¶ Проблемы рекуррентных нейронных сетей
Рекуррентные нейронные сети находились на волне хайпа первую половину прошлого десятилетия. В 2014 году была представлена архитектура GRU, проблема затухающих градиентов была решена.
При этом главная особенность рекуррентных сетей, - низкая скорость обучения, никуда не делась.
В виду рекуррентности вычисления на блоках сети не могут выполняться параллельно. Это несмотря на то, что по сути мы обучаем один блок с одним набором весов, после чего применяем его к каждому токену входной последовательности.
В то же время мы помним, что фиксированный размер скрытого состояния является “бутылочным горлышком” рекуррентных моделей. Требуется информация не только о входной последовательности в целом, но и о подпоследовательностях.
Решением проблемы стал механизм внимания, который расширил границы понимания естественного языка. Люди начали искать ответ на вопрос: можно ли уйти от рекуррентности и построить языковую модель, которая будет работать только с использованием внимания.
¶ Схема Трансформера
В 2017 году выходит статья Attention is all you need - научная работа, которая перевернула не только NLP, но и всё глубокое обучение в целом.
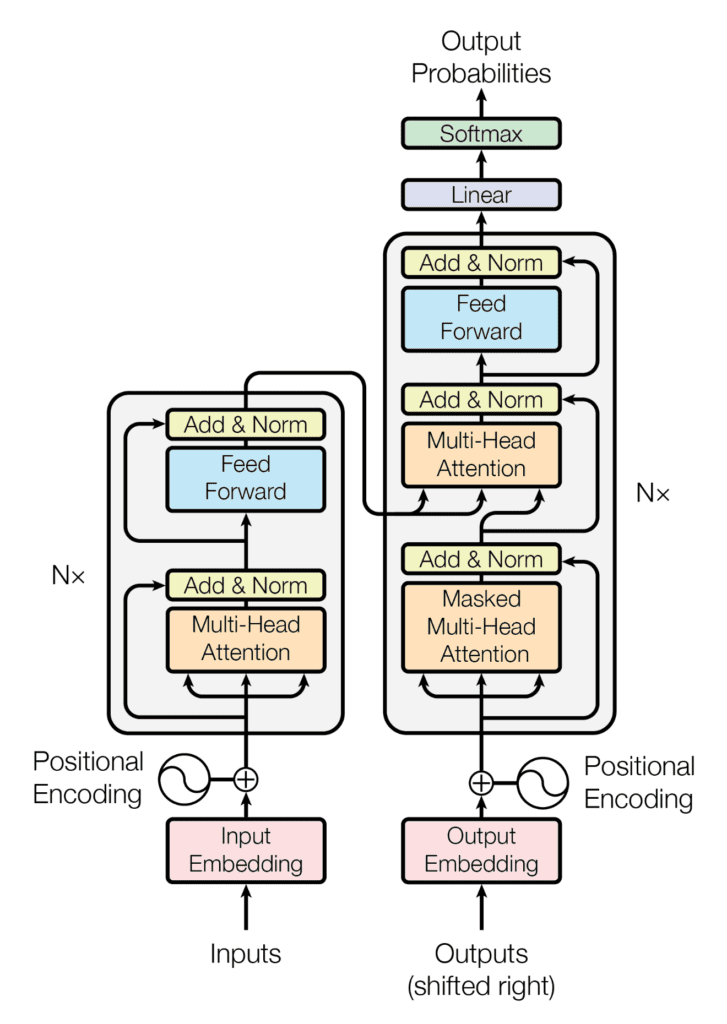
В статье авторы представили архитектуру модели Seq2Seq для машинного перевода, которую назвали Transformer. Она точно также включает в себя Encoder и Decoder, однако при этом в ней нет никаких рекуррентных блоков. Вместо них операции над матрицами, позиционное кодирование и главная фишка - Multi-head attention.
Новая модель показала невероятные результаты, обогнала модели RNN с вниманием по метрике BLEU. При этом, скорость обучения заметно выше, чем у RNN. Вычисления могут проводиться параллельно.
Схема Трансформера в общем виде выглядит следующим образом:
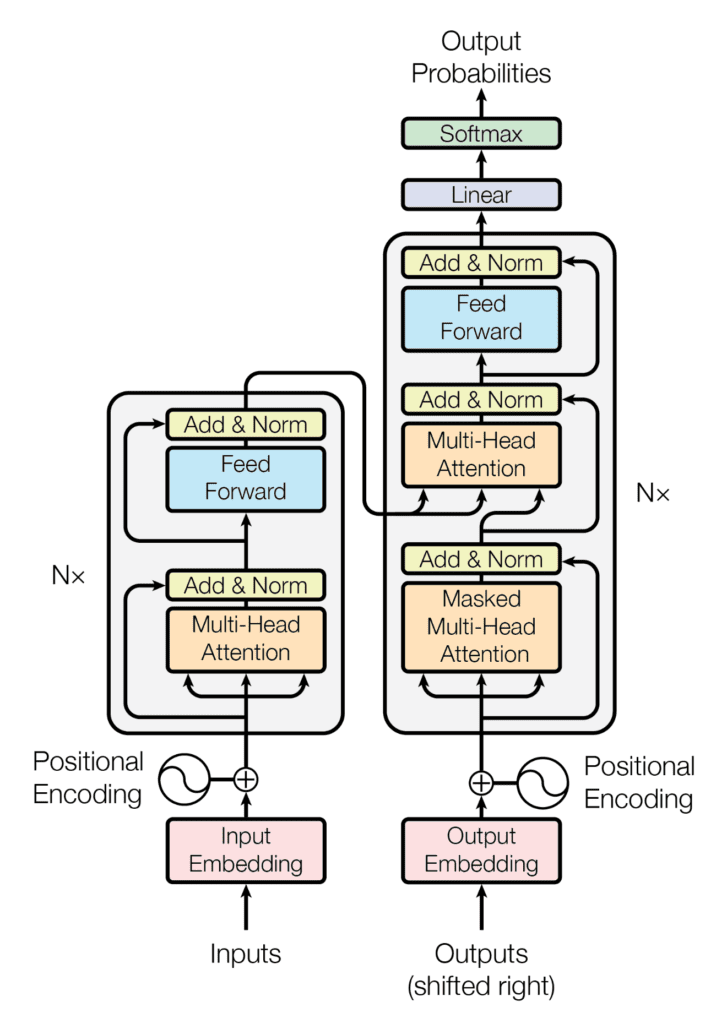
Стандартная реакция обычно следующая:

Но не переживайте, мы во всём разберёмся! 🙂
¶ Трансформеры на высоком уровне
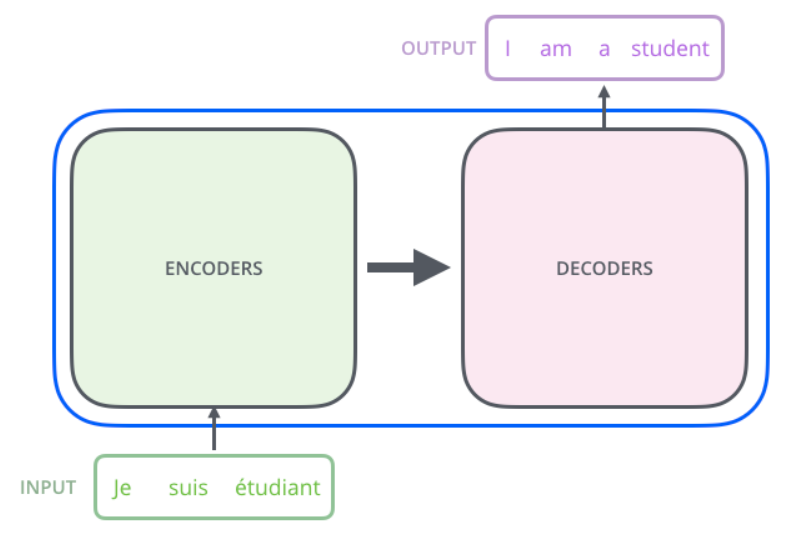
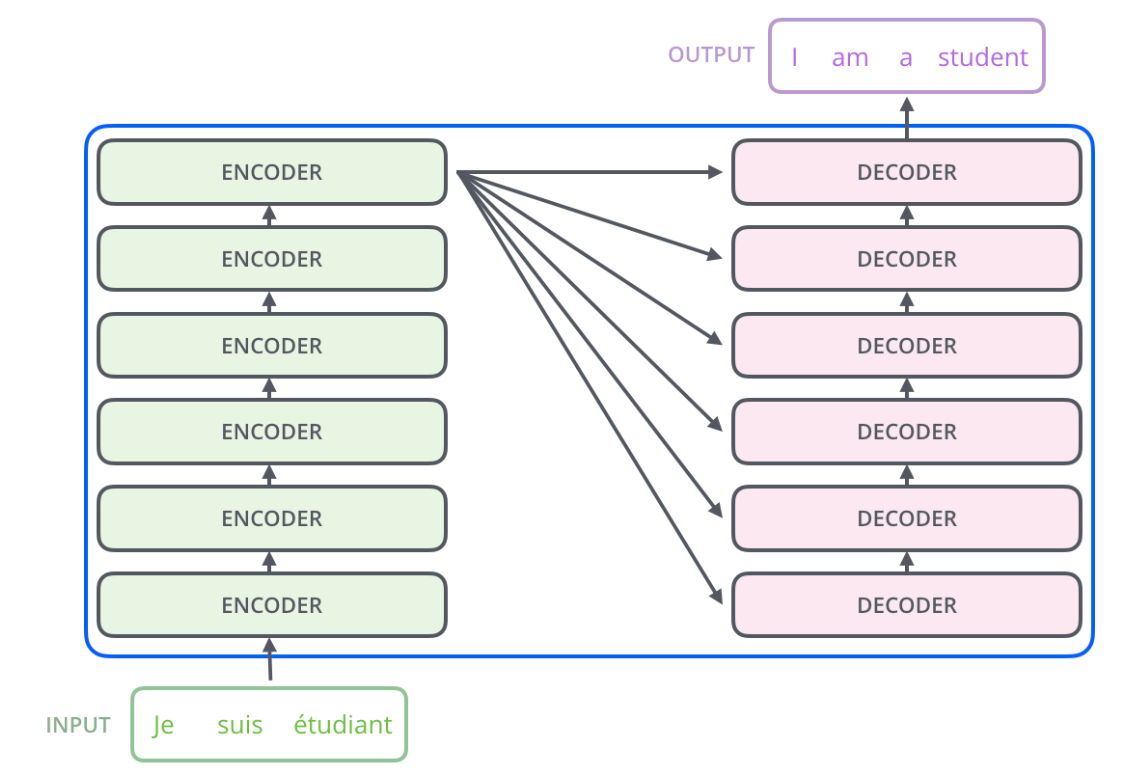
Классический Трансформер - это Seq2Seq модель.

Трансформер имеет множество кодировщиков и множество декодировщиков. Количество кодировщиков обязательно равняется количеству декодировщиков.
Погружаемся ниже - так кодировщик и декодировщик выглядят изнутри:
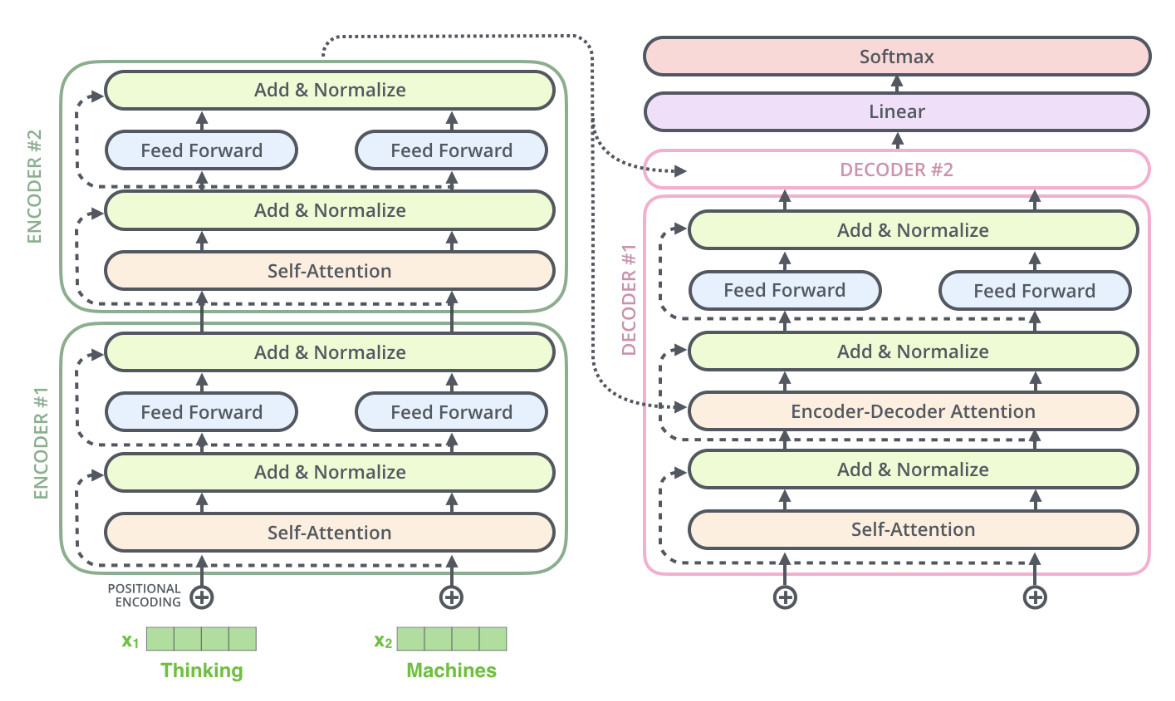
Из рисунка выше точно должно быть понятно, что на вход кодировщика и декодировщика подаются векторные представления слов. Но как работает все остальное? Проследим последовательность обработки векторных представлений слов трансформером с самого начала.
¶ Позиционное кодирование
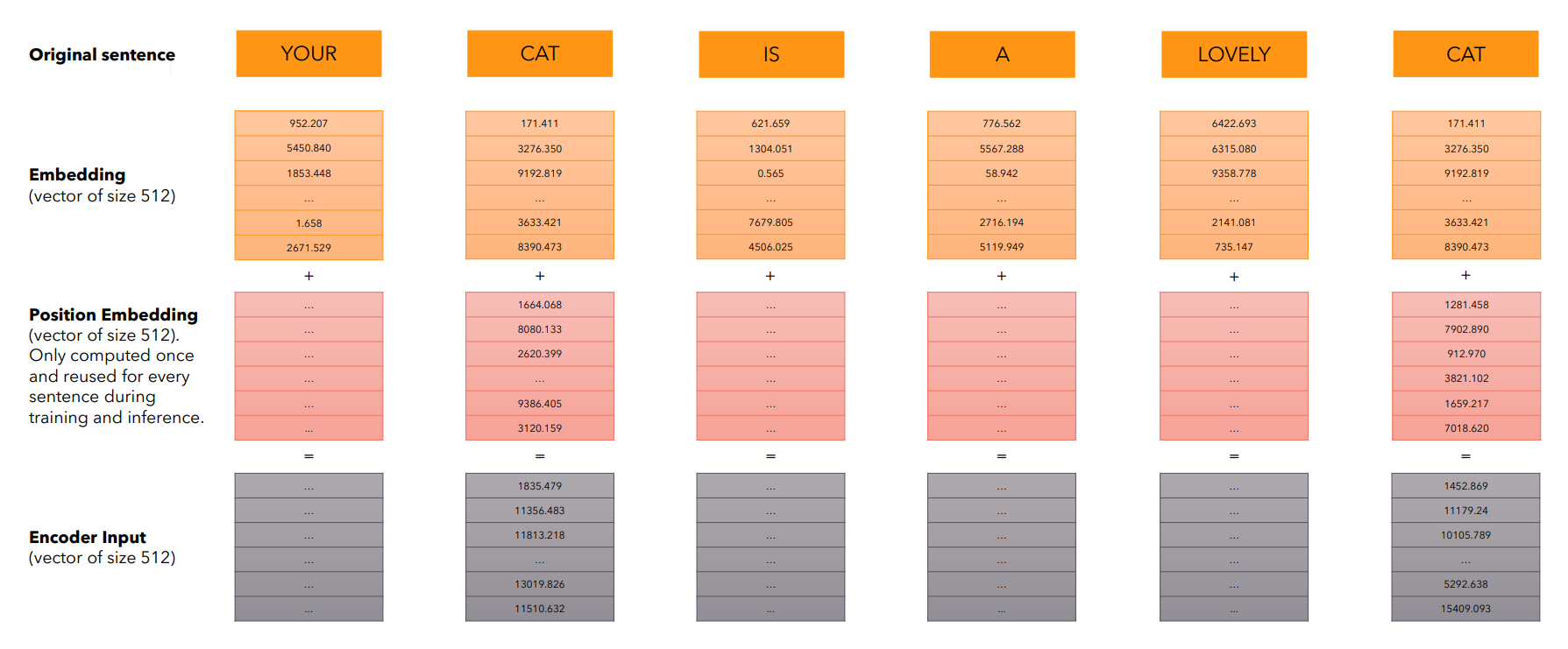
На вход трансформеру подаются эмбеддинги текстовых токенов в виде векторов (входной слой nn.Embedding или Word2Vec). При этом в виду особенностей работы трансформера векторные представления токенов собираются в матрицу (один вектор - одна строка матрицы).
Таким образом мы уходим от рекуррентности - от необходимости последовательной обработки токенов по одному.
Однако можно заметить, что теперь у нас нет информации о последовательности токенов во входной последовательности. Действительно, теряется основное преимущество рекуррентных сетей. Для решения этой проблемы авторы Трансформера предлагают использовать позиционное кодирование.
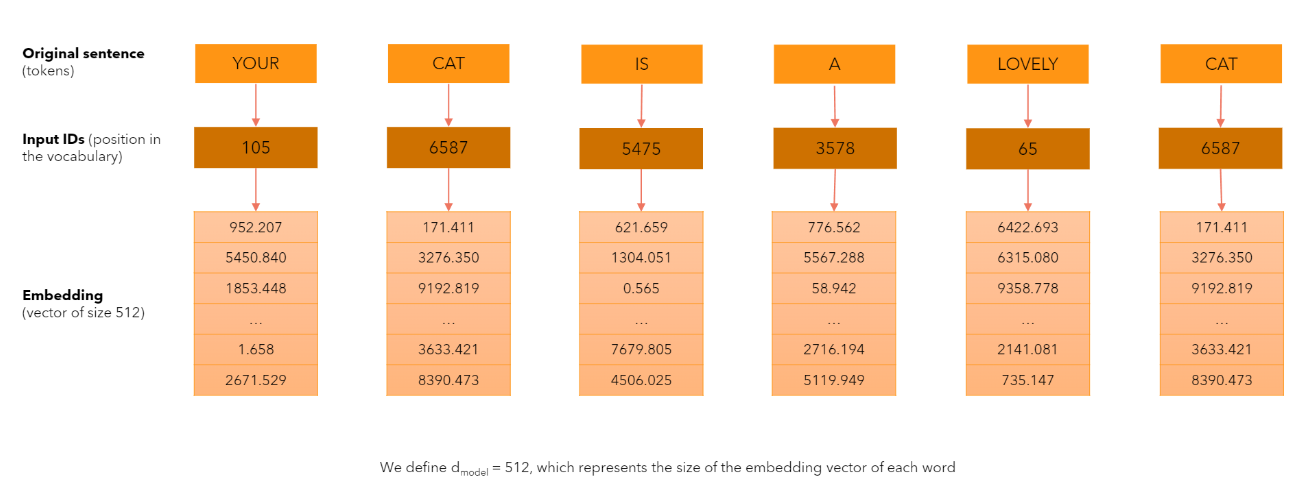
Размерность эмбеддинга установим 512 (так предлагается в статье Attention is all you need).
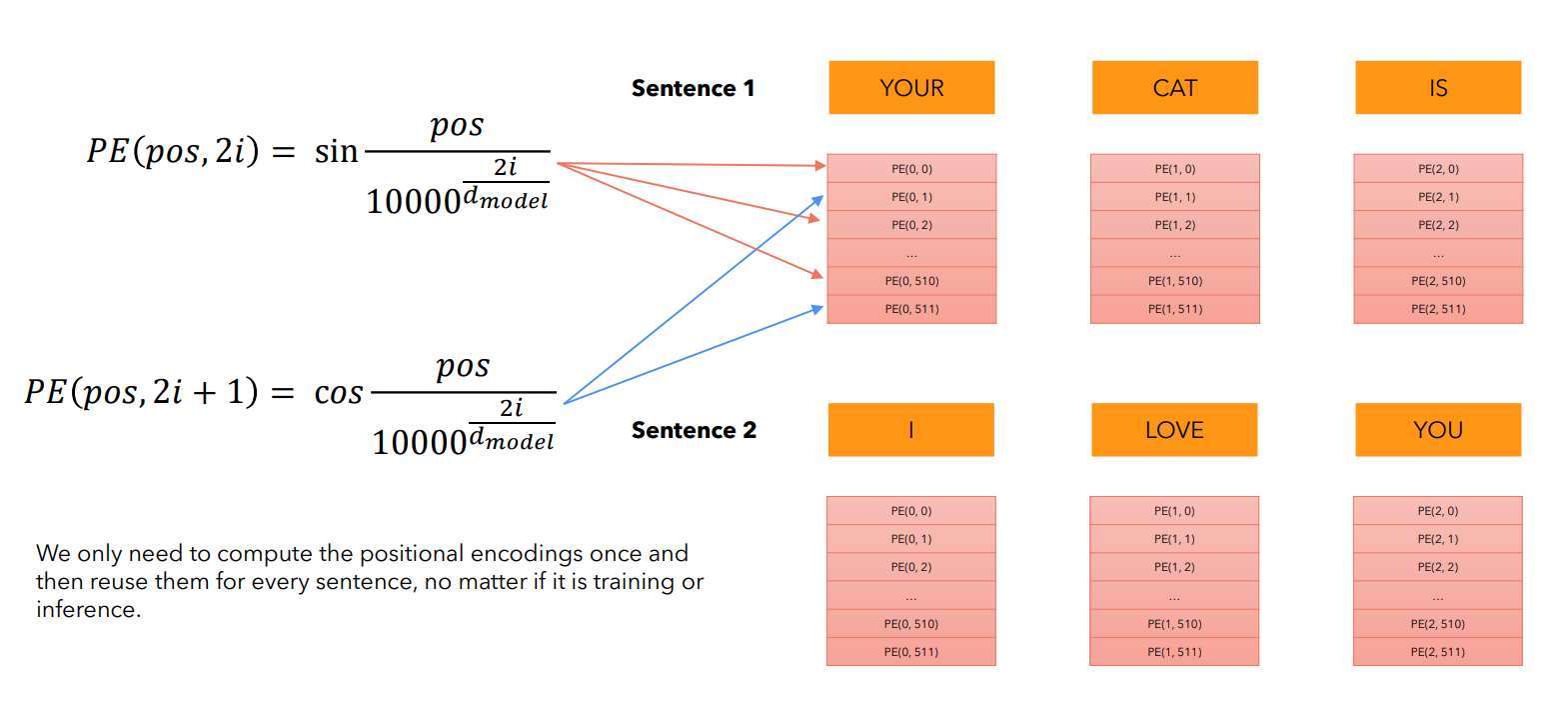
Позиционное кодирование представляет собой сложение эмбеддингов с некоторыми уникальными векторами, которые характеризуют позицию токена в тексте. Причем эти позиционные вектора никак не зависят от самих токенов - они вычисляются заранее.
Один из наиболее распространенных методов вычисления позиционных векторов - использование тригонометрических функций.
В общем виде формула позиционного вектора выглядит следующим образом:
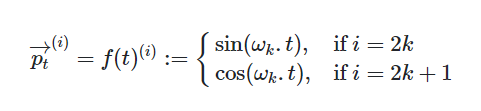
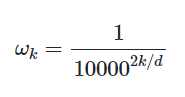
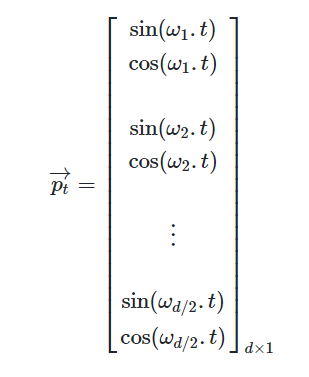
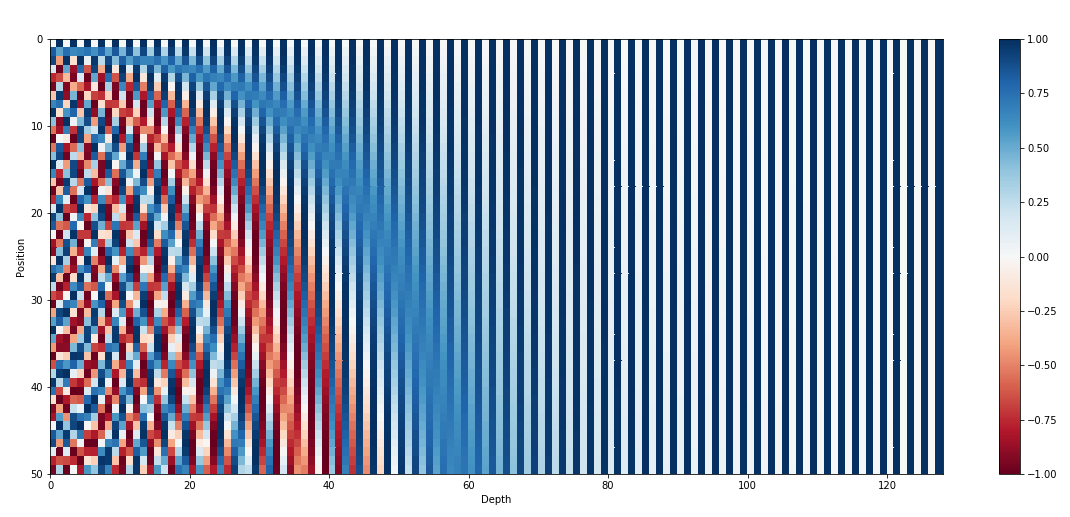
На рисунке выше рассматриваются последовательности длиной 50, эмбеддинги имеют размер 128. Видно, что эмбеддинги уникальны.
Но почему именно таким образом вычисляются позиционные вектора?
Мы хотим, чтобы позиционный вектор не только был уникальным, но также и единственным образом определял позицию соответствующего токена во входной последовательности. Для выполнения этого свойства нам необходимо, чтобы на основе известного позиционного вектора (для некоторой позиции t) мы могли бы независимо от позиции t вычислить позиционный вектор для любой другой позиции (t + w).
Модель в ходе обучения увидит эту закономерность и будет воспринимать позиционные вектора именно как характеристику позиции токена во входной последовательности.
Нам необходимо доказать, что используемый метод получения позиционного вектора обладает вышеуказанным свойством.

Докажем, что существует линейная трансформация M (не зависит от t - текущей позиции), с помощью которой можно вычислить позиционный вектор для любой другой позиции.
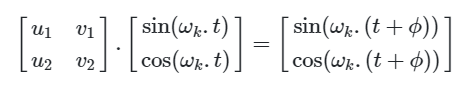
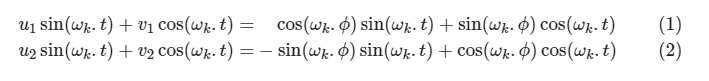
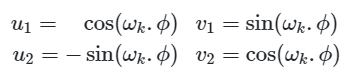
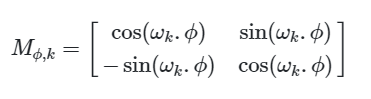
Видим, что получившаяся матрица M не зависит от t. Теперь модели не обязательно знать номер текущего токена для того, чтобы определить на сколько далеко или близко к нему располагаются другие токены входной последовательности.
Позиционное кодирование применяется как в кодировщике, так и в декодировщике.
¶ Multi-Head Attention (Self Attention с несколькими головами)
Ранее было обозначено, что ключевая особенность трансформеров - использование внимания. Внимание здесь заменяет последовательное преобразование скрытого состояния в рекуррентных сетях. Давайте разбираться как оно работает.
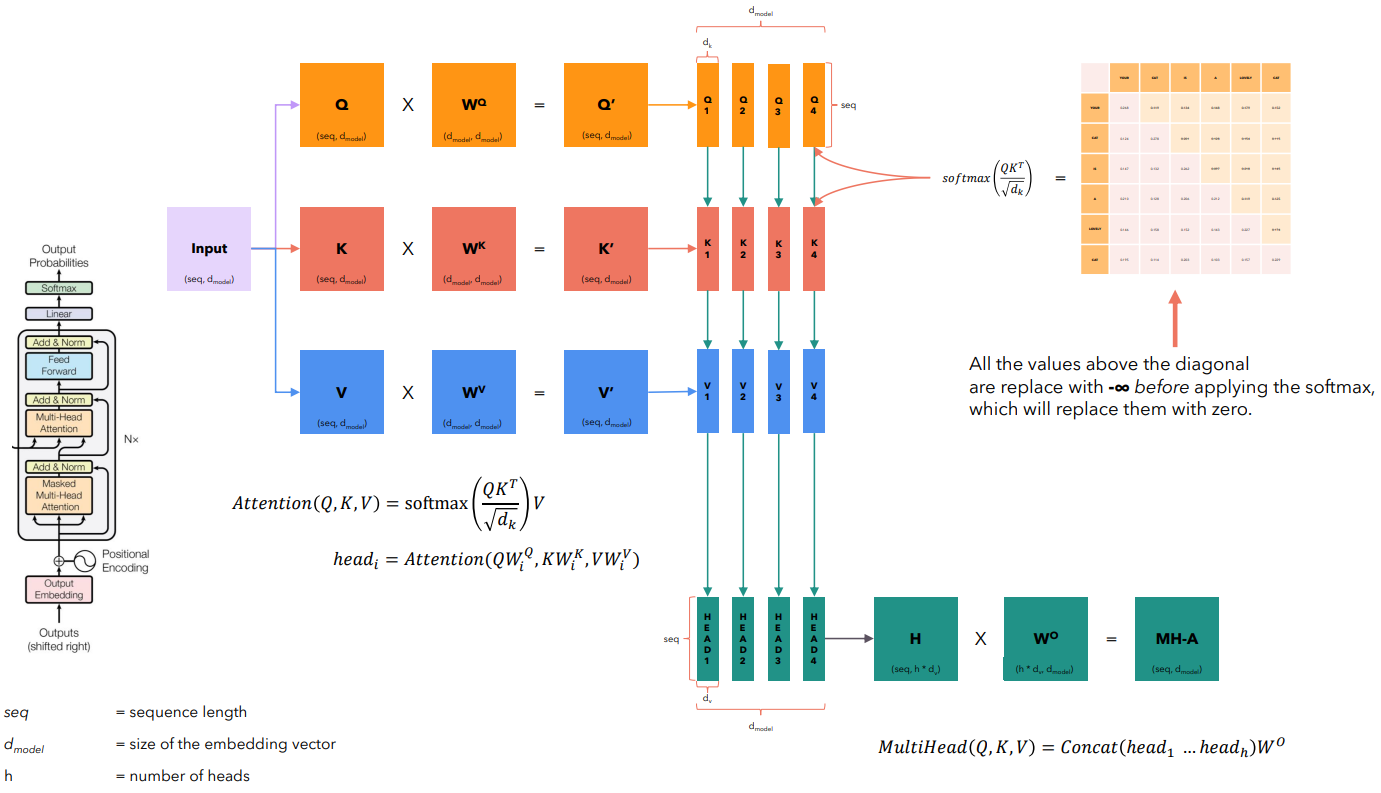
Для начала рассмотрим базовый Self Attention. Идея следующая - для каждого слова оценить влияние на него других слов. Влияние конечно же будем оценивать при помощи скалярного произведения. Здесь мы продолжаем оперировать такими понятиями как “запросы”, “ключи” и “значения” (когда мы говорили про механизм внимания в рекуррентных нейронных сетях, у нас были вектора-запросы и вектора-значения; используя вектор-запрос мы определенным образом взвешивали вектора-значения).
Механизм Self Attention предлагает сравнивать слова между собой. Вектора предлагается заменить матрицами. При этом изначально все 3 матрицы (запрос, ключ и значение) одинаковы и соответствуют входным данным.
Мы помним, что механизм внимания реализуется в два шага - на первом шаге используя вектор запрос мы взвешиваем значения.
Обратите внимание: именно в Self Attention появляются ключи. В рекуррентных сетях мы использовали запросы и значения для того, чтобы взвесить значения. а здесь используем запросы и ключи. При этом изначально (в первом кодировщике) ключ равен значению. По этому по сути мы и взвешиваем значения при помощи значений - прямая аналогия с вниманием рекуррентных нейронных сетей.
В скрытых слоях блоков Трансформера у нас не всегда ключи будут совпадать с запросами - за счет этого и будет реализовано взаимодействие кодировщика и декодировщика (запрос и ключи будут идти от кодировщика, а значения - от декодировщика).

В получившейся матрицы у нас содержатся веса - насколько каждое слово связано со всеми остальными. При этом к каждой строке матрицы мы применили softmax, а значит теперь можем взвесить значения при помощи полученных весов.
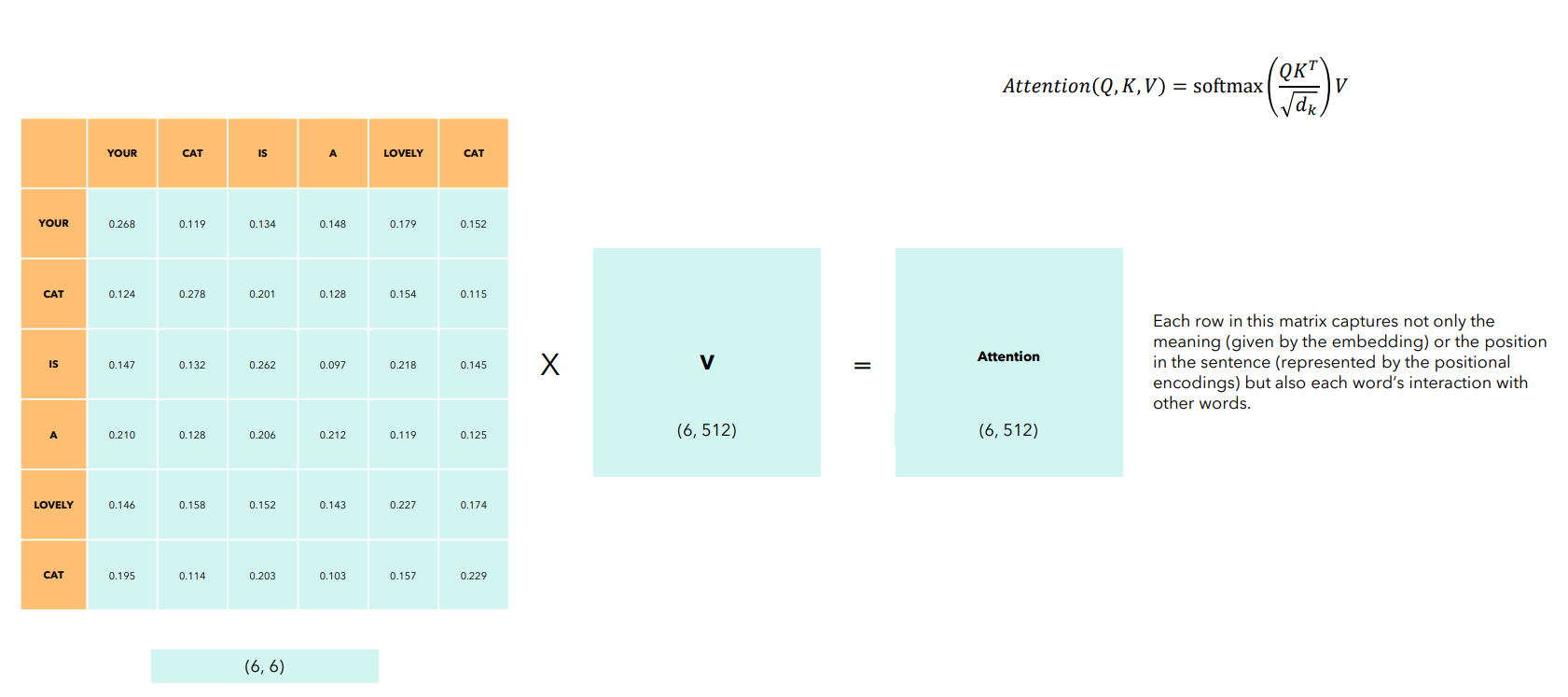
Видим, что получившаяся матрица имеет такой же размер, как и входная. Слой Self Attention не изменяет размеры входных данных.
Для улучшения качества работы Трансформеров предложен подход Self Attetntion с несколькими головами. При таком подходе мы инициализируем по три матрицы (Wq, Wk, Wv) для каждой головы и одну матрицу Wo. Все это - обучаемые параметры.
Матрицы Wq, Wk и Wv используем для преобразования соответственно запроса, ключа и значения. У нас есть два варианта:
- 1 вариант (более простой, как на картинке ниже) - матрицы Wq, Wk и Wv одинаковы для каждой головы, после преобразования размерностей вычисляются по знакомым формулам значения внимания; полученные в каждой голове значения конкатенируются и умножаются на матрицу Wo.
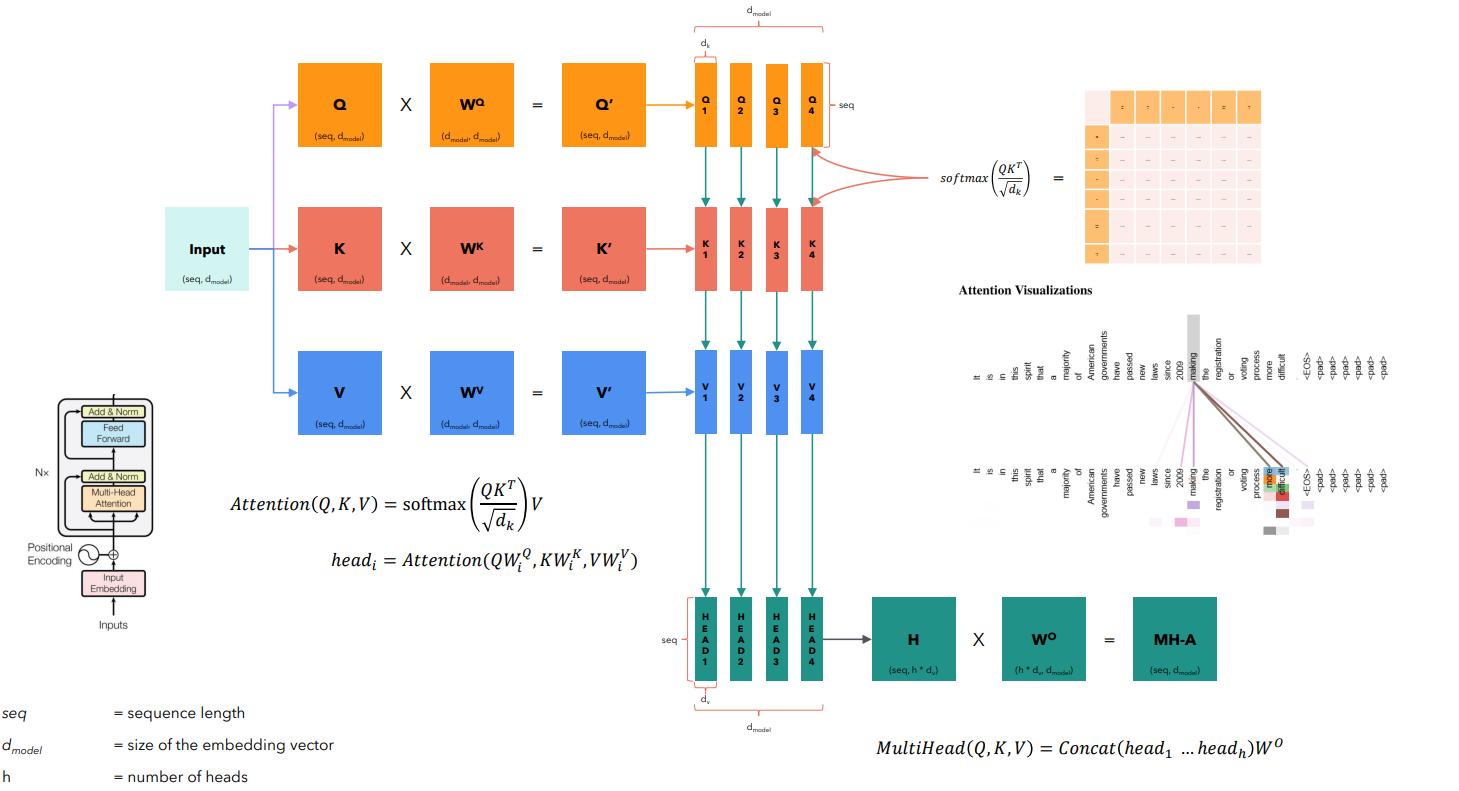
- 2 вариант (как предложили авторы статьи Attention is all you need) - матрицы Wq, Wk и Wv различные для каждой головы (попытка по разному посмотреть на входную последовательность), матрицы при этом не квадратные (количество столбцов - размер эмбеддинга деленный на количество голов); далее аналогично - считаются значения внимания для каждой головы, после чего происходит конкатенация и умножение на матрицу Wo.
Архитектура Трансформер не предъявляет требований к организации Multi-Head Attention, его можно реализовывать по своему усмотрению
¶ Нормализация и полносвязные слои
Выходом слоя Multi-Head Attention (или Self Attention) является матрица, каждая строка которой - текущий эмбеддинг соответствующего токена входной последовательности.
Следующей процедурой на очереди является нормализация, которая выполняется следующим образом:
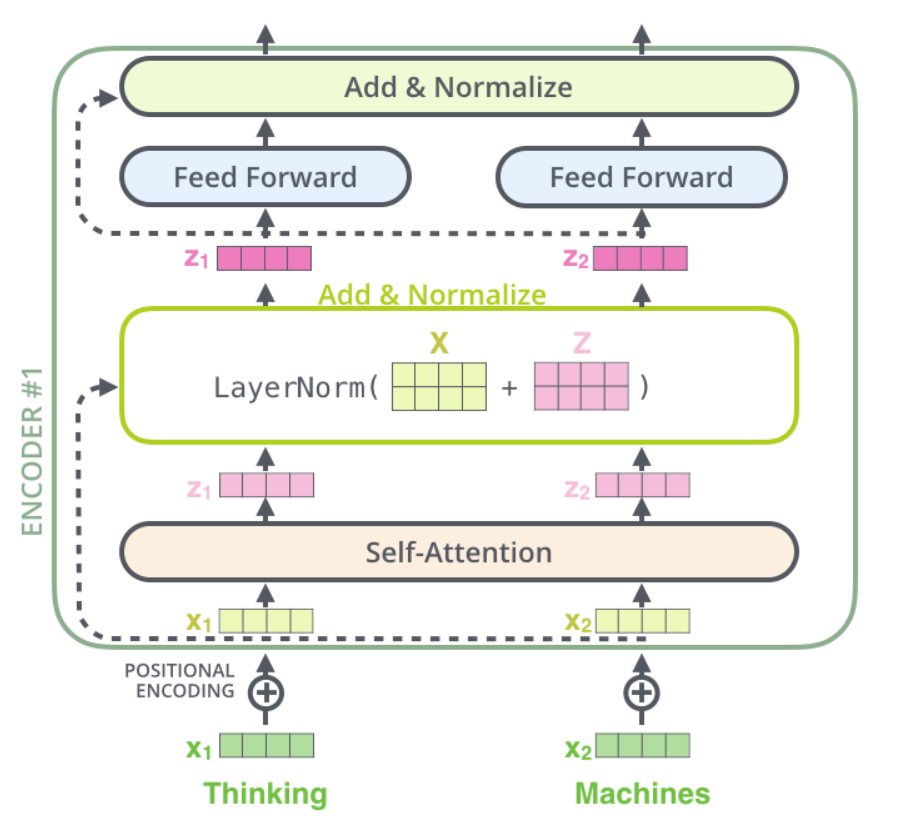
Сначала мы складываем эмбеддинги, которые не проходили через Attention, с эмбеддингами, полученными после обработки в слое Attention. После этого выполняем операцию LayerNorm следующим образом:
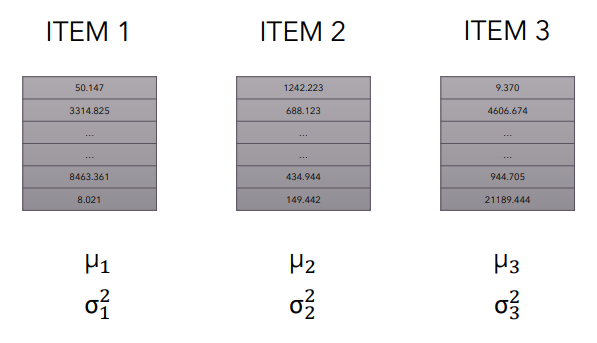
Для каждой строки матрицы считаем среднее и СКО. После этого выполняем нормализацию:
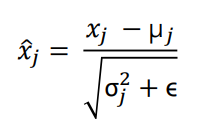
Со слоем Feed Forward все просто - это обычный линейный слой (возможно с активацией). Важно: мы прогоняем через один Feed Forward слой каждый из векторов (каждую строку матрицы).
Подведем промежуточный итог: в одном кодировщике мы обучаем минимум 5 матриц параметров (в зависимости от реализации Multi-Head Attention и архитектуры Feed Forward слоя, который может включать в себя несколько полносвязных слоев).
Обратите внимание: никакая из этих матриц никак не связана с количеством токенов, которое мы подаем на вход.
Мы рассмотрели один блок декодера, но обычно их несколько. Входные данные следующего декодера являются выходными данными текущего.
¶ Декодировщик и Masked Self Attention
Декодировщик использует все те же принципы, что и кодировщик. Есть два отличия:
- каждый декодировщик использует информацию с верхнего кодировщика (запросы и ключи)
- вместо обычного Self Attention декодировщик реализует Masked Self Attention; по сути - это то же самое, но здесь перед вычислением softmax правый верхний угол матрицы заполняется значениями -inf (симулируется ситуация, что декодировщик в момент обработки t-го токена не знает, какие токены будет дальше, и может сопоставлять t-й токен только с предыдущими).
Все остальные слои декодировщика работают аналогично кодировщику.
¶ Обучение и инференс Трансформера
Предположим, мы решаем задачу машинного перевода (генерация текста реализуется аналогично). Рассмотрим очередную итерацию обучения:
Обучение на данном примере реализуется за один шаг:
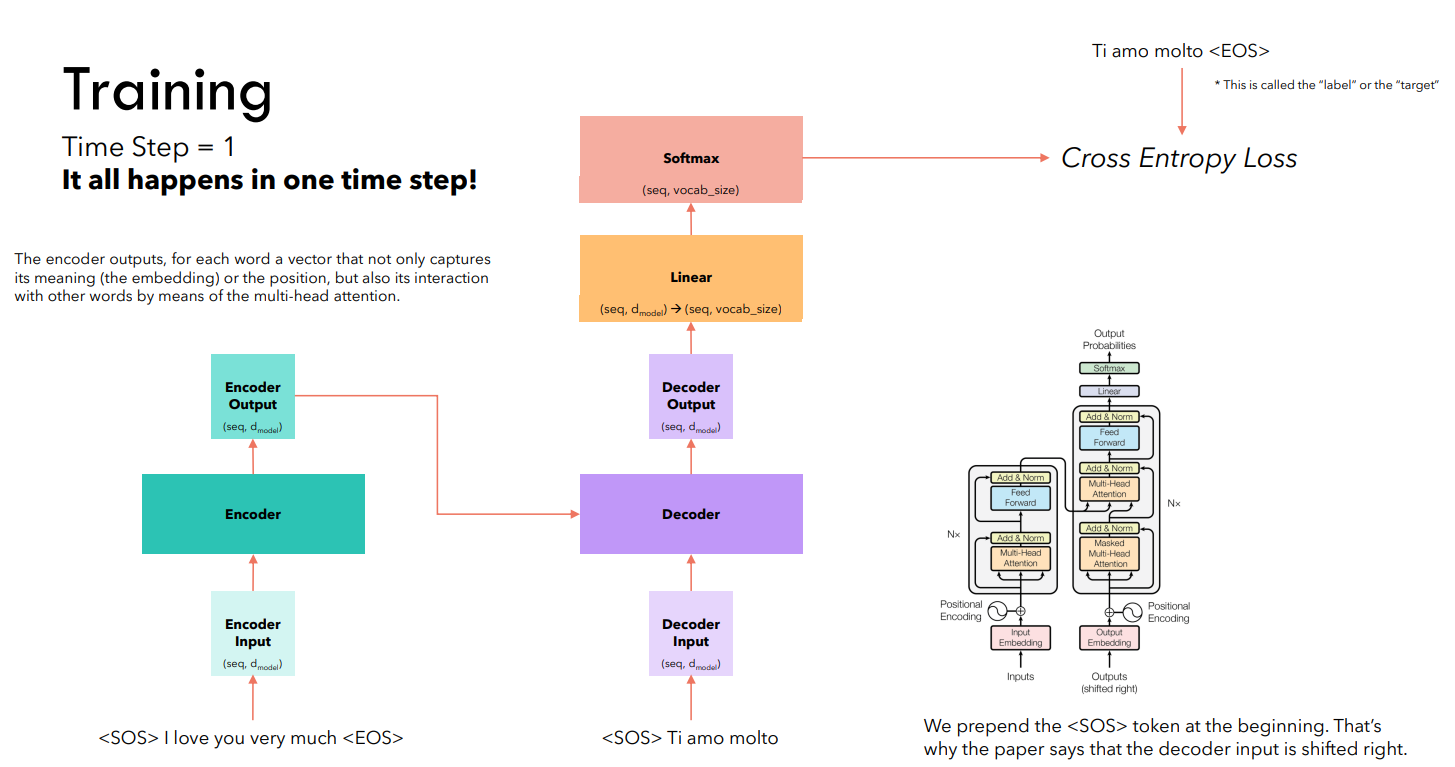
При работе с Трансформерами часто используют специальные токены (, и другие).
Выходы декодировщика обрабатываются минимум одним линейным слоем, который реализует трансформацию данных (переход к размерности словаря). Теперь для каждой строки полученной матрицы выполняется softmax, определяются индексы максимальных элементов, после чего вычисляется общая категориальная перекрестная энтропия.
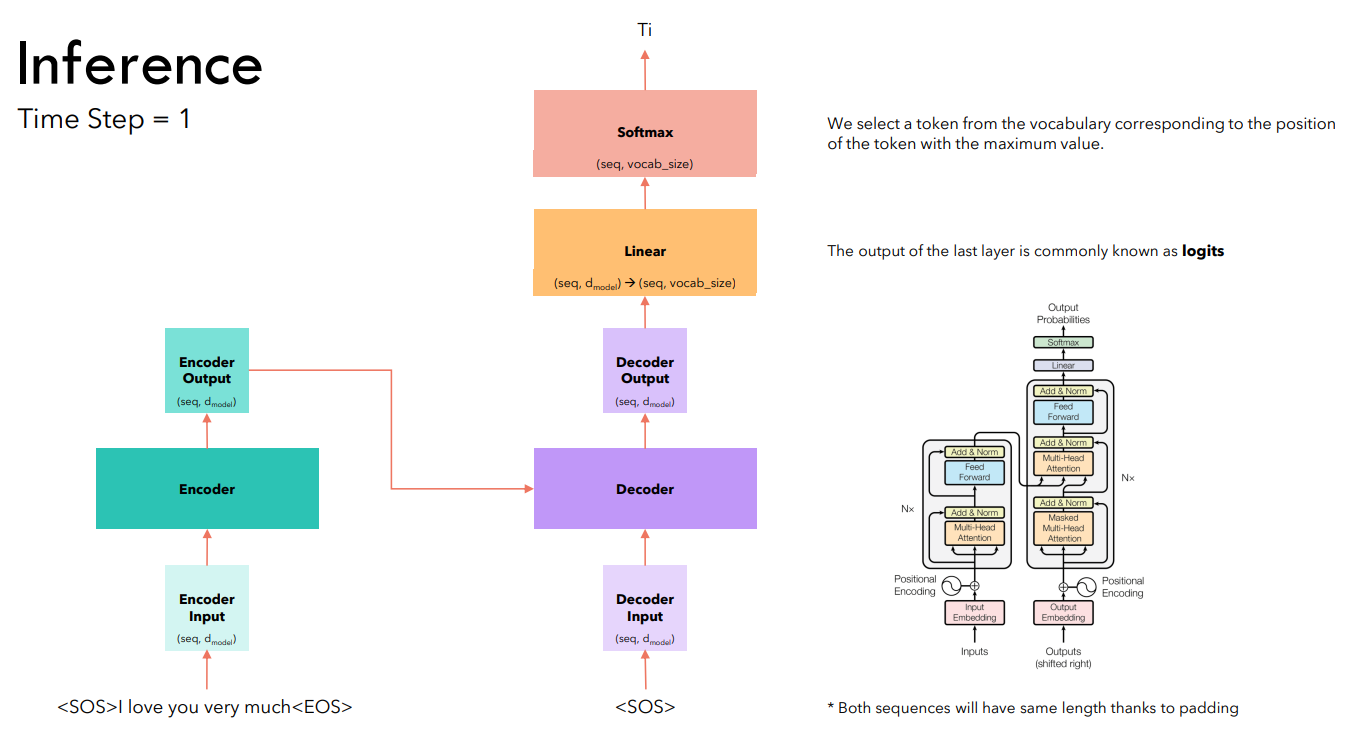
В отличие от обучения, инференс трансформера выполняется по шагам. На первом шаге получения предсказания мы подаем на вход декодера токен и предсказываем первый токен.
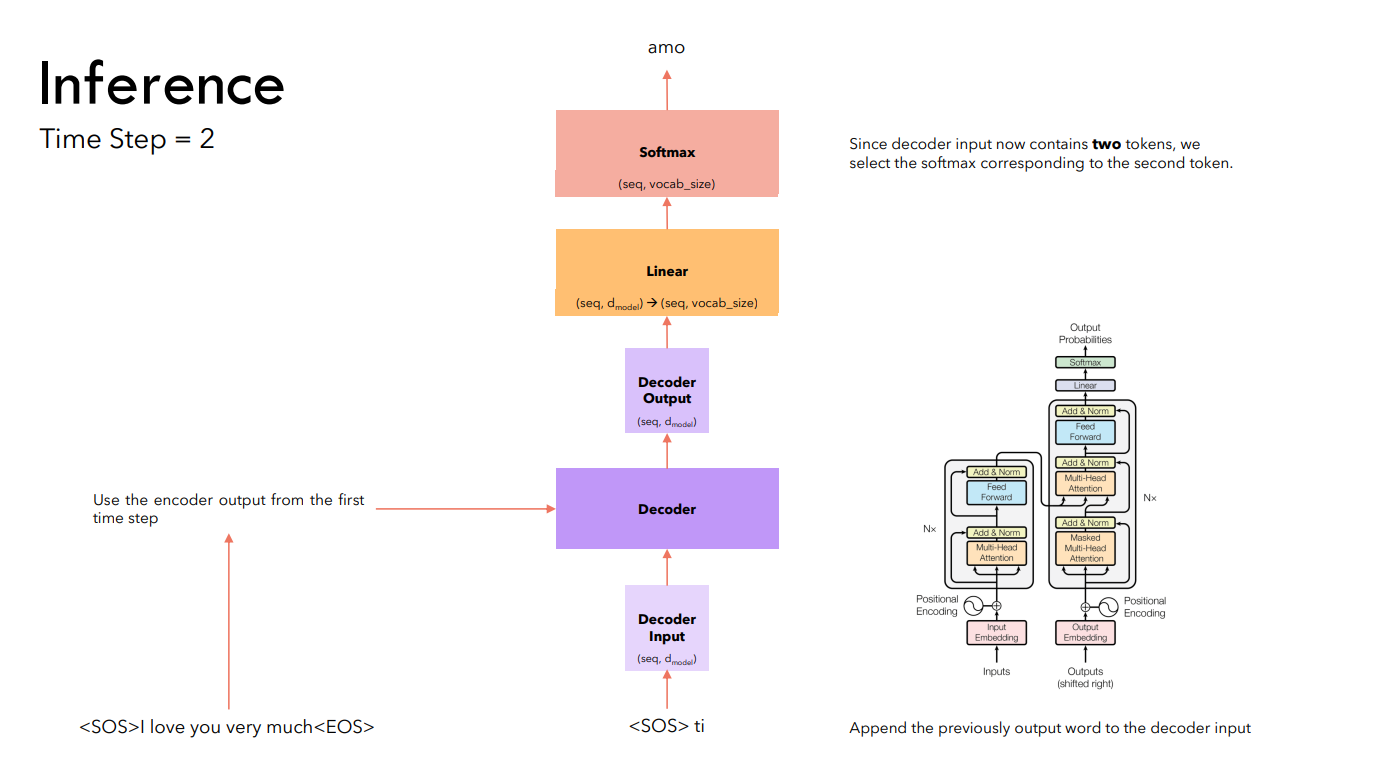
На последующих шагах мы подаем на вход декодеру всю сгенерированную им ранее последовательность. Продолжаем генерацию до тех пор, пока не будет предсказан токен .
Обратите внимание: выходом трансформера всегда является матрица, количество строк в которой равно количеству входящих в кодировщик токенов. На этапе инференса мы берем softmax только для той строки, номер которой соответствует номеру предсказываемого в данный момент токена.
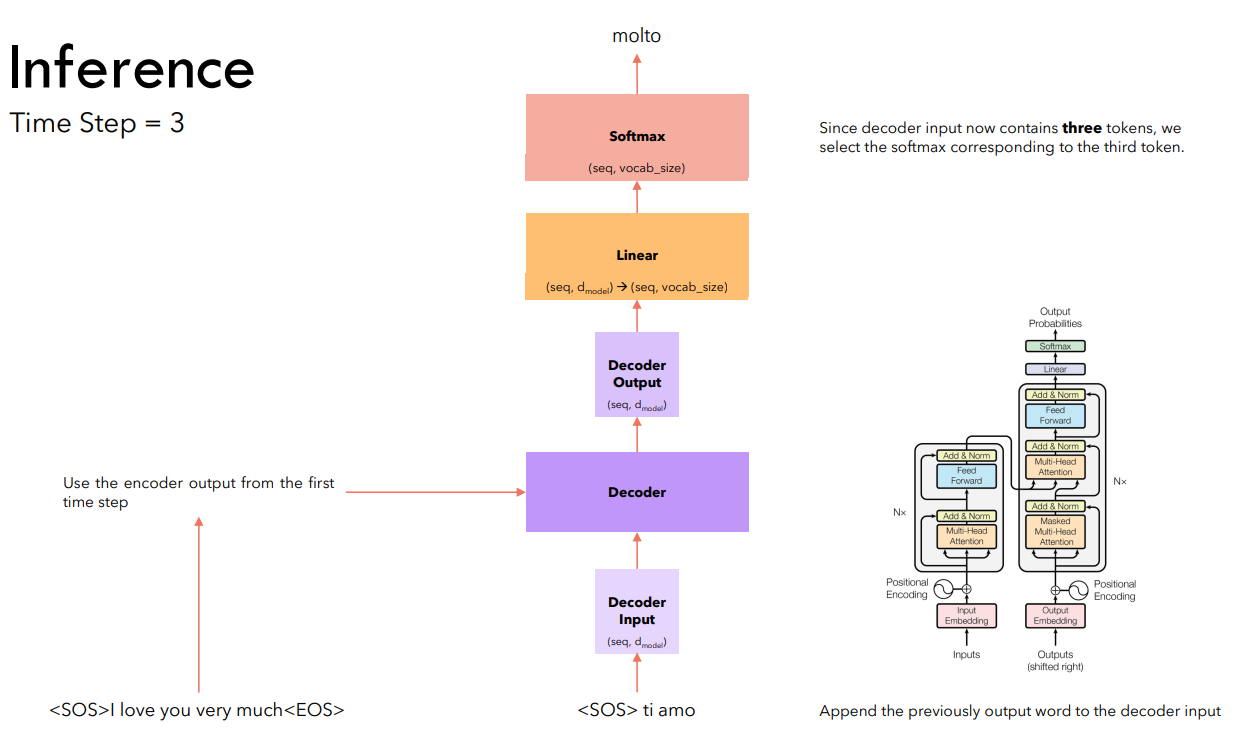
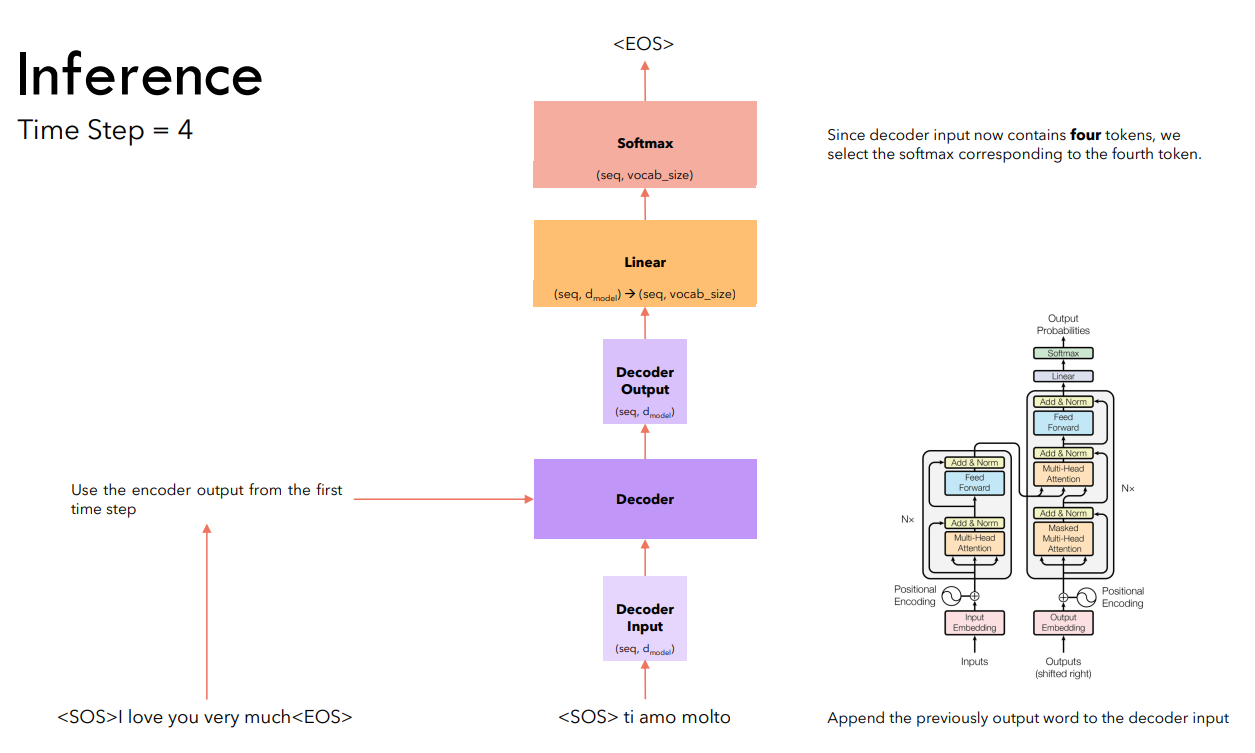
Предсказан токен , генерация останавливается.
Напоминаю, что при работе с Трансформерами (как и с рекуррентными моделями) целесообразно заранее определить максимальный размер генерируемой последовательности. В таком случае инференс заканчивается либо когда предсказывается токен , либо когда длина сгенерированной последовательности достигает максимального значения.
¶ Выводы
Представленная в 2017 году архитектура Трансформер наглядно показала, что эффективно решать задачи Seq2Seq можно без последовательной обработки последовательностей (ЛОЛ), а только с использованием внимания и классических нейронных сетей.
Трансформеры легко распараллеливаются, обучаются быстрее чем рекуррентные нейронные сети, могут масштабироваться.
Все современные модели в NLP построены на основе архитектуры Трансформер.
Среди них:
- BERT (включая модификации RoBERTa, DistilBERT) - Google
- GPT 2, 3, 3.5 (ChatGPT) - OpenAI
- DIET (фреймворк RASA) - RASA
- LLAMA - Meta (на момент написания материала деятельность компании в РФ запрещена)
Одним из амбассадоров использования Трансформеров сегодня является компания Hugging Face, авторы одноименного сайта, который стал домом для огромного количества самых современных моделей (не только NLP). Для удобного инференса и fine-tuning’а моделей с Hugging Face авторы ресурса написали отдельную библиотеку - transformers. Мы ее рассмотрим на последующих занятиях.
Направление fine-tuning’а трансформеров - основное направление в современном NLP. За счет этого появляются такие модели как SBERT, Sentence Transformers и другие.