остальные 10% заняли больше времени.
В нагрузочном тестировании чаще всего анализируют следующие процентили:
- 50-й процентиль (медиана) — значение, которое делит все результаты пополам: 50% запросов были быстрее этого времени, а 50% — медленнее
- 90-й, 95-й и 99-й процентили — значения показывают время отклика для большинства пользователей, отсекая самые медленные запросы (95-й процентиль показывает время, в которое уложились 95% самых быстрых запросов)
Пример:
- 9 запросов выполнились за 100 мс.
- 1 запрос выполнился за 1100 мс.
Среднее время отклика будет (9 * 100 + 1100) / 10 = 200 мс. Это значение не отражает реальность, так как 90% пользователей получили ответ за 100 мс, а один пользователь ждал больше секунды. 90-й процентиль будет равен 100 мс, что точнее описывает опыт большинства.
¶ Закон Литтла
Формула , которая устанавливает взаимосвязь между тремя ключевыми метриками:
- средним количеством одновременных пользователей в системе
- их временем отклика
- пропускной способностью системы (RPS)
Закон позволяет анализировать и проверять корректность моделей нагрузки, а также прогнозировать поведение системы при различных условиях. Сформулировал John Little в 1954 году (позже он его и доказал), это основа для теории массового обслуживания.
Если в ходе теста зафиксировали среднюю пропускную способность и среднее время отклика , можно рассчитать теоретическое количество одновременных пользователей . Если это расчетное значение L сильно отличается от количества виртуальных пользователей, заданного в тесте, это может указывать на проблемы в инструменте тестирования, в самой системе или на то, что система работает не в стабильном режиме.
Если нужно достичь определенного времени отклика при ожидаемой нагрузке , можно рассчитать, сколько одновременных сессий система должна будет выдерживать.
Формула оперирует средними значениями за длительный период. Она не предназначена для анализа мгновенных показателей
¶ Locust
Две ключевые особенности.
Тестирование как код (Test as Code)
Философия Locust заключается в определении поведения пользователя в коде на Python (без пользовательских интерфейсов, JSON, XML). Это делает тесты гибкими, настраиваемыми и легко версионируемыми.
Событийно-ориентированная архитектура (gevent)
Locust использует gevent, библиотеку для сетевого программирования на основе корутин. Каждый смоделированный пользователь работает в своем легковесной корутине (greenlet).
Многие инструменты (JMeter) используют один поток операционной системы на каждого смоделированного пользователя. Потоки имеют значительные накладные расходы на память и переключение контекста, что ограничивает количество пользователей, которое может сгенерировать одна машина.
Locust использует gevent, который применяет цикл событий (event loop) и неблокирующий ввод-вывод. Greenlet (легковесная корутина) уступает управление во время ожидания ответа, позволяя другому greenlet'у выполняться. Такая модель кооперативной многозадачности позволяет одному процессу ОС управлять тысячами одновременных пользователей, поскольку большую часть времени они проводят в "ожидании" ввода-вывода, а не потребляют ресурсы ЦП.
Пример.
import random
from locust import HttpUser, task, between
class EcommerceUser(HttpUser):
# пользователи будут ждать от 1 до 3 секунд между выполнением задач
wait_time = between(1, 3)
# эта переменная будет хранить токен аутентификации для сессии пользователя
auth_token = None
# список ID продуктов, которые могут быть просмотрены или добавлены в корзину
product_ids = []
def on_start(self):
"""
Выполняется один раз для каждого смоделированного пользователя при его запуске,
используется для входа в систему и получения токена аутентификации
"""
response = self.client.post("/api/auth/login", json={
"username": "hypeuser",
"password": "kafedrahaypa"
})
if response.status_code == 200:
self.auth_token = response.json().get("token")
# устанавливаем заголовок авторизации для всех последующих запросов
self.client.headers['Authorization'] = f'Bearer {self.auth_token}'
else:
print("Не удалось войти (в IT)")
@task(5)
def browse_products(self):
"""
Задача с более высоким весом (5). Моделирует просмотр списка продуктов.
Эта задача будет выбираться в 5 раз чаще, чем 'add_to_cart'.
"""
self.client.get("/api/products", name="/api/products (browse)")
@task(1)
def add_to_cart(self):
"""
Задача с более низким весом (1). Моделирует добавление случайного продукта в корзину
"""
if not self.auth_token:
# если пользователь не аутентифицирован, пропускаем задачу
return
# выбираем случайный продукт из списка
product_id = random.choice(self.product_ids)
# отправляем POST-запрос для добавления продукта в корзину.
self.client.post("/api/cart", json={
"productId": product_id,
"quantity": 1
}, name="/api/cart (add)")
def on_stop(self):
"""
Выполняется один раз для каждого смоделированного пользователя при его остановке.
Может использоваться для очистки (выхода из системы)
"""
if self.auth_token:
# выход из системы
self.client.post("/api/auth/logout")
print("Пользователь завершил сессию.")
Locust запускается из командной строки командой locust -f test.py, после чего веб-интерфейс становится доступен по адресу http://localhost:8089.
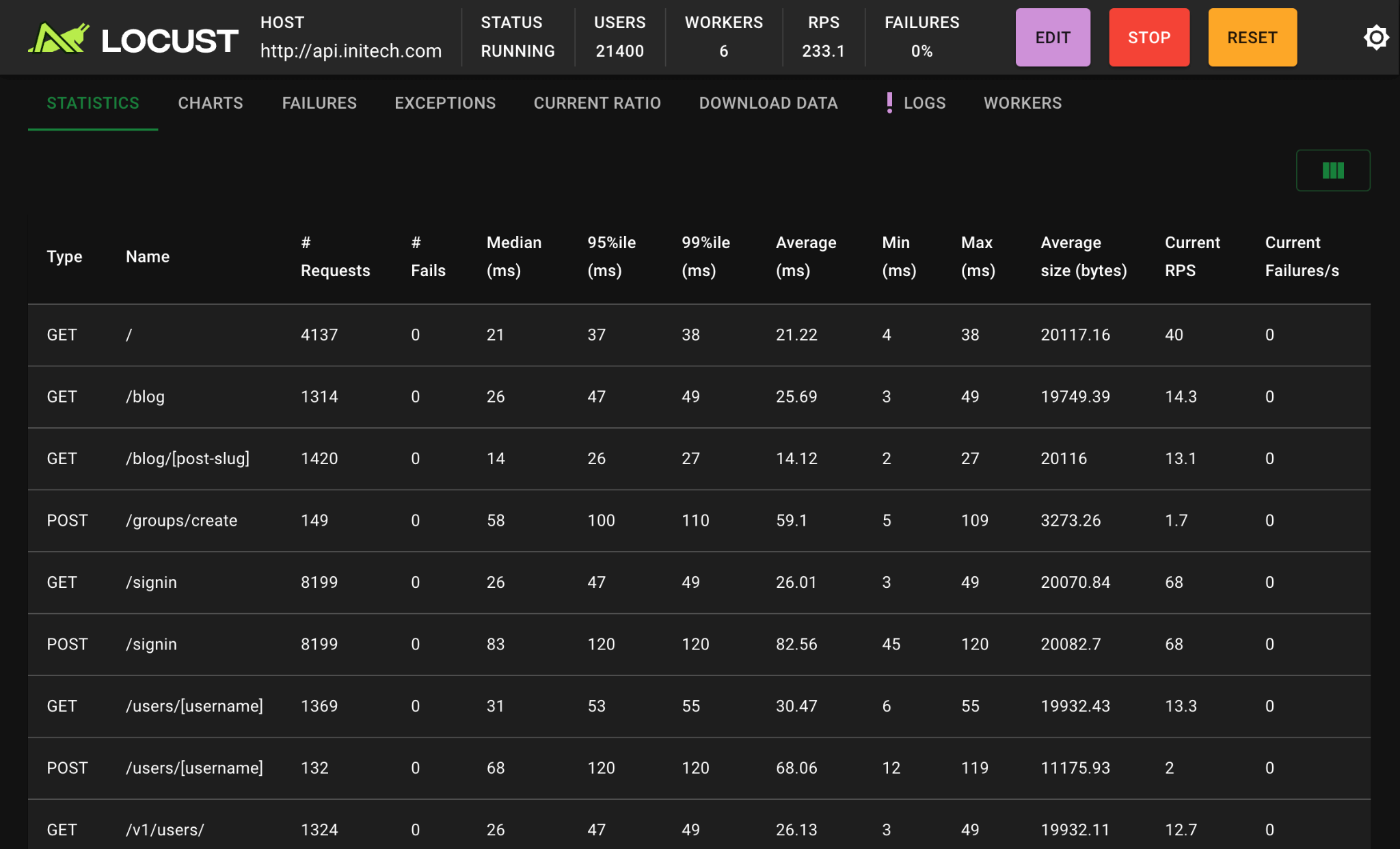
¶ K6
Две ключевые особенности.
Ориентация на разработчиков
Разработан для разработчиков и использует JavaScript для написания сценариев.
Backend на Go
Ядро инструмента написано на Go, известном высокой производительностью и эффективной поддержкой параллелизма. Сценарии на JavaScript выполняются во встроенном интерпретаторе Goja, а не в Node.js или браузере.
Пример.
import http from 'k6/http';
import { check, sleep } from 'k6';
// объект 'options' является центральным для конфигурации теста в K6.
export const options = {
// 'scenarios' позволяют определять сложные модели нагрузки.
scenarios: {
stress_test: {
// 'executor' определяет, как будут распределяться VU (виртуальные пользователи) и итерации.
// 'ramping-vus' идеально подходит для стресс-тестов, так как позволяет
// плавно увеличивать и уменьшать количество пользователей.
executor: 'ramping-vus',
startVUs: 0, // начинаем с 0 виртуальных пользователей.
stages: [
// плавное увеличение до 100 пользователей за 30 секунд.
{ duration: '30s', target: 100 },
// удержание нагрузки в 100 пользователей в течение 1 минуты для стабилизации
{ duration: '1m', target: 100 },
// плавное снижение до 0 пользователей за 15 секунд
{ duration: '15s', target: 0 },
],
},
},
// 'thresholds' определяют критерии успеха/неудачи теста (Pass/Fail).
// особенность K6 для автоматизации в CI
thresholds: {
// 95% всех HTTP-запросов должны завершаться менее чем за 800 миллисекунд.
'http_req_duration': ['p(95)<800'],
// коэффициент ошибок (неудачных запросов) должен быть менее 1%.
'http_req_failed': ['rate<0.01'],
// более 99% проверок (checks) должны проходить успешно.
'checks': ['rate>0.99'],
},
};
// 'default' функция - основной код, который выполняется каждым VU в цикле
export default function () {
const res = http.get('https://api.pmifi.ru/zdes-nichego-net-no-prikolno');
// 'check' используется для утверждений (assertions)
// неудачные проверки не прерывают тест
check(res, {
'статус ответа 200': (r) => r.status === 200,
'ответ содержит данные': (r) => r.body.length > 0,
});
// 'sleep' имитирует время на размышление пользователя
sleep(1);
}
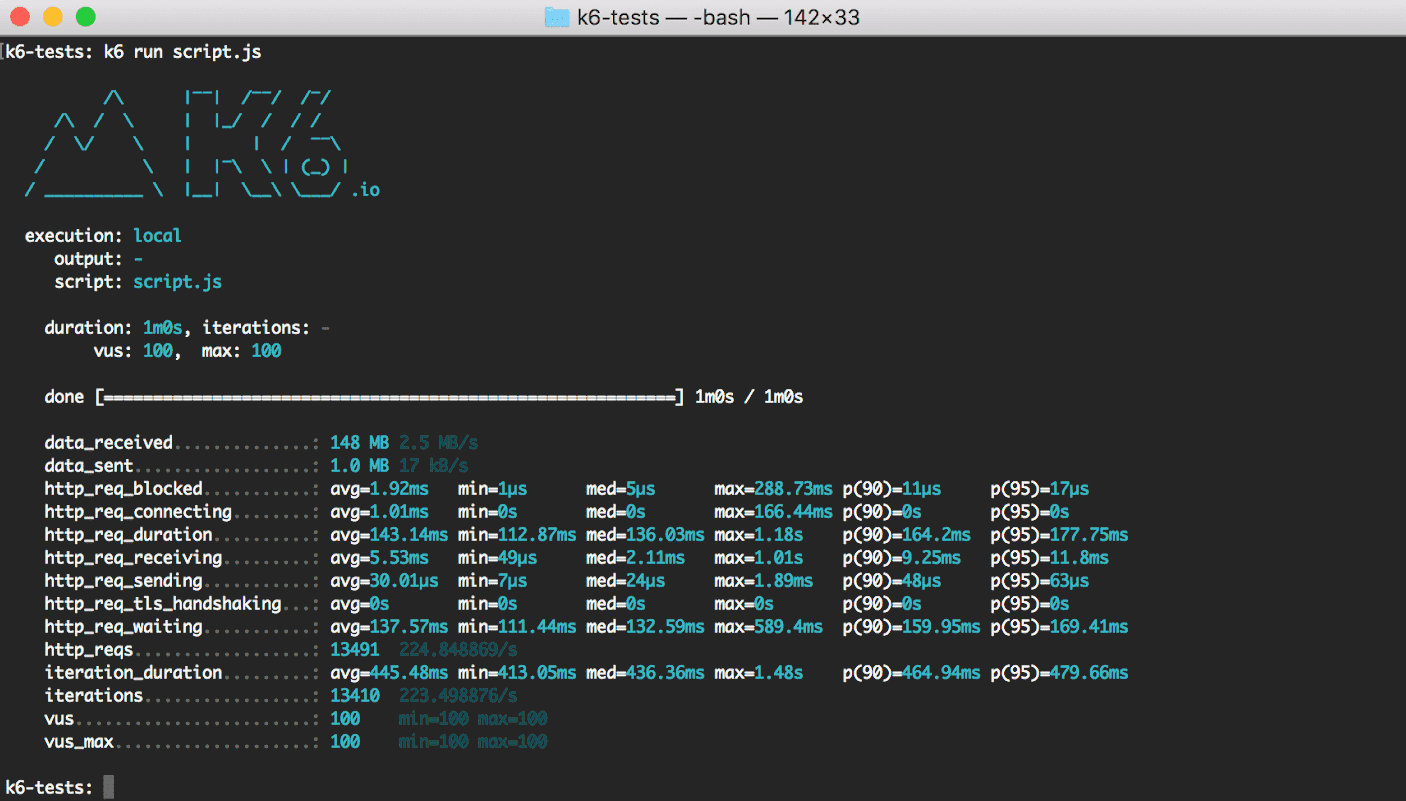
Тест запускается из командной строки: k6 run test.js. По завершении теста K6 выводит сводку.
| Характеристика | Locust | K6 |
|---|---|---|
| Язык сценариев | Python | JavaScript |
| Архитектура ядра | Python с gevent (на основе корутин) | Среда выполнения Go со встроенным интерпретатором JS |
| Модель параллелизма | Событийно-ориентированная, неблокирующий ввод-вывод | Высокопроизводительный, компилируемый Backend |
| Простота использования | Веб-интерфейс | CLI |
| Ключевые особенности | Высокая кастомизация (экосистема Python) | Встроенные пороги (pass/fail) |
| Интеграция с CI/CD | Требует кастомных скриптов для логики pass/fail | Встроенные пороги обеспечивают работу логики pass/fail для пайплайнов |
| Отчетность | Веб-интерфейс в реальном времени, экспорт в CSV, плагины | Детальная сводка в CLI, вывод в JSON/CSV, интеграция с Grafana/InfluxDB |
| Предпочтительные сценарии | Команды с сильной экспертизой в Python, сложная логика тестов, требующая библиотек Python | Кросс-стековые команды, DevOps-среды, автоматизированный контроль производительности в CI |
¶ Заключение
Тестирование производительности является неотъемлемой частью современной разработки программного обеспечения, направленной на обеспечение надежности и качества пользовательского опыта.
Выбор типа теста (стресс, на выносливость, спайк) зависит от конкретного вопроса, на который команда пытается ответить.
Основа тестирования — реалистичная модель рабочей нагрузки