¶ Обеспечение качества больших данных
¶ Big Data QA
Дисциплина обеспечения качества (Quality Assurance, QA) в контексте систем больших данных претерпела фундаментальную трансформацию, обусловленную переходом от монолитных архитектур к распределенным вычислениям. Традиционные методологии тестирования программного обеспечения, опирающиеся на строгие детерминированные утверждения (assertions) и проверку на небольших локальных наборах данных, несостоятельны при работе с петабайтами информации.
Big Data QA — не масштабирование функционального тестирования, а отдельная поддисциплина на стыке программной инженерии, математической статистики и теории распределенных систем
Ключевой вызов заключается в 3V: объеме (Volume), скорости (Velocity) и разнообразит (Variety). Эти вещи делают классические стратегии исчерпывающего тестирования вычислительно неподъемными и экономически нецелесообразными. Когда система обрабатывает терабайты данных ежедневно, стоимость верификации каждой отдельной записи относительно эталона превращает процесс QA в инфраструктурное "бутылочное горлышко".
Стратегии QA вынуждены смещаться от абсолютного детерминизма к вероятностной корректности (статистическая выборка, эвристическая валидация и алгоритмы распределенной верификации)
В распределенных системах и фреймворках (Apache Spark) данные партиционируются (разделяются) между множеством узлов кластера. Эта архитектура привносит недетерминированное поведение, связанное с сетевыми задержками, сбоями узлов и состояниями гонки.
Пример.
Тестируем ETL-процесс на Apache Spark, который агрегирует транзакции клиентов за день и сохраняет итог в HDFS или S3 (CSV или Parquet). Входные данные: 100 миллионов транзакций, разбитых на 1000 партиций. Ожидаемый результат: агрегированная таблица с суммой переводов по каждому региону.
Тест-кейс: проверить, что SUM(Source_Amount) == SUM(Target_Amount).
Один из узлов кластера (Worker Node A), обрабатывающий партицию 50, начинает работать медленно из-за проблем с сетью или перегрузки диска. Драйвер Spark видит, что задача на узле A зависла. Чтобы ускорить процесс он запускает дубликат этой же задачи на свободном и быстром узле B, не убивая при этом сразу задачу на узле A (стандартная оптимизация в Big Data).
Теперь две задачи делают одно и то же одновременно:
- Node A наконец-то просыпается, завершает расчет и записывает файл part-00050 в целевую папку
- Node B тоже завершает расчет и пытается записать файл результата
В идеале Spark должен принять результат только одной задачи. Но если файловая система не поддерживает атомарные переименования или настроена неверно, то происходит состояние гонки. Обе задачи успешно записывают данные (или одна перезаписывает другую не полностью).
¶ CAP-теорема
Для тестирования распределенных систем необходимо глубокое понимание теоретических ограничений. CAP-теорема, которую сформулировал Eric Brewer, утверждает, что распределенная система с общими данными может гарантировать только два из трех свойств одновременно: согласованность (Consistency), доступность (Availability) и устойчивость к разделению (Partition Tolerance).
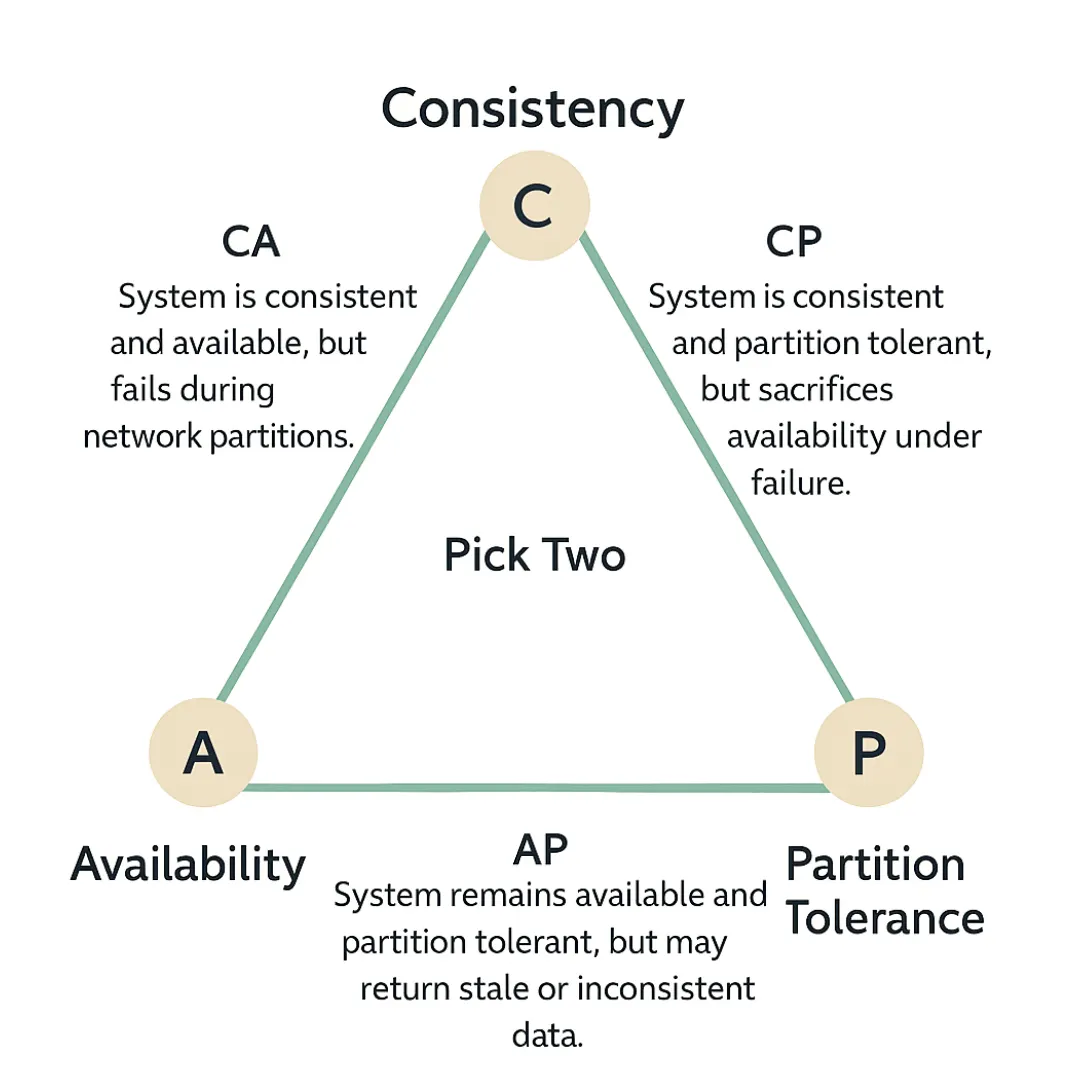
| Свойство | Определение в контексте QA |
|---|---|
| Consistency (C) | Все клиенты видят одни и те же данные в одно и то же время. Любая операция чтения возвращает последнюю запись или ошибку. |
| Availability (A) | Любой запрос получает (не ошибочный) ответ, даже если один или несколько узлов вышли из строя, без гарантии свежести данных. |
| Partition Tolerance (P) | Система продолжает функционировать, несмотря на потерю произвольного количества сообщений между узлами сети. |
В реальных условиях распределенных вычислений сетевые разделения (partitions) неизбежны; свойство Partition Tolerance (P) является обязательным и не подлежит обсуждению. Это заставляет архитектора и тестировщика делать бинарный выбор между системами CP (Consistency + Partition Tolerance) и AP (Availability + Partition Tolerance).
Мы тестируем не только функции, но и гарантии системы
При тестировании CP-систем (реляционные базы данных) фокус QA смещается на проверку того, что система корректно отказывает в обслуживании или блокирует операции при невозможности синхронизации. Если происходит разрыв сети, то тест должен подтвердить, что система ставит целостность данных выше доступности.
При тестировании AP-систем (Cassandra, DynamoDB, Spark Streaming) система продолжит обслуживать запросы, даже если данные устарели. Стратегия тестирования не может полагаться на утверждение assert(read_value == write_value) сразу после записи. Необходимо применять паттерн "AAAA": Arrange (Подготовка), Act (Действие), Achieve Eventual Consistency (Достижение согласованности), Assert (Проверка). Это подразумевает использование механизмов опроса (polling) или временных задержек, которые проверяютсходимость системы к согласованному состоянию в рамках определенного временного окна.
¶ Apache Spark и векторы тестирования
Для разработки эффективных тестов приложений Big Data необходимо понимать модель исполнения движка. Apache Spark функционирует на основе архитектуры "master-slave", состоящей из Драйвера (Driver) и множества Исполнителей (Executors).
Драйвер — процесс, который выполняет функцию main() приложения, создает SparkContext и преобразует пользовательский код в направленный нациклический граф (Directed Acyclic Graph, DAG) этапов выполнения. Исполнители — рабочие процессы на узлах кластера, ответственные за непосредственное выполнение задач и хранение данных.
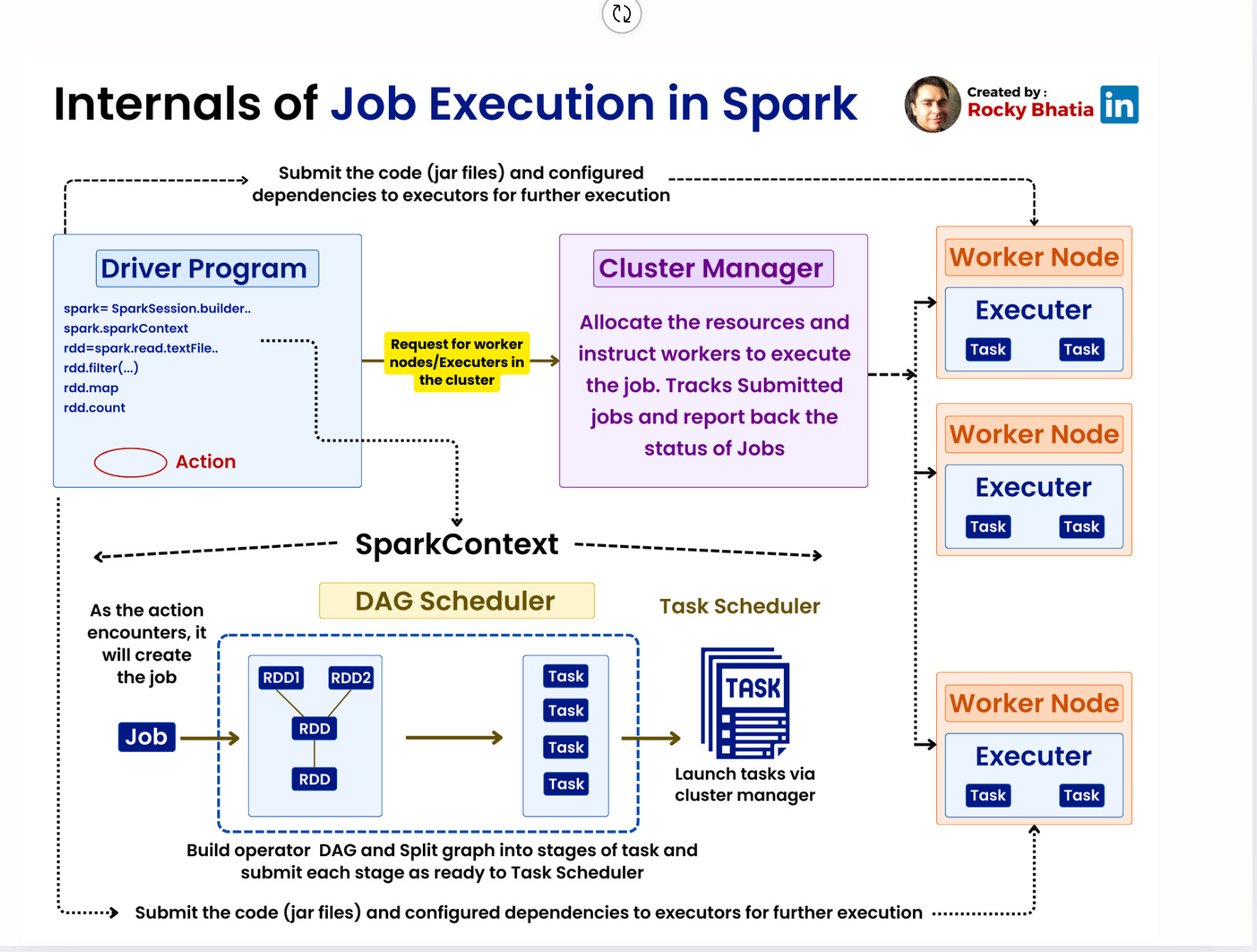
Код, написанный на драйвере (лямбда-функция внутри map), должен быть сериализован и передан по сети исполнителям. Распространенный сценарий отказа — ошибка сериализации, которая может не проявиться в локальных тестах (если они запускаются в одном JVM), но точно обрушит распределенный кластер.
Нельзя инициализировать тяжелые объекты на Драйвере и тянуть их в мапперы
# код на драйвере
class UrlParser:
def __init__(self):
# сложный конфиг
self.prefix = "https://"
def extract_domain(self, url):
return url.replace(self.prefix, "").split("/")[0]
parser = UrlParser()
# RDD
urls = sc.parallelize(["https://pmifi.ru", "https://pseudocoder.ru"])
# объект внутри лямбды (могут быть проблемы с сериализацией)
domains = urls.map(lambda url: parser.extract_domain(url))
print(domains.collect())
Как правильно?
def process_partition(iterator):
local_parser = UrlParser()
for url in iterator:
yield local_parser.extract_domain(url)
domains = urls.mapPartitions(process_partition)
Модель исполнения Spark базируется на трансформациях и действиях. Трансформации, такие как filter, joinm groupBy, не запускают вычисления немедленно; они модифицируют логический план выполнения. Вычисление инициируется только при вызове действия (count, collect, save).
Специфический подход к написанию тестов.
Функциональные тесты
Обязаны вызывать действие. Простое определение цепочки трансформаций без действия проверяет синтаксическую корректность построения DAG, но не логику обработки данных.
Тесты производительности
Нужно различать время построения плана и время его выполнения. Измерение времени выполнения вызова df.transform(...) без последующего действия покажет микросекунды, затраченные на работу планировщика, а не часы обработки данных.
Наиболее ресурсоемкой и подверженной ошибкам фазой является Shuffle — перераспределение данных между партициями для операций группировки или соединения. Если данные распределены неравномерно, то операция shuffle может вызвать переполнение памяти (Out-Of-Memory, OOM) на одном из исполнителей, в то время как остальные будут простаивать. Инженеры QA должны симулировать перекос данных в тестовых наборах (синтетические генераторы данных), чтобы убедиться, что приложение способно обрабатывать неравномерные нагрузки.
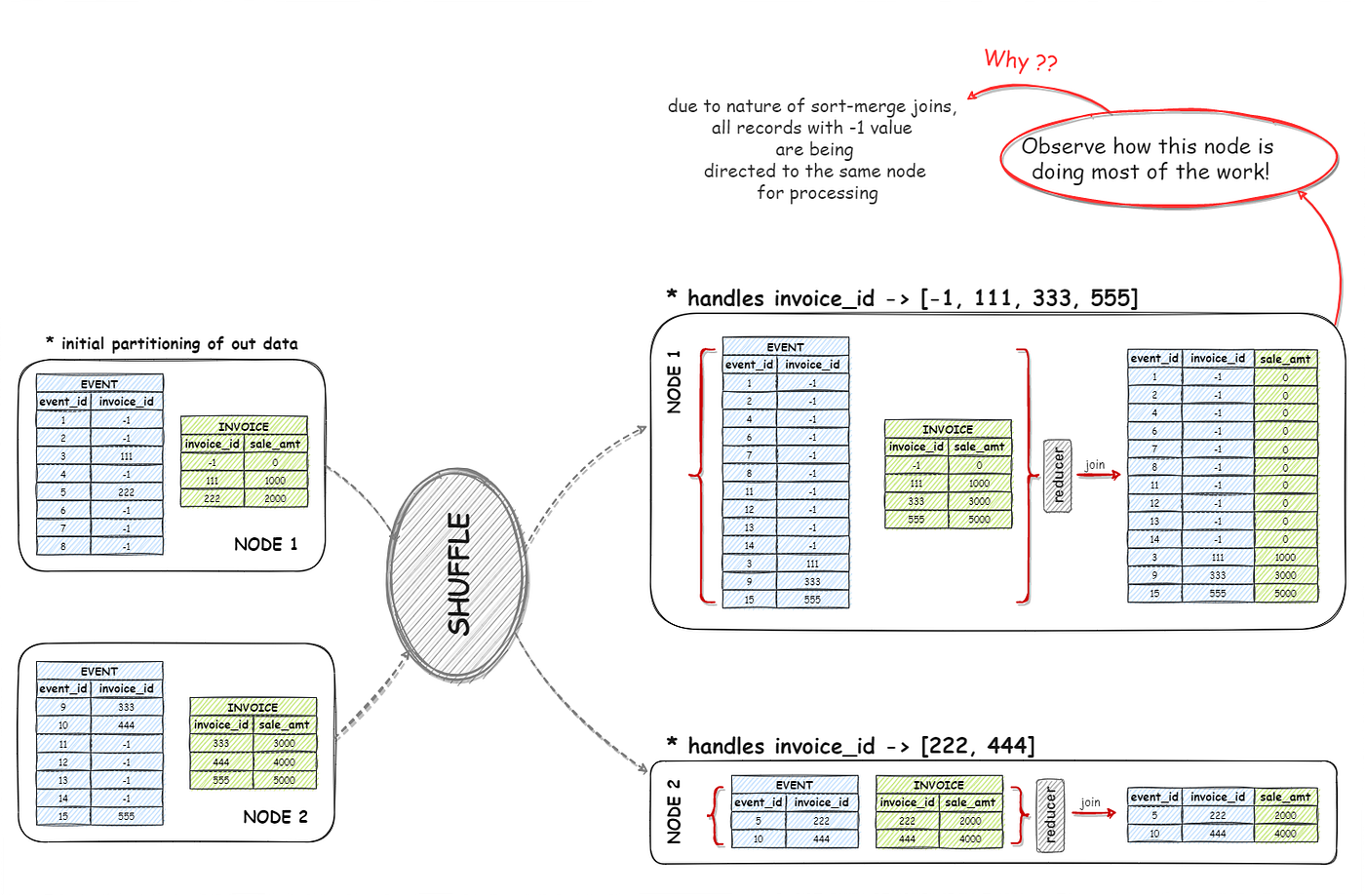
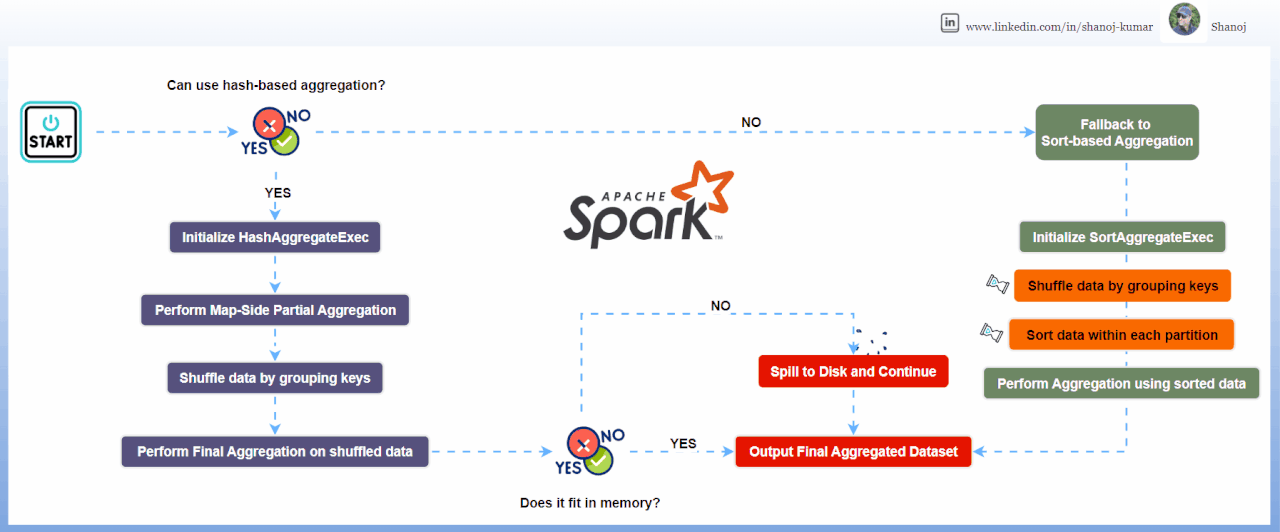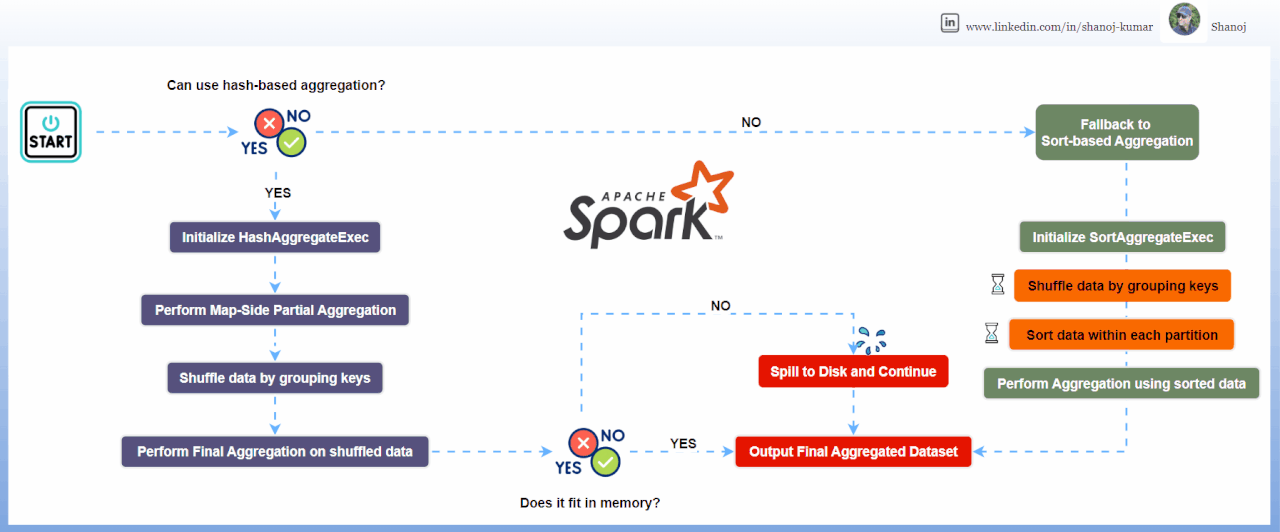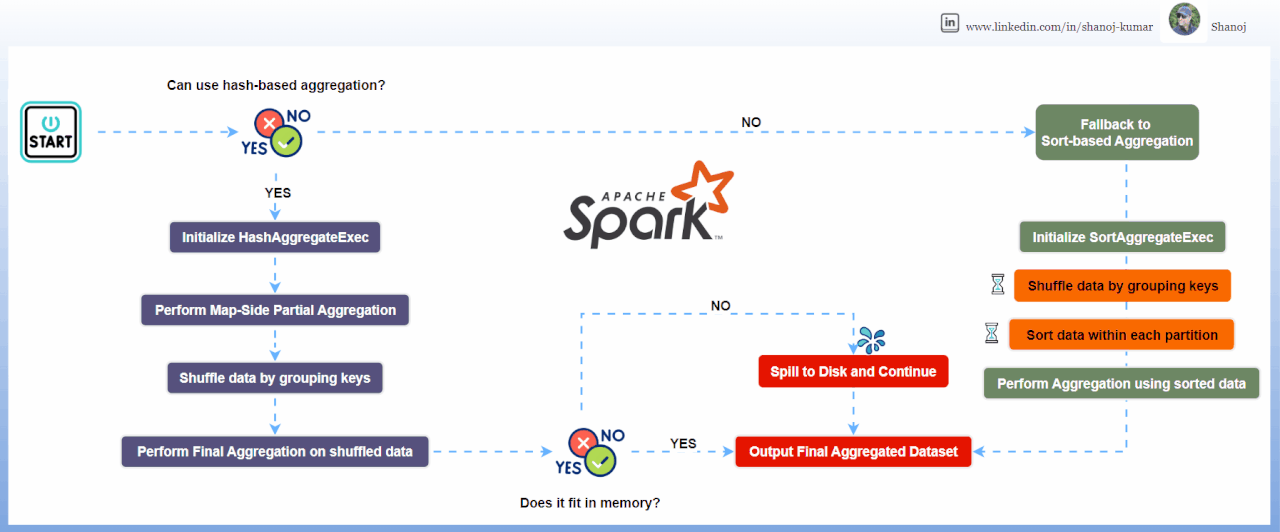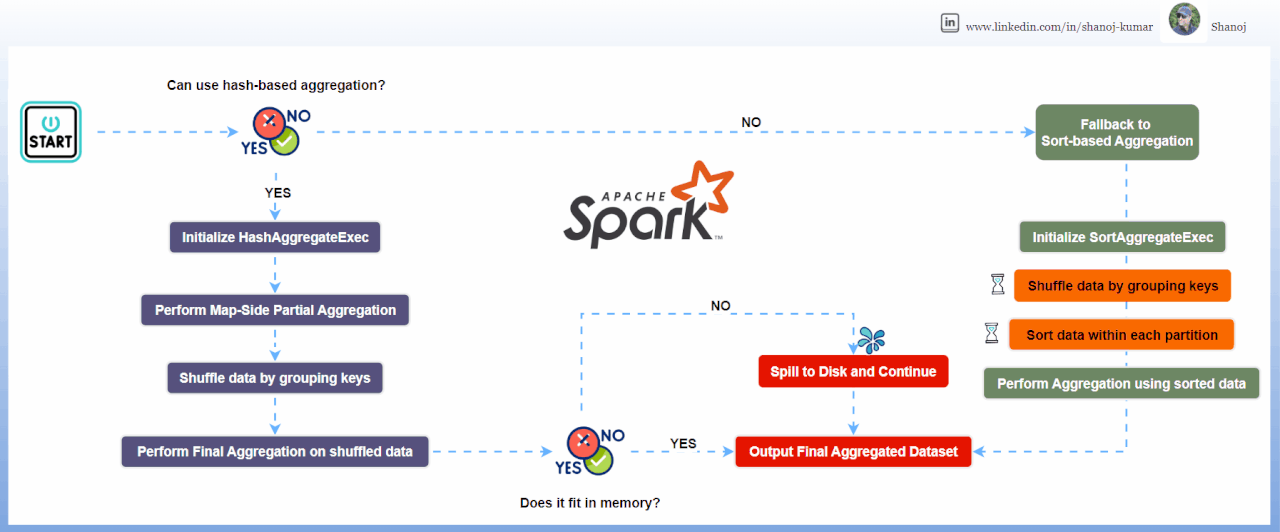
Внутренние механизмы Spark используют две основные стратегии агрегации, выбор которых критически влияет на производительность.
Hash Aggregate
Использует хеш-таблицу в памяти для выполнения агрегации. Это быстрый метод (доступ O(1)), но он требует значительного объема оперативной памяти. Spark использует его по умолчанию, когда типы данных изменяемы и подходят для хеширования.
Sort Aggregate
Сначала сортирует данные по ключу группировки, а затем итерируется по ним последовательно. Этот метод более надежен для наборов данных, превышающих объем памяти, так как позволяет сбрасывать данные на диск, но является процессороемким из-за сортировки (O(N log N)).
Надежная стратегия QA включает принудительное создание сценариев spill-to-disk. Искусственно ограничивая память исполнителей в тестовой среде (spark.executor.memory) можно проверить, корректно ли приложение переключается на SortAggregate без аварийного завершения. Если приложение падает под давлением памяти, то это сигнализирует о недостаточной надежности конфигурации агрегации или неверной оценке кардинальности ключей группировки.
¶ Модульное тестирование в PySpark
¶ Основы
Несмотря на сложность распределенных систем основание пирамиды тестирования остается неизменным — модульные тесты. В экосистеме PySpark это подразумевает тестирование отдельных трансформаций DataFrame в изоляции. Стандартный инструментарий включает фреймворк pytest в качестве раннера и специализированные утилиты из pyspark.testing или сторонние библиотеки типа chispa.
Инициализация SparkSession — тяжелая операция, включающая запуск JVM и настройку контекста. Наивный подход (для каждого тестового случая создается новая сессия) приведет к неприемлемому времени выполнения тестового набора.
Следует использовать фикстуры pytest с областью видимости scope="session". Это позволяет создать одну сессию на весь прогон тестов. Однако такой подход накладывает требования на идемпотентность тестов: они не должны изменять глобальное состояние сессии (конфигурации Spark SQL или временные таблицы), чтобы не влиять на последующие тесты.
import pytest
from pyspark.sql import SparkSession
@pytest.fixture(scope="session")
def spark_session():
spark = (SparkSession.builder
.master("local[*]")
.appName("TestSession")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate())
yield spark
spark.stop()
Сравнение двух DataFrame нетривиально. Простое сравнение ссылок df1 == df2 бесполезно. Сбор данных на драйвер через df.collect() и сравнение списков Python опасно из-за потери информации о схеме и типах данных.
Начиная с версии Spark 3.5, модуль pyspark.testing.utils предоставляет встроенные функции утверждения: assertDataFrameEqual и assertSchemaEqual. Эти функции реализуют сложную логику валидации.
Валидация схемы
Проверяются имена, типы и флаги nullability. Тест упадет, если IntegerType сравнивается с DoubleType, даже если значения визуально идентичны.
Нечеткое сравнение
Поддержка параметров rtol (относительная погрешность) и atol (абсолютная погрешность) для чисел с плавающей точкой.
Игнорирование порядка
По умолчанию Spark не гарантирует порядок строк. Функции сравнения должны либо сортировать данные перед проверкой, либо использовать методы сравнения множеств.
from pyspark.testing.utils import assertDataFrameEqual
result_df = spark.createDataFrame(
[(1, "Alice", 100), (2, "Bob", 200)], ["id", "name", "value"]
)
expected_df = spark.createDataFrame(
[(2, "Bob", 200), (1, "Alice", 100)], ["id", "name", "value"]
)
assertDataFrameEqual(result_df, expected_df)
¶ Валидация массивов
Современные форматы данных (Parquet, JSON) позволяют хранить сложные вложенные структуры, такие как массивы (ArrayType) и отображения (MapType). Валидация содержимого массива, распределенного по миллиардам строк, представляет собой задачу, которую невозможно решить стандартными SQL-запросами без потери производительности.
Требования QA к колонкам типа ArrayType:
Экзистенциальная проверка
Содержит ли массив определенное значение? (есть ли у пользователя роль 'Admin')
Квантификация
Удовлетворяют ли все элементы условию? (например, все ли транзакции положительны).
Структурная валидация
Соответствует ли длина массива ожиданиям после трансформации?
Spark SQL предоставляет инструмент для работы с массивами — функции высшего порядка. Они позволяют итерироваться по массивам непосредственно внутри движка выполнения, избегая дорогостоящей операции explode, которая разворачивает массив в строки и вызывает гигантский shuffle.
| Функция | Назначение | Пример использования |
|---|---|---|
array_contains(col, val) |
Проверка наличия элемента | filter(array_contains(col("tags"), "urgent")) |
size(col) |
Проверка длины массива | filter(size(col("items")) > 0) |
exists(col, func) |
Проверка хотя бы один | filter(exists(col("scores"), lambda x: x < 0)) |
forall(col, func) |
Проверка все элементы | filter(forall(col("flags"), lambda x: x == True)) |
explode(col) |
Взрыв массива | Соединение элементов массива с другой таблицей. |
Распространенной ошибкой в Big Data QA является использование explode() для проверки содержимого массива. Если набор данных содержит 1 миллиард строк и каждая имеет массив из 100 элементов, то explode() сгенерирует 100 миллиардов строк. Это может привести к экспоненциальному росту времени выполнения и падению джобов. Использование array_contains для проверки является предпочтительным паттерном, а explode оправдан только в тех случаях, когда валидация требует соединения элементов массива с другой таблицей (join).
Для Python-ориентированных процессов библиотека Pandera предлагает декларативный стиль определения схем (включая проверки значений массивов). Pandera интегрируется с PySpark и позволяет определять Checks — пользовательские функции валидации, которые исполняются во время выполнения.
import pandas as pd
import pandera as pa
from pandera import Column, Check
schema = pa.DataFrameSchema({
"order_id": Column(
int,
checks=[
Check.greater_than(0),
Check.unique
]
),
"product_name": Column(str),
"price": Column(
float,
checks=Check.greater_than(0)
),
"status": Column(
str,
checks=Check.isin(["new", "shipped", "canceled"])
),
"email": Column(
str,
checks=Check.str_matches(r"^[\w\.-]+@[\w\.-]+\.\w+$"),
nullable=True
),
})
data = {
"order_id": [101, 102, 101],
"product_name": ["Laptop", "Mouse", "Keyboard"],
"price": [1500.00, -25.50, 50.00],
"status": ["new", "unknown", "shipped"],
"email": ["user@test.com", None, "bad_email"]
}
df_invalid = pd.DataFrame(data)
try:
schema.validate(df_invalid, lazy=True)
print("Данные валидны!")
except pa.errors.SchemaErrors as err:
print("Данные НЕ валидны!\n")
print(err.failure_cases[["column", "check", "failure_case"]])
¶ Вероятностная валидация
В ситуациях петабайтного масштаба выполнение вычислительно сложных валидаций (проверка регулярными выражениями или сложные геометрические вычисления) на всех данных часто невозможно в рамках SLA. Решением является статистическая выборка (Statistical Sampling): отбор репрезентативного подмножества данных для вывода о качестве всей генеральной совокупности.
Семплирование меняет вопрос QA с "Идеальны ли данные?" на "Насколько мы уверены, что уровень ошибок ниже допустимого порога?"
Для обеспечения репрезентативности выборки нельзя просто взять случайные 10%. Размер выборки должен быть статистически обоснован на основе желаемого уровня доверия (Confidence Level) и предела погрешности (Margin of Error).
Классическая формула Кокрана для бесконечных совокупностей имеет вид:
Где:
- — идеальный размер выборки
- — Z-оценка, соответствующая уровню доверия (например, 1.96 для 95%)
- — оценочная доля признака (обычно берется 0.5 для максимальной дисперсии)
- — желаемый предел погрешности (например, 0.05 для ±5%)
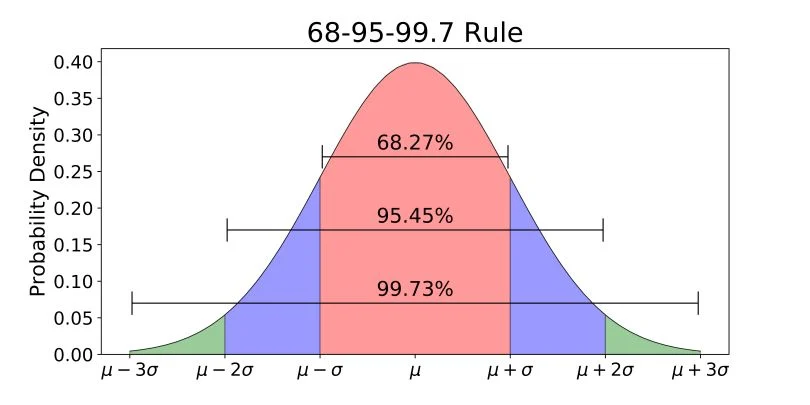
Если совокупность конечна (конкретный батч из 1 миллиона записей), применяется корректировка на конечность совокупности:
Где — размер генеральной совокупности.
Этот математический аппарат позволяет QA-инженеру обосновать, почему проверка всего 385 записей достаточна для утверждения с 95% уверенностью о качестве набора данных из 100 миллионов записей, при условии, что выборка является истинно случайной
После анализа выборки результаты интерпретируются через доверительные интервалы. Если тест на выборке показывает уровень ошибок 2%, доверительный интервал указывает диапазон, в котором с заданной вероятностью находится истинный уровень ошибок всей совокупности.
В PySpark вычисление среднего и стандартного отклонения выборки позволяет построить эти интервалы, используя t-распределение Стьюдента (для малых выборок) или нормальное распределение (для больших).
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from scipy import stats
import math
# выборка с 2% ошибок
spark = SparkSession.builder.appName("Calculation").getOrCreate()
data = [(1,) if i < 20 else (0,) for i in range(1000)]
df_sample = spark.createDataFrame(data, ["is_error"])
# размер выборки (n), среднее (mean) и стандартное отклонение (stddev)
stats_row = df_sample.select(
F.count("is_error").alias("n"),
F.mean("is_error").alias("mean"),
F.stddev_samp("is_error").alias("stddev")
).collect()[0]
n = stats_row["n"]
mean = stats_row["mean"]
std_dev = stats_row["stddev"]
confidence_level = 0.95
# Standard Error of Mean - SEM
sem = std_dev / math.sqrt(n)
# t-критерий Стьюдента
degrees_of_freedom = n - 1
t_critical = stats.t.ppf((1 + confidence_level) / 2, degrees_of_freedom)
# считаем предел погрешности (Margin of Error)
margin_of_error = t_critical * sem
# Итоговый интервал
lower_bound = mean - margin_of_error
upper_bound = mean + margin_of_error
Помимо простых агрегатов QA больших данных часто требует проверки того, что распределение данных не сместилось (Data Drift). Необходимо убедиться, что распределение в сегодняшнем батче соответствует историческому.
Тест Колмогорова-Смирнова (K-S Test) — непараметрический тест, используемый для сравнения двух распределений. Он вычисляет максимальное расстояние между эмпирическими функциями кумулятивного распределения двух выборок.
Двухвыборочный K-S тест сравнивает выборку из нового батча с выборкой из "золотого" эталонного батча. Если статистика K-S мала, а p-value высоко, то распределения статистически схожи.
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from scipy import stats
import numpy as np
spark = SparkSession.builder.appName("DataDrift").getOrCreate()
ref_data = np.random.normal(loc=50, scale=10, size=10000).tolist()
df_reference = spark.createDataFrame([(float(x),) for x in ref_data], ["feature_value"])
# похожее распределение
cur_data_ok = np.random.normal(loc=50.1, scale=10.1, size=5000).tolist()
df_current_ok = spark.createDataFrame([(float(x),) for x in cur_data_ok], ["feature_value"])
# Drift
cur_data_drift = np.random.normal(loc=55, scale=10, size=5000).tolist()
df_current_drift = spark.createDataFrame([(float(x),) for x in cur_data_drift], ["feature_value"])
def check_drift_ks(df_ref, df_cur, column_name, alpha=0.05, sample_size=10000):
count_ref = df_ref.count()
count_cur = df_cur.count()
ref_vals = df_ref.select(column_name).sample(fraction=min(1.0, sample_size/count_ref)).rdd.flatMap(lambda x: x).collect()
cur_vals = df_cur.select(column_name).sample(fraction=min(1.0, sample_size/count_cur)).rdd.flatMap(lambda x: x).collect()
ks_stat, p_value = stats.ks_2samp(ref_vals, cur_vals)
if p_value < alpha:
print("Распределения статистически различаются.")
else:
print("Распределения похожи.")
check_drift_ks(df_reference, df_current_ok, "feature_value")
check_drift_ks(df_reference, df_current_drift, "feature_value")
¶ Темпоральная корректность
Тестирование потоковых приложений (Structured Streaming) вводит дополнительное измерение — время. QA-инженер должен четко различать Event Time (когда событие произошло по факту) и Processing Time (когда событие поступило в систему аналитики).
Для управления состоянием в потоках Spark использует механизм Watermarking — пороговое значение времени, определяющее, как долго система ждет поздних данных перед тем, как финализировать результат окна и очистить состояние.
Тестирование водяных знаков требует создания сценариев, где данные поступают с искусственной задержкой, превышающей порог watermark. Тест должен верифицировать, что:
- данные, поступившие до истечения watermark, корректно включаются в агрегацию
- данные, поступившие после истечения watermark, отбрасываются, а состояние очищается для предотвращения утечки памяти
Пример.
Датчики отправляют данные каждую минуту. Но на заводе плохой Wi-Fi: иногда данные застревают и приходят пачкой спустя 15 минут.
Мы хотим считать среднюю температуру каждые 10 минут (оконная агрегация):
- окно: 10 минут (12:00–12:10).
- watermark: 10 минут.
Мы готовы ждать данные за окно 12:00-12:10 до тех пор, пока время в системе (максимальное Event Time) не перевалит за 12:20. Все, что придет позже, считаем мусором».
| Событие | Event Time (На датчике) | Processing Time (В Spark) | Статус | Логика |
|---|---|---|---|---|
| A (Норма) | 12:05 | 12:05 | Принято | Данные пришли вовремя. Агрегат окна 12:00-12:10 обновлен. Текущий Watermark движется за max event time. |
| B (Опоздание) | 12:08 | 12:14 | Принято | Событие из окна 12:00-12:10. Текущее макс. время событий: 12:14. Watermark: 12:14 - 10мин = 12:04. Событие 12:08 > 12:04, значит оно еще актуально. Окно пересчитывается. |
| C (Слишком поздно) | 12:03 | 12:21 | Отброшено | Событие из окна 12:00-12:10. Пришло новое событие с временем 12:21. Watermark сдвинулся: 12:21 - 10мин = 12:11. Событие 12:03 < 12:11. Порог пройден. Окно 12:00-12:10 уже закрыто и удалено из памяти. |
Как мы это тестируем?
Для проверки корректности не нужно ждать реальные 10 минут. В тестах подаем данные пачками, искусственно манипулируя полем event_time.
Шаг 1. Подаем первый батч
- event_time="12:05", temp=20
- создалось окно 12:00-12:10. Среднее = 20
- watermark примерно 11:55 (12:05 - 10 мин)
Шаг 2. Продвигаем время вперед (Сдвиг watermark)
- event_time="12:15", temp=25 (Окно 12:10-12:20)
- создалось новое окно
- максимальное время стало 12:15; watermark сдвинулся на 12:05
Шаг 3. Проверяем Late Data
- event_time="12:08", temp=30 (Окно 12:00-12:10)
- 12:08 > Watermark (12:05)
- ожидаем, что среднее пересчиталось: (20+30)/2 = 25
Шаг 4. Продвигаем время далеко вперед (закрытие окна)
- event_time="12:25", temp=22
- максимальное время 12:25; watermark сдвинулся на 12:15
- система понимает, что данные старше 12:15 больше не нужны; состояние окна 12:00-12:10 удаляется из памяти
Шаг 5. Проверяем Too Late Data
- event_time="12:09", temp=100 (Окно 12:00-12:10)
- 12:09 < watermark (12:15)
- ожидаем, что результат не меняется; окно 12:00-12:10 уже финализировано; среднее осталось 25, а не стало (20+30+100)/3
¶ Целостность данных
При миграции данных (из HDFS в S3) или репликации критически важно подтвердить идентичность источника и приемника. Побайтовое сравнение для данных объема 100 ТБ крайне трудоемко.
Распределенное хеширование.
На стороне HDFS: Spark-кластер читает данные, считает контрольную сумму (CRC32, MD5) для каждого файла/блока и сохраняет список.
На стороне S3: EMR/Lambda читает данные, считает хеши и сохраняет список.
По сети: передается только таблица хешей (текстовый файл). Сравниваются две таблицы хешей.
Стратегии.
Построчное хеширование
Создается новая колонка с хешем всех полей строки. Полезно для точечного поиска расхождений.
Партиционное хеширование
Хеши всех строк в партиции агрегируются (например, через XOR) в единый хеш партиции. Это позволяет быстро сравнить большие таблицы: если хеши партиций совпадают, данные идентичны. XOR-агрегация обладает свойством коммутативности, что делает её независимой от порядка строк.
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import StringType, IntegerType, StructType, StructField
spark = SparkSession.builder.appName("DataValidation").getOrCreate()
data_source = [
(1, "Alice", 1000),
(2, "Bob", 2000),
(3, "Charlie", 3000),
(4, "David", 4000)
]
data_target = [
(1, "Alice", 1000),
(4, "David", 4000),
(2, "Bob", 2000),
(3, "Charlie", 9999)
]
schema = ["id", "name", "amount"]
df_source = spark.createDataFrame(data_source, schema)
df_target = spark.createDataFrame(data_target, schema)
print("Построчное хеширование")
df_source_hashed = df_source.withColumn("row_hash", F.xxhash64(*df_source.columns))
df_target_hashed = df_target.withColumn("row_hash", F.xxhash64(*df_target.columns))
# Anti-Join (Left Anti)
# дай строки из Source, хешей которых нет в Target
diff_rows = df_source_hashed.join(
df_target_hashed,
on="row_hash",
how="left_anti"
)
diff_rows.show()
print("XOR-агрегация")
def calculate_xor_checksum(df):
return df.select(
F.xxhash64(*df.columns).alias("row_hash")
).agg(
F.expr("bit_xor(row_hash)")
).collect()[0][0]
source_checksum = calculate_xor_checksum(df_source)
target_checksum = calculate_xor_checksum(df_target)
print(f"Checksum Source: {source_checksum}")
print(f"Checksum Target: {target_checksum}")
if source_checksum == target_checksum:
print("Данные идентичны")
else:
print("Данные различаются")
¶ Заключение
Переход к QA больших данных требует смены парадигмы от детерминизма к вероятности, от функционального тестирования к архитектурному и от проверки счастливого пути к проверке устойчивости