¶ Цифровая обработка аудиоданных
В отличие от текста, который дискретен, звук представляет собой непрерывный во времени сигнал
Звук — распространение волн сжатия и разрежения в упругой среде (обычно в воздухе). Микрофон преобразует эти колебания давления в непрерывный электрический сигнал напряжения .
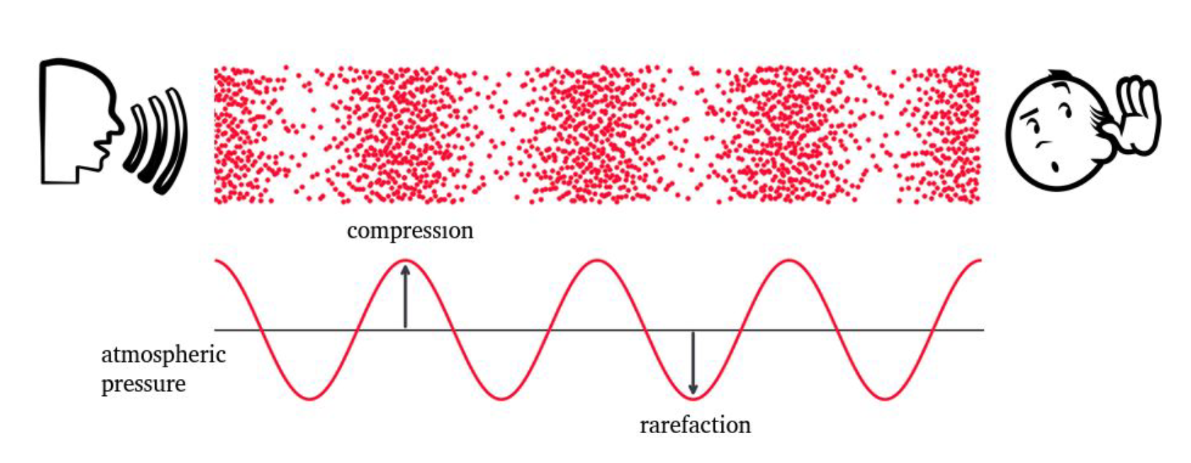
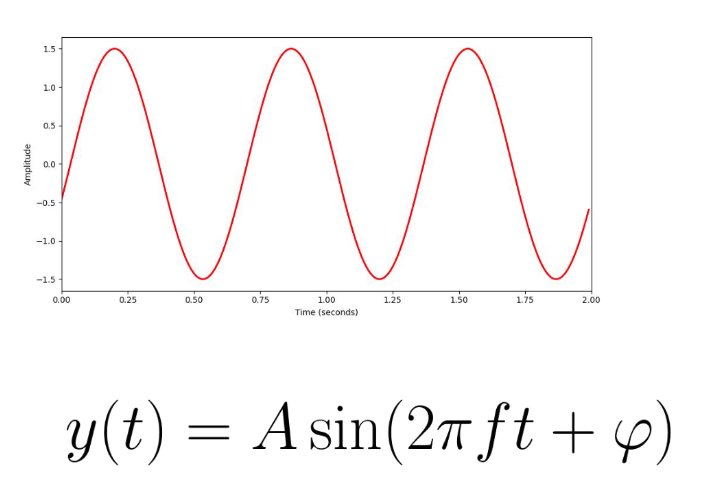
Звуковая волна характеризуется:
- частотой ( , - период);
- амплитудой ();
- фазой (, актуально когда звуковые волны накладываются друг на друга).
Для обработки на компьютерах аналоговый сигнал подвергается импульсно-кодовой модуляции (Pulse Code Modulation, PCM), которая состоит из двух ключевых этапов: дискретизации по времени и квантования по амплитуде.
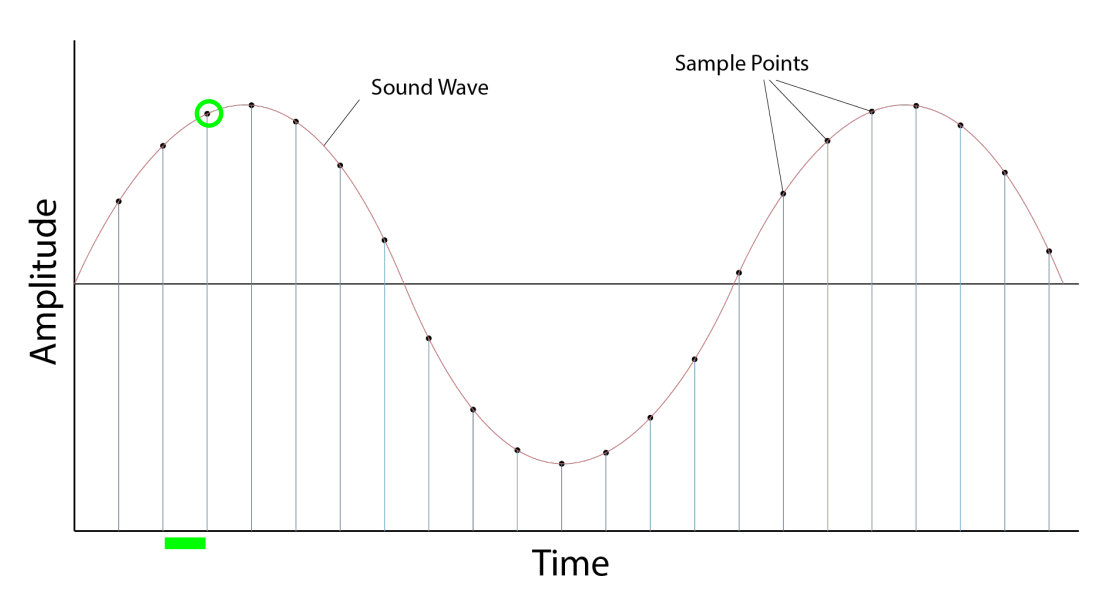
Дискретизация подразумевает измерение амплитуды сигнала через равные промежутки времени . Частота дискретизации определяет количество замеров (сэмплов) в секунду.
Фундаментальным ограничением здесь выступает Теорема Котельникова (Найквиста-Шеннона). Для точного восстановления непрерывного сигнала с ограниченным спектром из его дискретных отсчетов необходимо, чтобы частота дискретизации превышала удвоенную максимальную частоту спектра сигнала :
Человеческий слух воспринимает частоты в диапазоне от 20 Гц до 20 кГц. Стандарт CD-Audio (44.1 кГц) выбран для покрытия всего слышимого диапазона ( кГц). При этом в задачах распознавания речи (ASR) часто используется частота 16 кГц: основная фонетическая информация сосредоточена в диапазоне до 8 кГц. Использование 16 кГц снижает размерность входных данных и вычислительную нагрузку без существенной потери разборчивости речи.
Аудиотрек может интерпретироваться как временной ряд. А временные ряды - это последовательности. Значит, мы будем иметь дело с обработкой последовательностей
Каждый отсчет амплитуды должен быть представлен конечным набором бит. Квантование — нелинейное отображение непрерывного множества значений амплитуды на дискретное множество уровней. Если используется бит, диапазон амплитуд разбивается на уровней. Ошибка округления порождает шум квантования.
Важной метрикой является Отношение сигнала к шуму квантования (SQNR - Signal-to-Quantization-Noise Ratio). Для синусоидального сигнала полной амплитуды SQNR выражается формулой:
где — битовая глубина.
Каждый 1 дополнительный бит добавляет примерно 6 дБ чистоты (полезного сигнала) по сравнению с шумом
- 16 бит: дБ (стандарт для качественной записи)
- 8 бит: дБ (приемлемо для телефонии, но слышен явный шум)
В системах глубокого обучения данные обычно нормализуются в диапазон и представляются в формате с плавающей точкой (float32), однако исходная природа целочисленного квантования (int16 в формате WAV) определяет предельный динамический диапазон сигнала.
Речевой сигнал является нестационарным: его спектральные характеристики быстро меняются во времени по мере смены фонем. Применение преобразования Фурье (DFT) ко всему сигналу целиком уничтожило бы информацию о времени. Спектр предложения покажет, какие частоты в нем присутствовали, но не когда они звучали.
Решением является предположение о квазистационарности речи на коротких промежутках времени (20–40 мс). В пределах такого окна слух человека не успевает существенно изменить конфигурацию и сигнал можно считать стационарным.
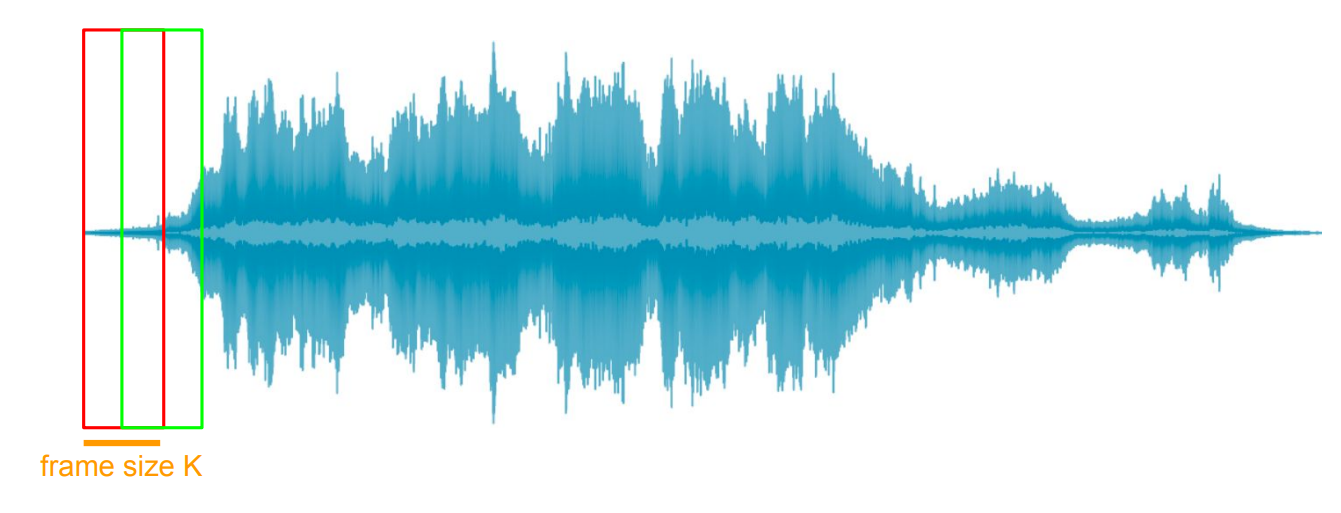
Предполагается, что все фреймы содержат одинаковое количество точек дискретизации. Если последний фрейм получается короче остальных - применяется паддинг (как правило, происходит заполнение нулями).
¶ Извлечение признаков
Кратковременное преобразование Фурье (Short-Time Fourier Transform, STFT) является фундаментом обработки аудио. Сигнал разбивается на перекрывающиеся сегменты (фреймы), и к каждому применяется дискретное преобразование Фурье (Discrete Fourier Transform, DFT).
STFT для сигнала определяется следующим образом:
Здесь:
- — индекс временного фрейма
- — индекс частотного бина ()
- — сегмент сигнала, сдвинутый на шаг (hop length), обычно составляет 10–15 мс (160 сэмплов при 16 кГц)
- — оконная функция длины (окно Ханна или Хэмминга)
- — размерность FFT (как правило, степень двойки: 512, 1024).
При заданных параметрах результатом преобразования является матрица размерности
(frequency bins, frames). В ячейках матрицы - интенсивность данной полосы в данном фрейме
Результат — комплексное число. Модуль характеризует громкость. Квадрат модуля называется спектрограммой мощности:
Возведение модуля в квадрат переводит физическую величину из амплитуды в энергию.
Это представление можно интерпретировать как двумерное изображение, где интенсивность пикселя отражает энергию
Восприятие высоты звука человеком нелинейно. Различие между 100 Гц и 200 Гц воспринимается как значительное, тогда как различие между 10000 Гц и 10100 Гц практически неразличимо. Шкала мелов (Mel Scale, от Melody) аппроксимирует данную психоакустическую особенность слуха.
Перевод частоты (Гц) в мелы :
Обратное преобразование:
Для получения признаков, подаваемых на вход ML-моделям, спектрограмма мощности пропускается через набор треугольных фильтров, распределенных равномерно по шкале мелов. Это снижает размерность по оси частот (с 513 бинов до 80 мел-каналов) и учитывает особенности восприятия.
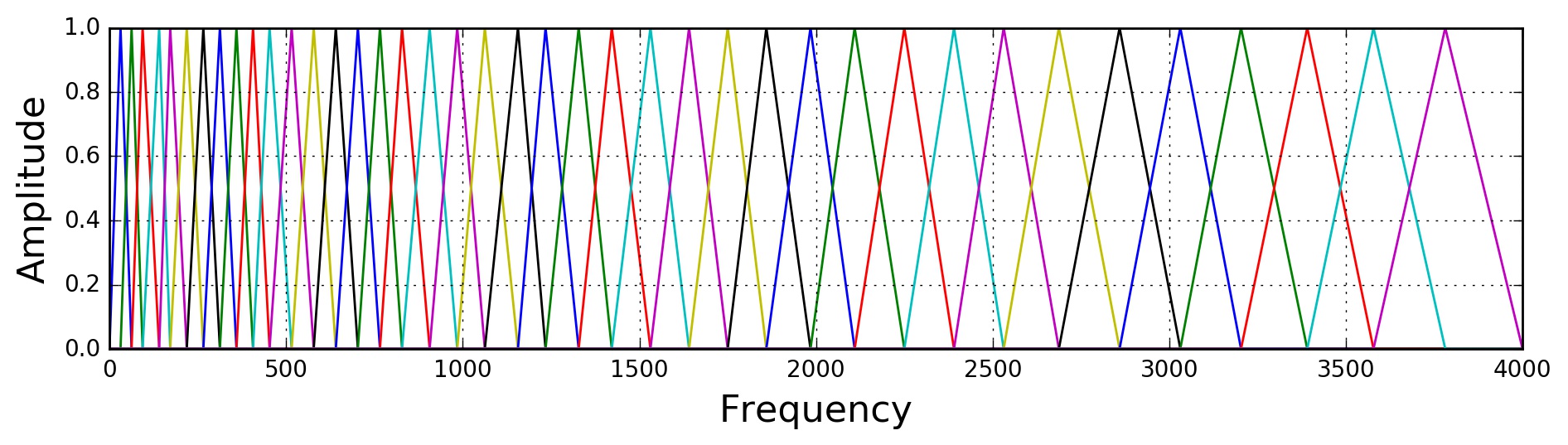
Треугольники должны быть равнобедренными и одинаковой ширины
Берем диапазон частот (допустим, от 0 Гц до 8000 Гц), переводим границы в мелы. Разбиваем диапазон на равных отрезков ( — количество фильтров). Если нужно 40 фильтров, потребуется 42 точки (границы + пики). Точка — центр -го треугольника, а также вершина для соседей.
Переводим равномерные точки обратно в Герцы (после обратного перевода точки перестанут быть равномерными). Округляем частоты до ближайшего номера бина :
Теперь у нас есть список координат вершин треугольников в номерах бинов. Для каждого фильтра вычисляем вес для каждого частотного бина .
Треугольник задается тремя точками:
- (левый край, вес 0)
- (пик, вес 1)
- (правый край, вес 0)
Формула веса :
Если бин находится на пике (), то вес равен 1.0. Если бин находится ровно посередине между краем и пиком, то вес равен 0.5. Если бин за пределами треугольника, то вес 0.
Формула мел-спектрограммы:
Здесь — спектрограмма мощности.
Если фильтр широкий, то суммируем энергию сотни бинов в одно число. Если фильтр узкий, то берем энергию всего пары бинов.
В некоторых реализациях (в librosa) треугольники дополнительно нормализуют по площади. Широкие треугольники захватывают больше бинов чем узкие. Если оставить пик всегда равным 1.0, то в высокочастотных фильтрах сумма энергии будет огромной (просуммировали больше слагаемых). Чтобы энергия была согласована, высоту широких треугольников делают меньше (они становятся низкими и широкими), а узких — больше.
Log-Mel Spectrogram (логарифмическая мел-спектрограмма) является стандартом входных данных для современных моделей (Tacotron 2, Whisper и др.).
Здесь необходим, чтобы не получить при логарифме нуля.
Извлечение и визуализация мел-спектрограммы:
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
def extract_and_plot_features(audio_path):
SR = 16000
N_FFT = 400
HOP_LENGTH = 160
N_MELS = 80
y, _ = librosa.load(audio_path, sr=SR)
mel_spec = librosa.feature.melspectrogram(
y=y,
sr=SR,
n_fft=N_FFT,
hop_length=HOP_LENGTH,
n_mels=N_MELS,
power=2.0
)
log_mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
plt.figure(figsize=(12, 4))
librosa.display.specshow(
log_mel_spec,
sr=SR,
hop_length=HOP_LENGTH,
x_axis='time',
y_axis='mel',
)
plt.colorbar(format='%+2.0f dB')
plt.title('Log-Mel Spectrogram (80 бинов)')
plt.tight_layout()
plt.show()
filename = librosa.ex('trumpet')
extract_and_plot_features(filename)
Отображение плеера в IPython:
Audio(data=y, rate=sr)
Очень часто студенты используют другой тип входных данных — MFCC.
Мел-частотные кепстральные коэффициенты (MFCC — Mel-frequency cepstral coefficients) — максимально сжатая и очищенная версия мел-спектрограммы.
Голос состоит из двух компонентов:
Источник (Source)
Голосовые связки вибрируют и создают жужжание. Это определяет высоту голоса.
Фильтр (Filter)
Горло, язык, зубы и губы вырезают из жужжания конкретные частоты, превращая его в звуки «А», «О», «Ш». Это определяет смысл.
Цель MFCC — отделить смысл от индивидуальности голоса, чтобы компьютер понимал слова, независимо от того, кто их говорит.
MFCC получаются, если к Log-Mel спектрограмме применить дискретное косинусное преобразование (DCT)
Пусть есть вектор логарифмических энергий с мелов (Log-Mel) для одного кадра. Обозначим его , где — номер мел-фильтра (от до ). Тогда -й кепстральный коэффициент вычисляется так:
Обычно меняется от 0 до 12 (итого 13 коэффициентов)
Низкие значения (0–12) описывают общую форму спектра. Это звуки речи (форманты). Высокие (20–40) описывают быструю шум и индивидуальные особенности связок.
Сверточные нейронные сети умеют самостоятельно находить зависимости между соседними пикселями. Удаляя высокие частоты через MFCC, можем выкинуть что-то важное. В современных моделях глубокого обучения MFCC почти не используют. При этом эти коэффициенты используются при обучении традиционных моделей ML (ансамбли деревьев, SVM).
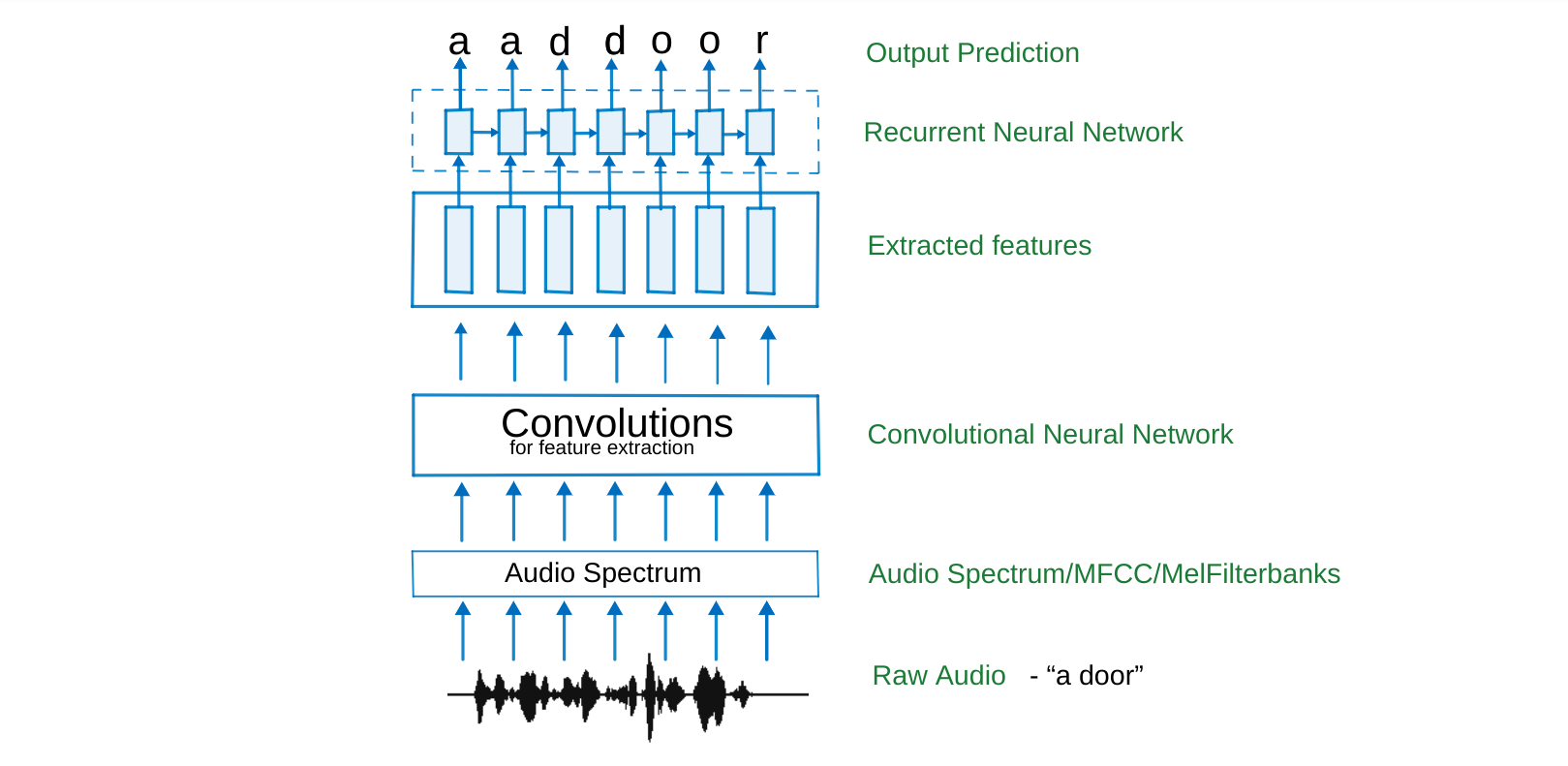
¶ Автоматическое распознавание речи
Задача Speech-to-Text (Automatic Speech Recognition, ASR) формулируется как поиск наиболее вероятной последовательности символов или слов для заданной входной последовательности акустических признаков :
Фундаментальная сложность ASR заключается в проблеме выравнивания (alignment). Длина входной последовательности (количество фреймов спектрограммы) всегда значительно больше длины выходной последовательности (количество букв). Слово "cat" может длиться 500 мс (50 фреймов по 10 мс), но состоит всего из 3 букв.
Мы не знаем, какой фрейм соответствует какой букве.
Коннекционистская временная классификация (Connectionist Temporal Classification, CTC, 2006) позволяет обучать нейронные сети предсказывать последовательность символов без явной разметки границ фонем.
CTC вводит специальный служебный символ blank, который обозначается как или -. Для каждого временного шага нейросеть предсказывает распределение вероятностей по расширенному словарю .
Пусть сеть выдает последовательность , где . Определим функцию отображения , которая работает в два этапа:
- объединение подряд идущих одинаковых символов
- удаление символов .
Примеры:
Наличие позволяет разделить две одинаковые буквы (например, в слове "cooperation")
Вероятность целевой последовательности определяется как сумма вероятностей всех возможных путей , которые сводятся к после применения :
Вероятность конкретного пути:
Функция потерь CTC (CTC Loss) — отрицательный логарифм правдоподобия:
Прямое суммирование по всем путям невозможно, так как их количество растет экспоненциально с . Используется алгоритм Forward-Backward.
Есть сетка:
- ось X — временные шаги () от аудио
- ось Y — расширенная целевая последовательность ()
Движение по сетке возможно только слева-направо (по времени) и только вниз (по последовательности символов), с определенными правилами переходов.
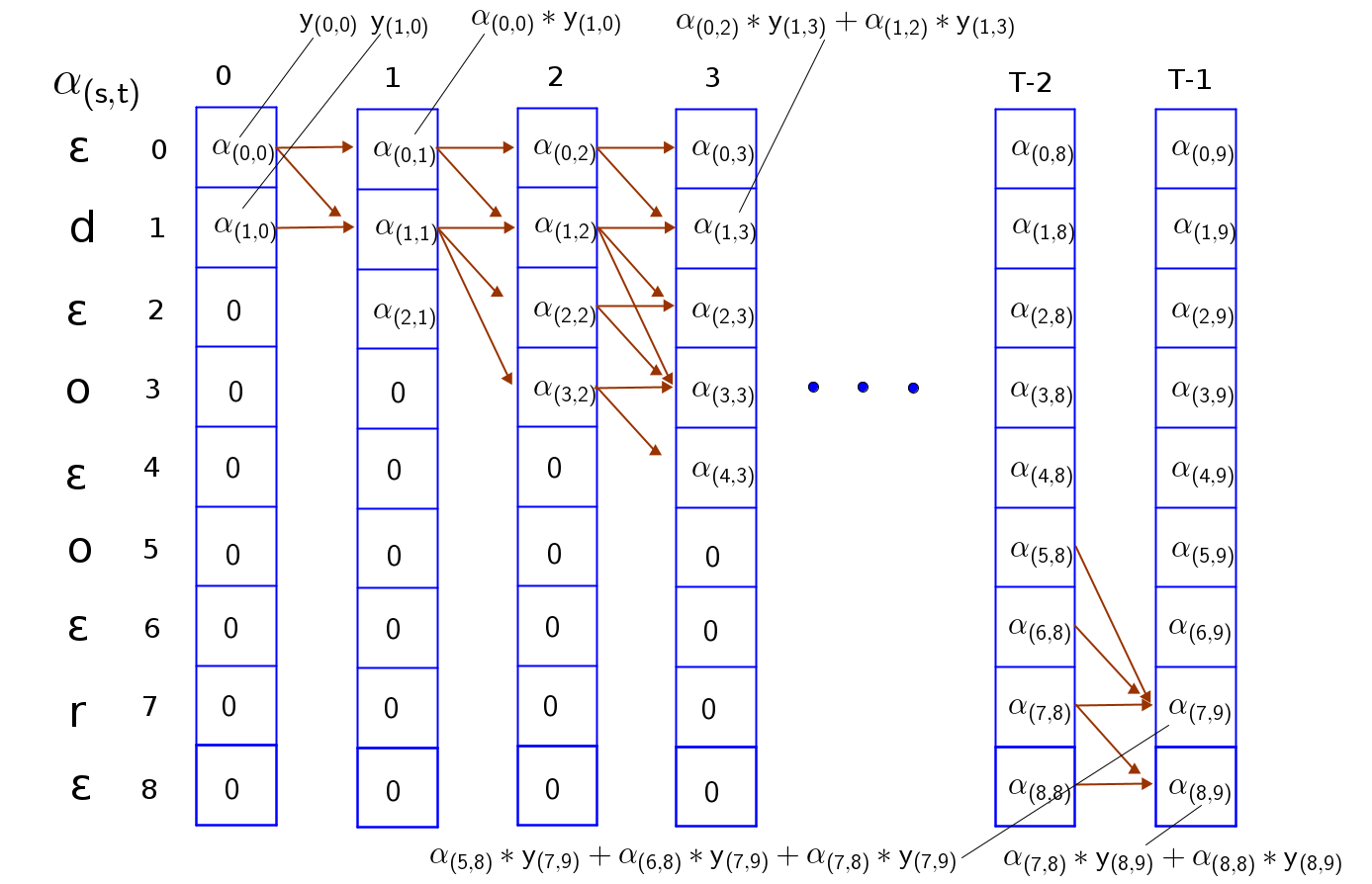
Переменная представляет собой вероятность того, что часть последовательности от начала до символа была распознана к моменту времени . Можем начать только с первого символа (- или первый значимый символ) в момент .
Чтобы вычислить суммируем вероятности прихода в это состояние из предыдущих допустимых состояний на шаге :
- мы могли остаться в том же символе ()
- мы могли прийти из предыдущего символа ()
- если текущий символ не и не совпадает с символом , то мы могли перепрыгнуть через blank, придя сразу из
Переменная делает то же самое, но в обратном направлении. Она показывает вероятность завершения оставшейся части последовательности (от до конца), начиная с момента времени . Начинаем с конца времени и последних возможных символов последовательности. Двигаемся назад во времени (от к ), вычисляя вероятность успешного завершения пути из текущей точки. Правила переходов аналогичны.
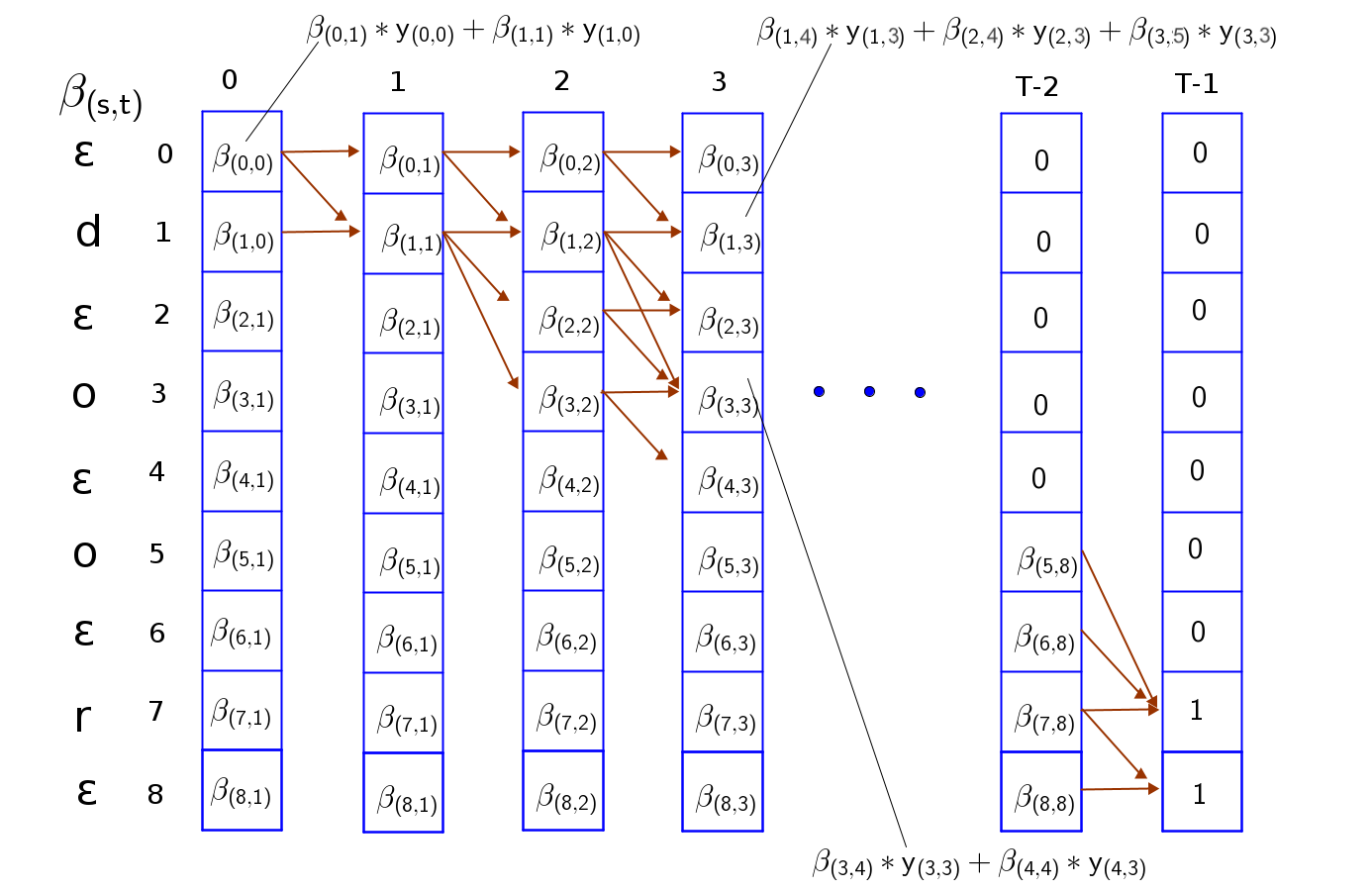
Имея значения и для каждой точки , можем вычислить полную вероятность прохождения верного пути через этот конкретный символ в момент :
Суммирование этих вероятностей позволяет получить общую вероятность пути для данного входа
Почитать про CTC можно здесь и здесь. В PyTorch присутствует абстракция nn.CTCLoss.
Для получения финального текста из выходов сети могут использоваться уже знакомые нам стратегии декодирования (жадный поиск, лучевой поиск, семплирование)
¶ Wav2Vec
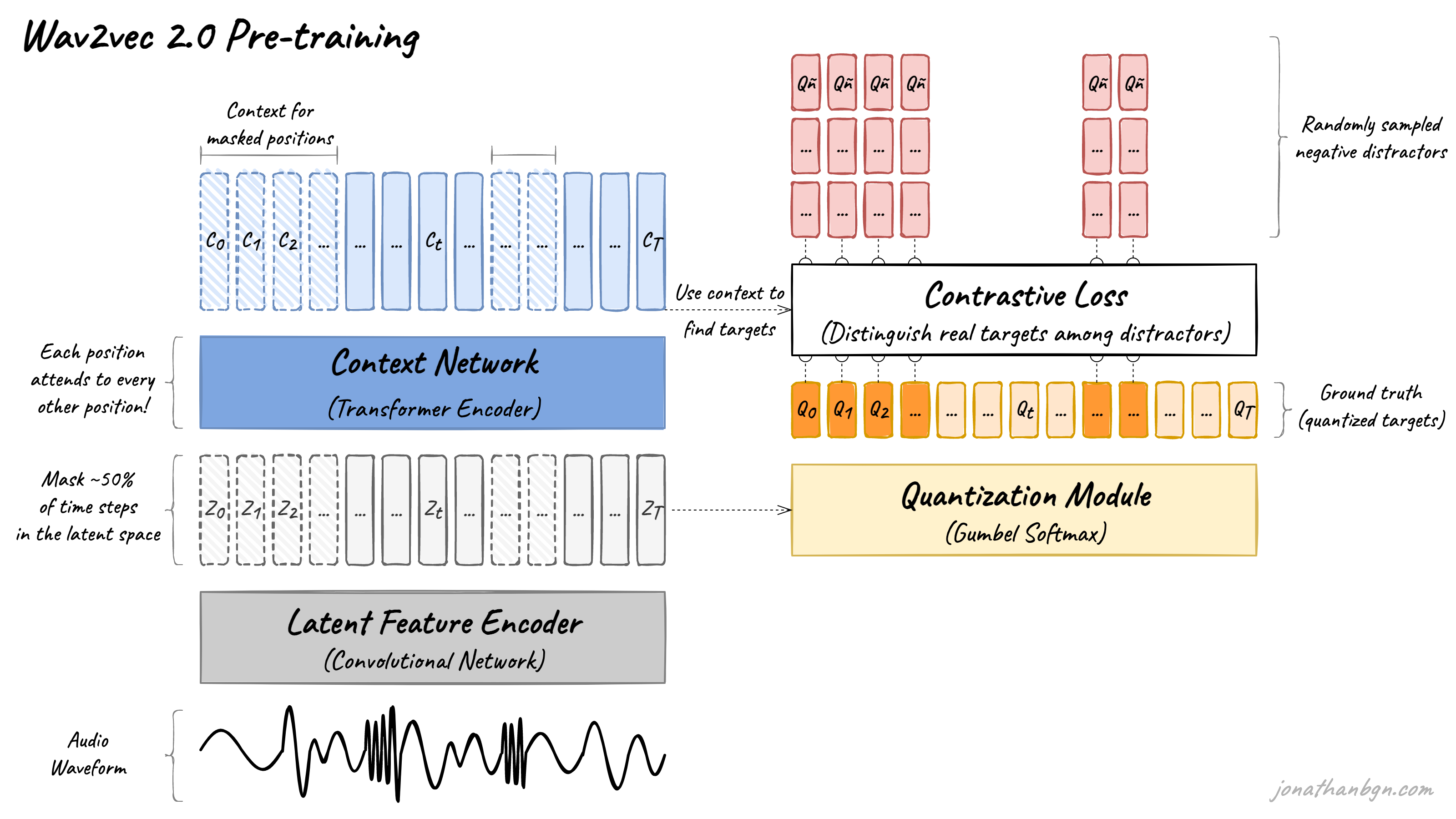
Оригинальное исследование 2020 г.
Audio Waveform
На вход подается сырой звук (НЕ спектрограмма).
Latent Feature Encoder
Сверточная сеть. Превращает волну в последовательность латентных векторов .
Masking
Примерно 50% временных шагов скрываются (заменяются на специальный токен).
Context Network
Кодировщик трансформера. Анализирует всю последовательность. На выходе получаются контекстные вектора . Для замаскированных позиций вектор — попытка модели угадать, что там было, основываясь на окружающих звуках.
Quantization Module
Сюда поступают оригинальные, немаскированные вектора . Используя метод Gumbel Softmax, непрерывные вектора превращаются в дискретные значения .
Задача модели — для маскированного шага предсказать правильный квантованный вектор среди набора дистракторов (негативных примеров, взятых из других частей аудио):
Здесь — косинусная близость, — температура.
Мне очень нравится термин "акустический токен"
При дообучении используется только слой Context Network (функция потерь CTC Loss). Это существенно уменьшает необходимый объем текстовых данных для дообучения.
¶ Whisper
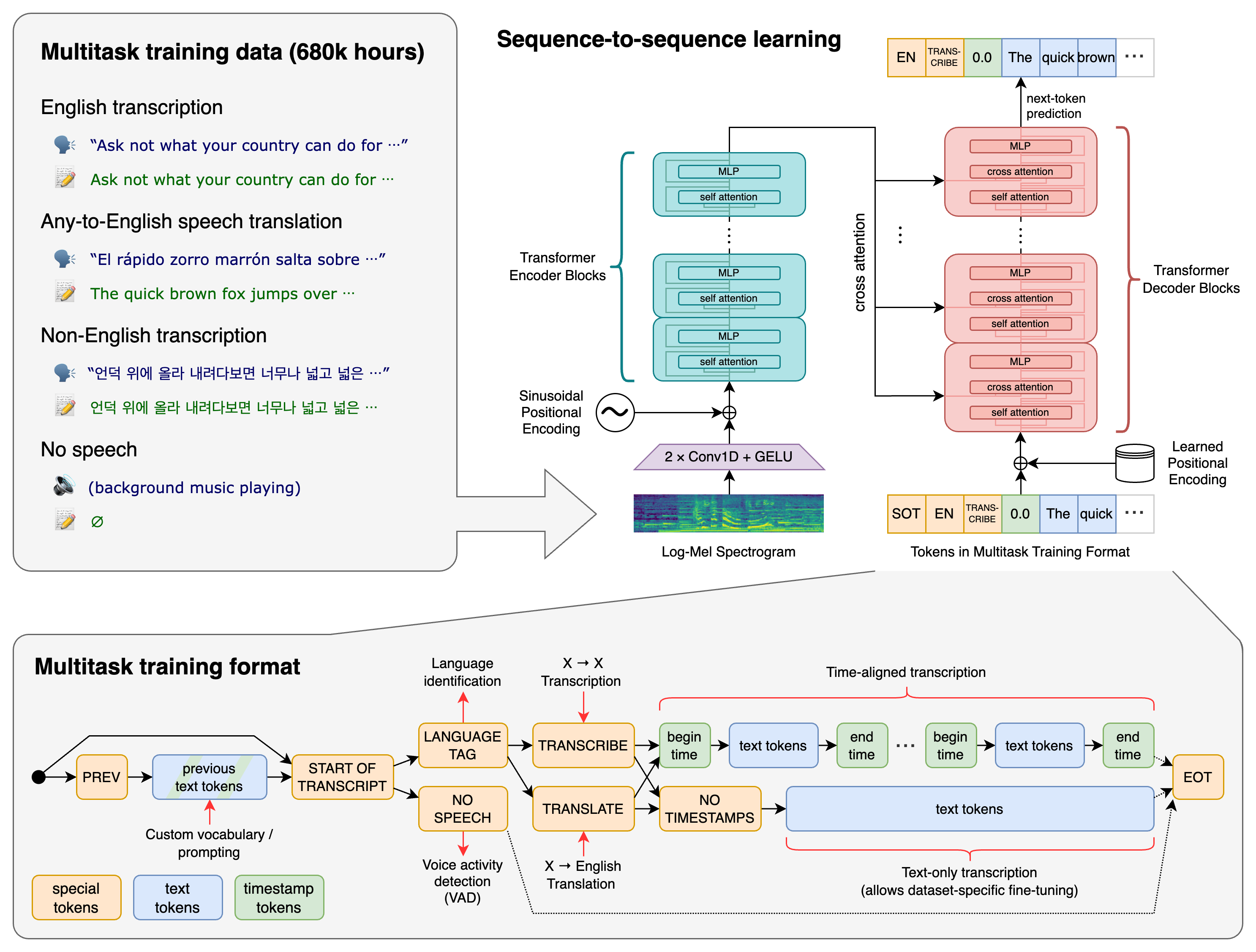
Оригинальное исследование 2022 г.
Одна модель может выполнять разные задачи без изменения весов:
<|transcribe|> — транскрипция (ASR)
<|translate|> — перевод речи на английский
<|timestamps|> — предсказание временных меток
Модель генерирует текст токен за токеном точно так же, как это делает GPT
¶ Синтез речи
Задача Text-To-Speech обратна ASR: преобразование текста в акустическую волну. Конвейрер обычно состоит из двух независимыхмоделей:
Acoustic Model
Преобразует текст в мел-спектрограмму (FastSpeech 2, оригинальное исследование 2020 г.)
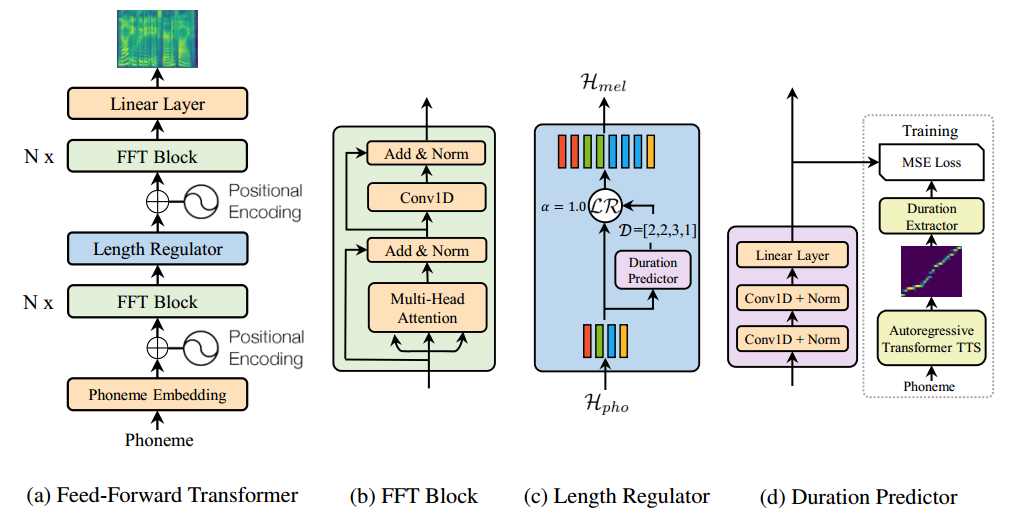
Vocoder
Преобразует мел-спектрограмму в звуковую волну (HiFi GAN, оригинальное исследование 2020 г.)
Пример с официального сайта PyTorch
Мой пример:
from transformers import pipeline
import scipy
synthesiser = pipeline('text-to-speech', 'facebook/mms-tts-rus')
speech = synthesiser('Приятного аппетита тем, кто кушает! А тем, кто еще и пьет - РЕСПЕКТ')
scipy.io.wavfile.write('respect.wav', speech['sampling_rate'], data=speech['audio'][0])