¶ Введение
Одной из главных проблем в обсуждении стратегий тестирования является неоднозначность терминологии. Уже знаем, что понятие "модульный тест" может трактоваться по-разному в разных командах.
"Интеграционный тест" определяется как проверка корректной работы независимо разработанных модулей при их соединении. Однако это определение слишком широкое. Необходимо различать узкоспециализированные интеграционные тесты (сервис и его база данных) и широкомасштабные, которые по своему охвату приближаются к E2E-тестам.
Далее будет считаться, что:
- Модульный тест (Unit Test): тест, проверяющий один компонент (класс, модуль) в полной изоляции от его зависимостей, которые заменяются мок-объектами (заглушками)
- Интеграционный тест (Integration Test): тест, проверяющий взаимодействие между двумя или более реальными компонентами системы (взаимодействие сервиса с реальной базой данных, вызов одного сервиса другим через API, отправка сообщения в реальную очередь сообщений)
- Сквозной тест (End-to-End Test): тест, который валидирует полный бизнес-сценарий или путь пользователя через всю развернутую систему, включая взаимодействие с пользовательским интерфейсом
Интеграционное тестирование называют также тестированием архитектуры системы. Название обусловлено тем, что интеграционные тесты включают в себя проверки всех возможных видов взаимодействий между программными модулями и элементами, которые определяются в архитектуре системы - проверяют полноту взаимодействий в тестируемой реализации системы. Также результаты выполнения интеграционных тестов - один из основных источников информации для процесса улучшения и уточнения архитектуры системы, межмодульных и межкомпонентных интерфейсов. Интеграционные тесты проверяют корректность взаимодействия компонент системы.
Примером проверки корректности взаимодействия могут служить два модуля, один из которых накапливает сообщения протокола о принятых файлах, а второй выводит этот протокол на экран. В функциональных требованиях к системе записано, что сообщения должны выводиться в обратном хронологическом порядке. Однако, модуль хранения сообщений сохраняет их в прямом порядке, а модуль вывода использует стек для вывода в обратном порядке.
Если протестируем каждый модуль по отдельности, то все корректно:
- модуль хранения работает — он сохраняет сообщения в нужном порядке
- модуль вывода работает — он умеет печатать список сообщений в обратном порядке, если ему их передать
Но возможна обратная ошибка:
- модуль хранения вдруг начнёт сохранять в обратном порядке
- модуль вывода вместо стека начнёт пользоваться простой очередью
Локальная проверка поведения модуля не всегда гарантирует правильность поведения всей системы
Цель интеграционного тестирования — обнаружение дефектов, возникающих в интерфейсах между компонентами. Модульные тесты не способны выявить такие проблемы. К ошибкам взаимодействия относят:
- проблемы с потоками данных между модулями
- несоответствие форматов данных или протоколов связи (например, в API)
- ошибки в схеме базы данных или некорректное использование ORM
- неправильная обработка исключений, возникающих при взаимодействии компонентов
Основной причиной необходимости интеграционного тестирования является связанность (coupling) — степень взаимозависимости между программными модулями. Высокая связанность усложняет тестирование, поддержку и модификацию системы. Интеграционные тесты являются основным инструментом для проверки того, что связи между компонентами ведут себя в соответствии со спецификациями.
Интеграционное тестирование можно рассматривать как ключевую практику управления рисками, связанными со связанностью в архитектуре программного обеспечения
¶ Стратегии интеграции компонентов
Выбор способа объединения и тестирования компонентов системы является ключевым решением, которое определяет эффективность всего процесса интеграционного тестирования. Существуют различные стратегии, от простейшей "все сразу" до более сложных инкрементальных подходов. Каждая из них имеет свои компромиссы и требует использования специальных тестовых двойников — заглушек (stubs) и драйверов (drivers).
Драйверы — программы, которые вызывают тестируемый модуль
¶ Большой взрыв
"большой взрыв" (Big Bang) — самая простая и интуитивно понятная стратегия. Все модули разрабатываются независимо, а затем объединяются в единую систему и тестируются одновременно как единое целое. Этот подход наиболее применим для очень маленьких систем. Его главное преимущество заключается в том, что все компоненты тестируются во взаимодействии, что может сэкономить время, если система сразу заработает без ошибок.
Основной недостаток — чрезвычайная сложность локализации ошибок. Если тест проваливается, причина может быть в любом из десятков интегрированных модулей или в любом из их многочисленных интерфейсов.
Считается антипаттерном для любых систем сложнее тривиальных и служит отправной точкой для понимания необходимости применения более структурированных, инкрементальных подходов
Говорят, что такой метод собирает все потенциальные проблемы и заставляет их проявиться одновременно
¶ Инкрементальные стратегии
Инкрементальные стратегии предполагают постепенное добавление модулей в систему и тестирование после каждого шага. Это позволяет локализовать ошибки на ранних этапах.
¶ Нисходящая интеграция (Top-Down Integration)
Начинается с тестирования модулей верхнего уровня иерархии системы (пользовательского интерфейса или основной бизнес-логики) и постепенно движется вниз. Поскольку на начальных этапах нижележащие модули еще не готовы, их функциональность имитируется с помощью заглушек.
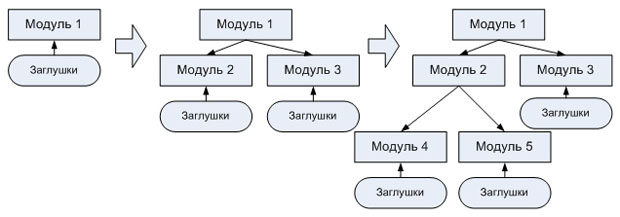
Процесс нисходящей интеграции выглядит следующим образом:
- определяются модули верхнего уровня
- для всех вызываемых ими, но еще не реализованных модулей создаются заглушки
- тестируется логика верхнего уровня с использованием этих заглушек
- по мере готовности реальных модулей они постепенно заменяют соответствующие заглушки, и тесты повторяются
Основное преимущество подхода — ранняя проверка ключевых бизнес-сценариев и архитектурной целостности системы. Создание сложных заглушек, которые адекватно имитируют поведение реальных компонентов, может быть трудоемким. Всегда существует риск, что поведение заглушки будет отличаться от поведения реального модуля, что приведет к ложным результатам тестов.
Тестирование критически важной низкоуровневой функциональности откладывается на поздние этапы цикла разработки
¶ Восходящая интеграция (Bottom-Up Integration)
Является противоположностью нисходящей. Процесс начинается с тестирования самых низкоуровневых модулей (например, библиотек утилит, слоев доступа к данным) и движется вверх по иерархии. Поскольку на начальных этапах вышестоящие модули еще не существуют, для их имитации используются драйверы.
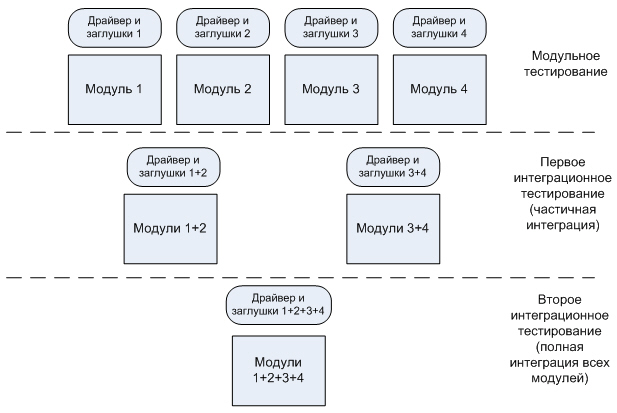
Процесс восходящей интеграции включает следующие шаги:
- низкоуровневые модули проходят модульное тестирование
- для их вызова разрабатываются драйверы
- модули объединяются в кластеры или подсистемы и тестируются с помощью драйверов
- по мере готовности вышестоящих модулей они заменяют драйверы, и процесс повторяется на следующем уровне иерархии
Подход гарантирует, что фундаментальные компоненты системы надежны и работают корректно, прежде чем на их основе будет строиться более сложная логика. Локализация ошибок проще, чем при нисходящем подходе.
Система как единое целое не существует до самого конца процесса
¶ Гибридная «сендвич» интеграция (Sandwich Integration)
Система делится на три слоя: верхний (уровень представления), средний (бизнес-логика) и нижний (уровень доступа к данным). Тестирование начинается параллельно с верхнего и нижнего слоев. Нисходящее тестирование движется сверху вниз, используя заглушки для имитации среднего слоя. Восходящее тестирование движется снизу вверх, используя драйверы для имитации среднего слоя. Финальная интеграция и тестирование происходят на среднем слое, где оба процесса встречаются.
Требует значительной координации между командами и разработки как заглушек, так и драйверов
¶ Замечания
Проект со стабильной моделью данных, но быстро меняющимся UI выиграет от восходящего подхода. Проект, ориентированный на быструю проверку новой концепции пользовательского опыта с неопределенным бэкендом, предпочтет нисходящий подход.
Гибридная стратегия является естественным выбором для крупных организаций с выделенными командами, работающими параллельно.
Заглушки и драйверы представляют собой форму временного технического долга. Это код, который нужно написать, поддерживать и выбросить. Сложная заглушка, идеально имитирующая реальную базу данных, сама по себе является значительной инженерной задачей.
Проект, который долгое время полагается на сложные заглушки, накапливает риск того, что их поведение разойдется с поведением реальных компонентов
Ключевым показателем здоровья проекта может быть "время жизни" или "сложность" его тестовых двойников: целью всегда должна быть их скорейшая замена реальными компонентами для погашения технического долга
¶ Состояние, согласованность и изоляция
¶ Миграции
Один из самых сложных аспектов интеграционного тестирования — работа с системами, хранящими состояние, в первую очередь с базами данных.
В приложениях схема базы данных не является статичной; она эволюционирует вместе с кодом с помощью системы миграций. Тестирование миграций — критически, но часто упускаемый из виду аспект интеграционного тестирования. Это форма мета-тестирования, которая проверяет не логику приложения, а структурную целостность процесса эволюции базы данных.
Alembic является стандартом для управления миграциями в экосистеме SQLAlchemy. Плагин pytest-alembic позволяет автоматизировать тестирование истории миграций. Ключевой практикой является запуск тестов на реальной базе данных (например, в Docker-контейнере), а не на in-memory SQLite, поскольку последняя может не поддерживать все возможности (специфичные для PostgreSQL типы данных или ограничения) производственной СУБД. Тесты должны проверять, что все миграции могут быть успешно применены от начального состояния до последней версии и корректно отменены обратно до базовой.
¶ Посевы
Заполнение базы данных релевантными данными — необходимое условие для осмысленных интеграционных тестов.
Ручные скрипты и фикстуры: вставляют заранее определенные данные (например, из SQL-файлов или JSON) перед запуском тестов; подход хорошо подходит для простого, статического справочного контента
Фабрики (Factories): существуют библиотеки (factory_boy для Python), которые позволяют декларативно определять фабрики для моделей данных
¶ Техники очистки
Чтобы тесты были независимыми друг от друга, состояние базы данных должно сбрасываться до исходного состояния после каждого теста. Существуют две основные стратегии для достижения этой цели:
- откат транзакций (Transaction Rollback)
- усечение таблиц (Table Truncation)
| Критерий | Откат транзакций (Transaction Rollback) | Усечение таблиц (Table Truncation) | Пересоздание БД (Database Re-creation) |
|---|---|---|---|
| Механизм | Оборачивает тест в транзакцию и выполняет ROLLBACK в конце |
Выполняет команду TRUNCATE для указанных таблиц. |
Удаляет и заново создает всю базу данных или схему |
| Производительность (PostgreSQL) | Очень высокая (константное время, O(1)) | Высокая (пропорционально количеству таблиц, O(N)) | Очень низкая |
| Производительность (Общая для РСУБД) | Варьируется; в некоторых системах зависит от объема измененных данных | Обычно быстрее, чем DELETE, но медленнее ROLLBACK в PG |
Всегда самый медленный вариант |
| Уровень изоляции | Отличный | Хороший, но могут быть проблемы с DDL-операциями или сбросом последовательностей (sequences) | Отличный |
| Ключевое ограничение | Не работает, если тестируемый код сам управляет транзакциями (выполняет COMMIT) |
Может быть медленнее отката | Высокие накладные расходы, делает частые запуски непрактичными |
¶ Паттерны интеграции для асинхронных архитектур
Современные распределенные системы часто полагаются на асинхронное взаимодействие через очереди задач и брокеры сообщений.
Стандартные фреймворки для тестирования требуют расширений (pytest-asyncio для Python), чтобы корректно управлять циклом событий и обрабатывать await-выражения.
Основная проблема заключается в том, чтобы надежно определить, когда асинхронная операция завершилась и ее побочные эффекты готовы для проверки
Тестирование задач Celery требует иного подхода, чем тестирование синхронных функций. Логику внутри самой задачи можно и нужно тестировать как обычную функцию, изолируя ее от внешних зависимостей с помощью мок-объектов. Это проверяет корректность алгоритма задачи.
Настройка
task_always_eager=True, которая заставляет задачи выполняться локально и синхронно в том же процессе, является лишь эмуляцией и не подходит для настоящего интеграционного тестирования
Для полноценного интеграционного тестирования используется плагин pytest-celery. Он предоставляет фикстуры, такие как celery_app и celery_worker, которые запускают легковесный воркер в отдельном потоке на время выполнения теста. Это позволяет тесту отправить задачу асинхронно, затем дождаться и получить ее результат.
Ключевое различие здесь — между тестированием логики задачи (модульный тест) и тестированием ее поведения как распределенного компонента (интеграционный тест)
Для систем, использующих брокеры сообщений, напрямую интеграционные тесты должны проверять корректность всего цикла жизни сообщения. Это включает:
- проверку того, что
producerотправляет сообщение в правильныйexchangeс вернымrouting key(или просто в правильнуюqueue) - проверку того, что
consumerполучает сообщение из правильнойqueue, корректно его обрабатывает и подтверждает получение
Распространенным паттерном для тестирования потребителя является запуск его в отдельном потоке. Основной поток теста публикует сообщение в очередь и после этого проверяет, что потребитель его обработал. Проверка осуществляется через наблюдение за побочными эффектами — появлением записи в базе данных, вызовом внешнего сервиса, записью в логи. Тестовое окружение требует запущенного экземпляра экземпляра брокера, который удобно управлять с помощью Docker.
В синхронном тестировании используется паттерн Arrange-Act-Assert, где проверка касается возвращаемого значения. В асинхронной ситуации Act — отправка сообщения, а Assert — не анализ прямого ответа, а наблюдение за изменением состояния системы, которое происходит позже во времени.
¶ Использование мок-объектов
Основное предназначение мок-объектов — изоляция тестируемого компонента для модульного тестирования. Когда моки начинают активно использоваться в интеграционных тестах для замены реальных внутренних компонентов системы (мокирование репозитория базы данных в тесте для сервиса), возникает парадокс: тест перестает проверять интеграцию.
Он проверяет взаимодействие кода с моком — вымышленной, идеализированной реализацией, которая может не иметь ничего общего с реальным поведением компонента.
Ключевая ошибка здесь — мокирование того, что находится под контролем. Если команда отвечает и за Сервис А, и за Сервис Б, то интеграционный тест должен запускать реальные экземпляры обоих
Правильное использование моков в интеграционном контексте заключается в симуляции компонентов, которые действительно являются внешними. К таким компонентам относятся:
- сторонние API: платежные шлюзы, сервисы доставки, социальные сети
- устаревшие системы: сложно или невозможно поднять в тестовом окружении
- сервисы других команд: если сервисы, разрабатываемые другими командами, нестабильны или недоступны в тестовом контуре
¶ Управление тестовым окружением
Интеграционное тестирование невозможно без изолированных и воспроизводимых тестовых окружений. Современным стандартом для решения этой задачи является использование технологий контейнеризации, таких как Docker.
Для интеграционных тестов, включающих несколько взаимодействующих сервисов (веб-приложение, база данных, брокер сообщений), стандартом является инструмент Docker Compose. Он использует YAML-файл для определения и запуска многоконтейнерного приложения.
Описываются:
- сервисы: компоненты приложения (
web,db,redis) - образы: Docker-образы, на основе которых будут созданы контейнеры
- порты: пробросы портов из контейнера на хост-машину
- переменные окружения: конфигурация сервисов
- зависимости: порядок запуска контейнеров (например,
depends_onгарантирует, что база данных запустится раньше приложения)
Используемый для тестирования файл
docker-compose.yamlстановится ключевым артефактом; он неявно, но точно документирует все runtime-зависимости сервиса
Для управления контейнерами в процессе интеграционного тестирования часто применяется фреймворк Testcontainers
¶ Заключение
Эффективность стратегии интеграционного тестирования нельзя измерять только количеством пройденных или проваленных тестов. Традиционные метрики, такие как покрытие кода, мало что говорят о качестве интеграционного тестирования. Сервис может иметь 100% покрытие кода от модульных тестов, но его взаимодействие с другими сервисами может быть вообще не протестировано.
Покрытие интерфейсов (Interface Coverage)
Ключевая метрика для интеграционного тестирования. Вместо того чтобы измерять, какие строки кода были выполнены, она измеряет, сколько из возможных взаимодействий между компонентами было проверено. Это может включать:
- количество протестированных ручек API
- разнообразие типов сообщений, переданных через очередь
- проверка различных переходов состояний во взаимодействующих компонентах
Плотность дефектов (Defect Density)
Метрика отслеживает количество дефектов, обнаруженных на единицу размера или сложности кода (на 1000 строк кода). Высокая плотность дефектов на этапе интеграционного тестирования для определенного компонента может указывать на недостаточную проработку. Значит что компонент требует дополнительного тестирования или рефакторинга.
Одна из целей хорошей архитектуры — сделать систему тестируемой
Поддерживая низкую связанность между модулями, мы минимизируем количество точек интеграции, что упрощает тестирование. Растущее число сложных и нестабильных интеграционных тестов — показатель неуправляемой связанности в коде.