Рекомендуется изучить обзор этой архитектуры от Data Secrets
¶ Введение
Простые RNN обрабатывают последовательности поддерживая скрытое состояние , которое обновляется на каждом временном шаге . Это выглядит так:
где — это вход на шаге , а и — матрицы весов. Во время обучения с использованием алгоритма обратного распространения ошибки во времени (Backpropagation Through Time, BPTT) градиент функции потерь по отношению к скрытому состоянию на далеком прошлом шаге () вычисляется с помощью цепного правила:
Ключевая проблема заключается в члене . Его вычисление включает в себя умножение на весовую матрицу и производную функции активации ().
Архитектура LSTM предложена в 1997 году (Sepp Hochreiter, Schmidhuber) как решение этой проблемы. Центральным элементом стала карусель постоянной ошибки (Constant Error Carousel, CEC).
Составляющие:
- cкрытое состояние (), долгосрочная память
- cостояние ячейки (), краткосрочная память
- гейты, с помощью которых контролируем, какую информацию оставляем или удаляем
Идея заключается в создании пути, на котором градиент двигается назад во времени практически без изменений. Это достигается за счет введения состояния ячейки (cell state), обозначаемого как (ранее в лекции как )
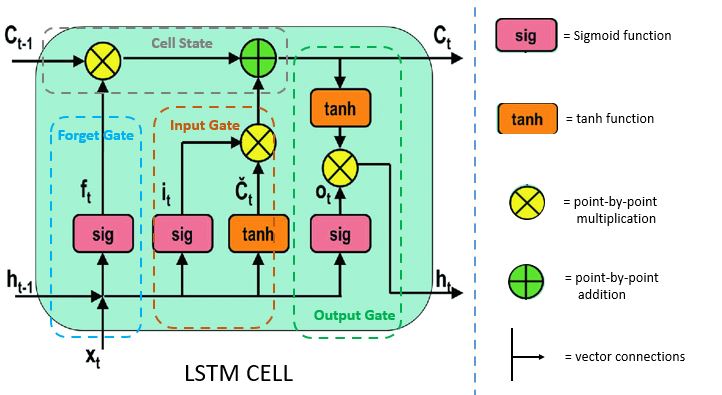
¶ Механизм CEC
Уравнение обновления состояния ячейки в LSTM:
Здесь — произведение Адамара, — вентиль забывания (forget gate), — вентиль входа (input gate), а — кандидат на новое состояние.
Вспоминаем проблему классических RNN:
Ключевая разница в сложении, а не в умножении внутри :
Раскрываем производную, при этом не смотрим на и (там будет затухающий путь):
Поскольку не зависит от напрямую, то производная этого поэлементного произведения:
Если сеть хочет помнить информацию из шага , она выучивается устанавливать для всех шагов между и
¶ Новые ячейки
¶ sLSTM
В мае 2024 года команда под руководством Sepp Hochreiter опубликовала новое исследование. Представлено семейство моделей xLSTM, построенное на двух инновациях:
-
экспоненциальное гейтирование (Exponential Gating)
-
модифицированные структуры памяти (Scalar и Matrix Memory)
Два новых типа рекуррентных ячеек: sLSTM (скалярная LSTM) и mLSTM (матричная LSTM)

Основное отличие sLSTM заключается в замене сигмоидных функций активации в вентилях входа и забывания на экспоненциальную функцию .
Использование функции создает проблему: значения могут быстро расти, приводя к нестабильности обучения. Для преодоления этой сложности вводятся два состояния (наряду с и ).
Состояние нормализатора обновляется по формуле:
Отслеживает сумму всех входных и забывающих вентилей, которые внесли вклад в текущее состояние ячейки. Скрытое состояние вычисляется как нормализованное состояние ячейки:
Состояние стабилизатора контролирует экспоненту от "взрыва":
Поскольку — максимум из двух частей, то обе разности в скобках гарантированно будут отрицательными или нулем
¶ mLSTM
Ключевое изменение — переход от векторного состояния ячейки к матричному состоянию .
Вентили и входы в mLSTM зависят только от текущего входа . Это делает mLSTM полностью распараллеливаемой в ходе обучения.
На каждом шаге модель вычисляет три вектора из входа : запрос (query, ), ключ (key, ) и значение (value, ). Авторы явно чем-то вдохновились 
Вычисляются с помощью обучаемых линейных преобразований, которые не зависят от :
Память обновляется с помощью ковариационного правила обновления, которое использует внешнее произведение ключа и значения:
Эта операция записывает ассоциацию между ключом и значением в матрицу памяти . Матрица становится суммой всех прошлых ассоциаций ключ-значение, взвешенных вентилями. Здесь и являются скалярами (применяется сигмоида как обычной LSTM). Выход блока вычисляется как .
Раскроем выражение:
Вес для каждого значения определяется скалярным произведением его ключа и текущего запроса . Эта формула параллелится.
Не забываем о нормализации:
¶ Остаточные блоки и выводы
Архитектура xLSTM — это глубокая сеть, созданная путем стекирования блоков xLSTM. Каждый блок содержит слой sLSTM или mLSTM, за которым следуют слои прямой связи (feed-forward), нормализация (Layer Normalization) и остаточные связи.
xLSTM — это:
- асимптотика O(n) и возможность распараллеливания при обучении
- асимптотика O(1) при инференсе для каждого токена
Для sLSTM в оригинальном исследовании предложены следующие блоки:
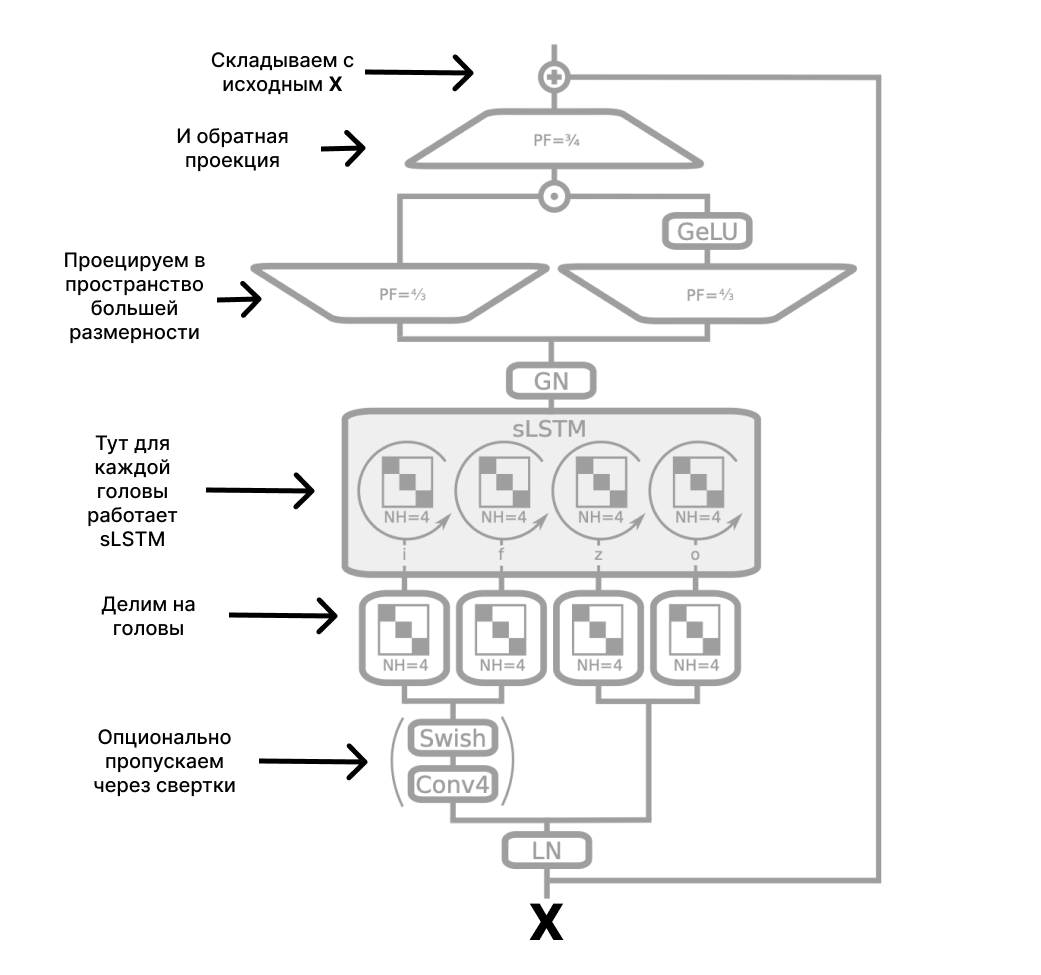
Здесь GELU (Gaussian Error Linear Unit):
Для mLSTM все то же самое, но в другом порядке. Отражаем входы в пространство большей размерности -> делим на головы -> пропускаем через mLSTM -> объединяем по GroupNorm -> проецируем обратно в родную размерность -> складываем со входами.
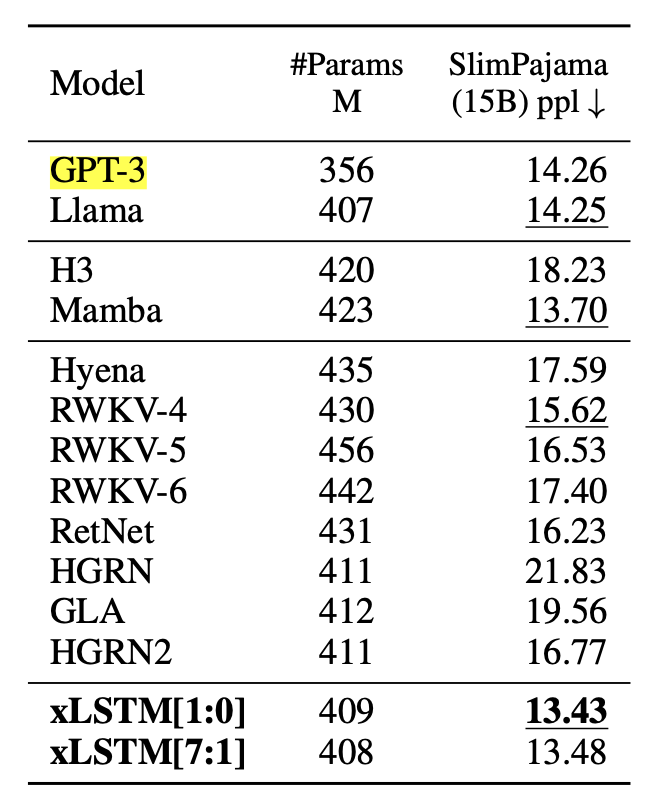
Падение перплексии на наборе данных SlimPajama:
Перплексию можно понимать как эффективное количество вариантов, из которых модель выбирает на каждом шаге. Если перплексия модели равна 100, значит ее неуверенность при предсказании следующего токена эквивалентна выбору одного из 100 равновероятных слов

Модель сопоставима с GPT-3 на 350М параметров:
Архитектура xLSTM – новый виток Deep Learning и NLP, она обладает большим потенциалом.
Разработка xLSTM сопровождается целью создать конкурентоспособную европейскую технологию, чтобы бросить вызов доминированию американских и азиатских компаний в области больших языковых моделей
Сегодня наиболее распространены модели в модифицированных вариантах архитектуры Transformer, однако исследования в области гибридных подходов к обработки последовательностей продолжаются
xLSTM может оказать влияние не на замену универсальных чат-ботов, а на создание специфических приложений со сверхдлинными контекстами (научный анализ, анализ кода, сложное планирование) – всегда выбирайте конкретную архитектуру под конкретную задачу