¶ Введение
В основе классических архитектур нейронных сетей, таких как многослойные перцептроны (MLP), лежит предположение о независимости входных данных. Каждый входной пример обрабатывается изолированно, без учета его связи с предыдущими или последующими примерами.
Этот подход эффективен для множества задач, однако он оказывается нецелесообразен к применению при работе с последовательными данными (текст, речь, временные ряды). Здесь порядок элементов имеет решающее значение: изменение порядка слов в предложении может кардинально изменить его смысл.
Рекуррентные нейронные сети (Recurrent Neural Networks, RNN) разработаны для решения этой проблемы. Rлючевая особенность — наличие внутреннего состояния ("памяти"), которое передаётся от одного временного шага к другому. На каждом шаге обработки элемента последовательности (например, "токена") сеть принимает на вход не только сам элемент, но и своё состояние с предыдущего шага.
Это позволяет сети накапливать информацию о предшествующем контексте и использовать её при интерпретации текущего элемента.
RNN не просто модель для статического отображения входа на выход, . Она обучается моделировать динамическую систему, , где — состояние системы в момент времени .
¶ Сеть Элмана
Простейшая и наиболее распространенная архитектура РНС — сеть Элмана. Ячейку можно представить как блок, который получает на вход текущий элемент последовательности и скрытое состояние с предыдущего шага , а на выходе производит обновлённое скрытое состояние и, возможно, выход .
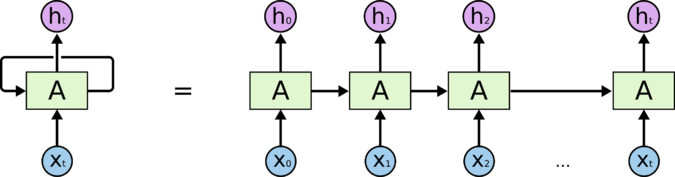
Для понимания процесса обучения и работы сети её "разворачивают" во времени. Развернутая сеть представляет собой глубокую нейронную сеть, где каждый временной шаг становится отдельным слоем. Важнейшей особенностью является то, что веса на всех этих "слоях" (временных шагах) являются общими.
¶ Вычисление скрытого состояния
- — вектор скрытого состояния в момент времени , где — размерность скрытого слоя
- — вектор скрытого состояния с предыдущего шага
- — входной вектор в момент времени , где — размерность входа (эмбеддинга токена)
- — матрица весов для рекуррентного соединения (от к )
- — матрица весов для входного соединения (от к )
- — вектор смещения (
bias) для скрытого слоя tanh— функция активации (гиперболический тангенс), которая ограничивает значения скрытого состояния диапазоном от -1 до 1
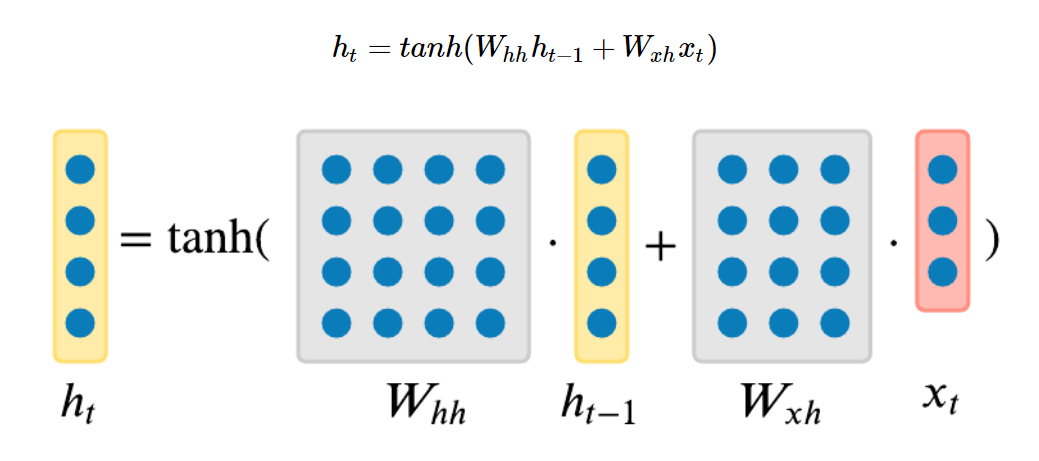
¶ Вычисление выхода
- — выходной вектор в момент времени , где — размерность выхода
- — матрица весов для выходного слоя
- — вектор смещения для выходного слоя
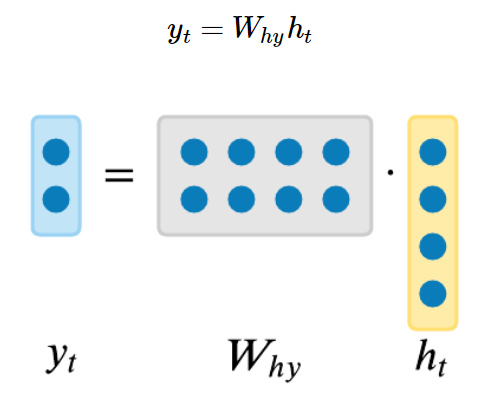
Использование общих весов на всех временных шагах является одновременно и главной силой, и основной слабостью простой RNN
С одной стороны, это позволяет модели обобщаться на последовательности произвольной длины, изучая универсальное правило обновления состояния. Без общих весов модель могла бы работать только с последовательностями фиксированной длины и не смогла бы выучить общую динамику процесса. С другой стороны, именно это свойство является причиной проблемы нестабильности градиентов.
Особого внимания заслуживают двунаправленные RNN (Bidirectional RNNs, BiRNN). Состоят из двух независимых RNN: одна обрабатывает последовательность в прямом порядке (от начала к концу), вторая — в обратном. Это позволяет модели учитывать не только прошлый, но и будущий контекст, что критически важно для таких задач, как определение частей речи или распознавание именованных сущностей.
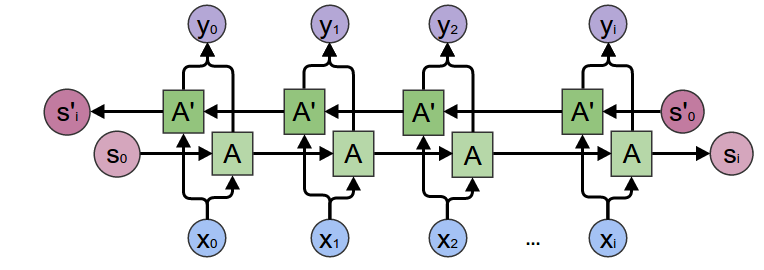
Виды рекуррентных нейронных сетей:
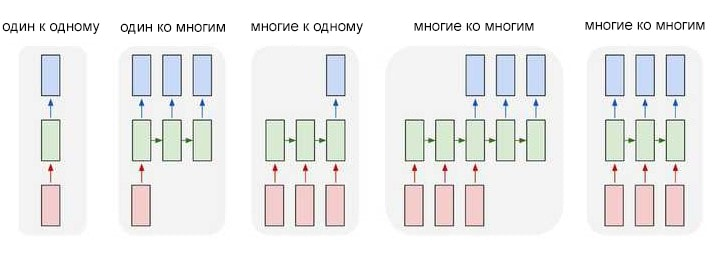
¶ Проблемы долгосрочных зависимостей
Алгоритм Backpropagation Through Time (BPTT)
Обучение RNN производится с помощью алгоритма обратного распространения ошибки во времени. Это стандартный алгоритм backpropagation, применяемый к развёрнутой во времени сети. Процесс выглядит следующим образом:
- сеть "разворачивается" на всю длину последовательности
- выполняется прямой проход: начиная с , последовательно вычисляются все и до конца последовательности
- вычисляется функция потерь , обычно как сумма потерь на каждом временном шаге
- выполняется обратный проход: градиенты распространяются от конца развернутой сети к её началу
- градиенты для общих весов () суммируются со всех временных шагов, где эти веса использовались
- веса обновляются с помощью градиентного спуска
В ходе обратного прохода возникает проблема, препятствующая обучению RNN на длинных последовательностях (проблема исчезающих и взрывающихся градиентов)
При вычислении градиента функции потерь по отношению к скрытому состоянию на некотором предыдущем шаге (где ), по цепному правилу получаем произведение:
Каждый член в этом произведении равен . Градиент зависит от многократного умножения матрицы весов на саму себя. Если сингулярные значения этой матрицы (квадратные корни из собственных чисел симметричной матрицы ) больше 1, норма градиента будет расти экспоненциально. Если они меньше 1, градиент будет экспоненциально затухать.
Кроме того производная гиперболического тангенса всегда меньше 1 (что будет приводить к затуханию градиентов):
Таким образом:
- Исчезающий градиент (Vanishing Gradient): градиенты от далёких по времени событий становятся пренебрежимо малыми к моменту, когда они достигают начала последовательности; сеть неспособна уловить связь между событиями, разделёнными большим временным лагом, не может обучиться долгосрочным зависимостям
- Взрывающийся градиент (Exploding Gradient): градиенты становятся аномально большими, что приводит к резким, нестабильным обновлениям весов; процесс обучения расходится: функция потерь может принимать значения ; наиболее распространённый метод борьбы — обрезка градиентов (Gradient Clipping), который заключается в масштабировании градиентов, если их норма превышает определенный порог
Для снижения вычислительной нагрузки и частичного смягчения проблем градиентов на практике часто используется усеченный BPTT (Truncated BPTT), где обратное распространение ошибки ограничивается лишь несколькими последними временными шагами.
¶ Продвинутые архитектуры RNN
¶ Long-Short Term Memory (LSTM)
Для борьбы с проблемой исчезающего градиента в 1997 году Sepp Hochreiter и Jürgen Schmidhuber предложили новую архитектуру.
Чтобы градиент не затухал при обратном распространении во времени, авторы предложили создать внутри ячейки путь, по которому ошибка может проходить без изменений (Constant Error Carousel, CEC)
LSTM-ячейка была дополнена механизмом вентилей (gates), которые представляют собой небольшие нейронные сети с сигмоидной активацией. Сигмоида выдает значения в диапазоне от 0 до 1, которые используются для поэлементного умножения, позволяя контролировать поток информации: 0 означает "полностью заблокировать", 1 — "полностью пропустить".
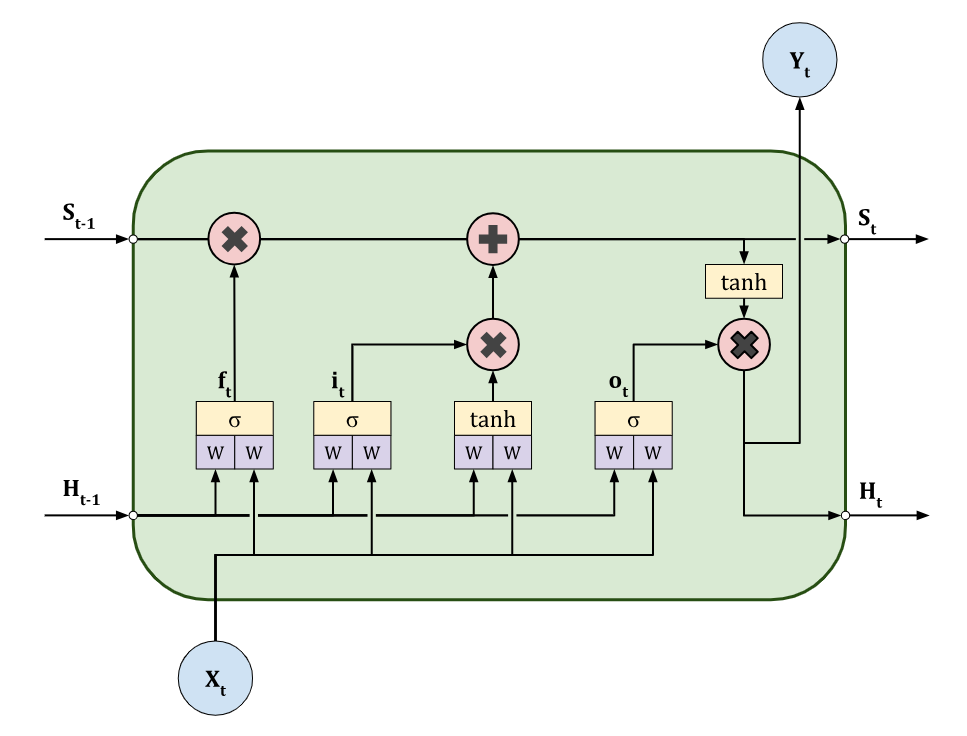
Архитектура LSTM разделяет "память" на два ключевых компонента:
Состояние ячейки (Cell State, S): "информационная магистраль" или "конвейер", реализующий идею CEC. Вектор несет информацию сквозь всю последовательность, и его изменения носят в основном аддитивный характер, что защищает от исчезновения градиентов; долгосрочная память
Скрытое состояние (Hidden State, H): "рабочая" или краткосрочная память; используется для вычисления выхода на текущем шаге и для управления вентилями на следующем
Формулы:
Вентиль забывания (Forget Gate, ): решает, какую информацию из предыдущего состояния ячейки следует отбросить
Вентиль входа (Input Gate, ) и кандидат на добавление (): определяют, какая новая информация будет сохранена в состоянии ячейки
Обновление состояния ячейки (Cell State Update): старое состояние умножается на вентиль забывания , а к результату прибавляется новая информация
Здесь обозначает поэлементное умножение (произведение Адамара)
Вентиль выхода (Output Gate, ) и скрытое состояние (): определяют, какая часть состояния ячейки будет передана на выход в виде скрытого состояния
Здесь обозначает конкатенацию векторов.
¶ Gated Recurrent Unit (GRU)
В 2014 году Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho и Yoshua Bengio представили облегчённую версию LSTM, которая демонстрирует сопоставимую производительность, при этом является более вычислительно эффективной и требует меньше параметров.
Основные изменения:
- отсутствие состояния ячейки: GRU не имеет отдельного вектора состояния ячейки; его функции выполняет само скрытое состояние
- два вентиля вместо трех: вентили забывания и входа объединены в один вентиль обновления (update gate); также вводится новый вентиль сброса (reset gate)
Связывание операций забывания и добавления новой информации через единый вентиль обновления действует как форма регуляризации. Модель не может одновременно "сильно забывать" старое и "сильно добавлять" новое
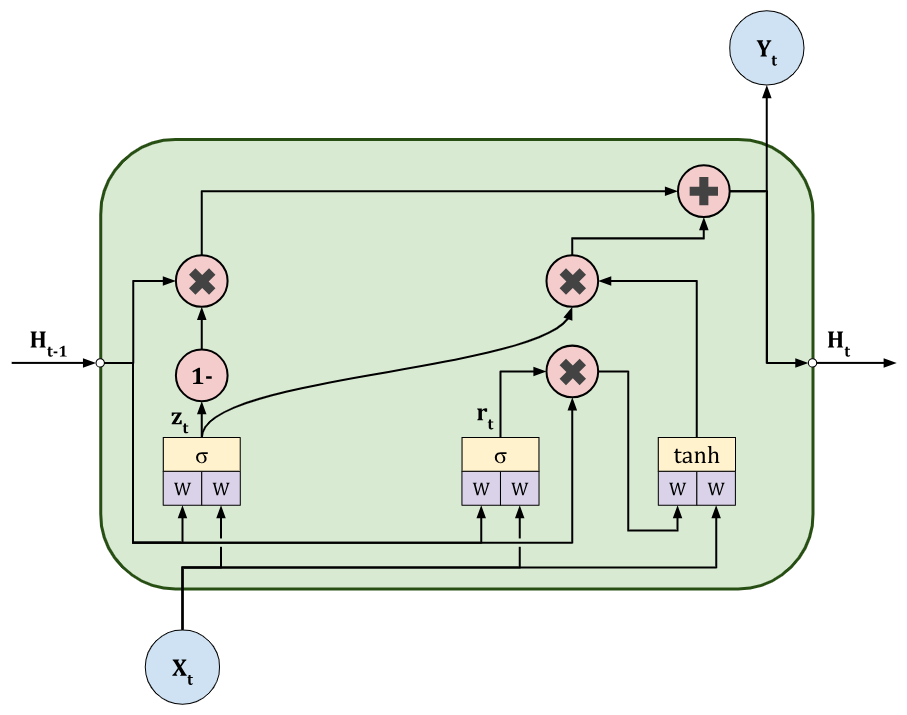
Формулы:
Вентиль сброса (Reset Gate, ): определяет, какую часть информации из прошлого () следует игнорировать при вычислении нового состояния
Вентиль обновления (Update Gate, ): определяет, какую долю информации из прошлого состояния следует сохранить, а какую — заменить новым состоянием
Кандидатное скрытое состояние (): содержит информацию из текущего входа и отфильтрованную информацию из прошлого
Итоговое скрытое состояние ():
¶ Сравнение LSTM и GRU
LSTM имеет более сложную структуру с тремя вентилями и отдельным состоянием ячейки, что дает больше гибкости и контроля над потоком информации; GRU проще, с двумя вентилями и без состояния ячейки.
GRU имеет меньше обучаемых параметров; это приводит к более быстрому обучению и может снизить риск переобучения на небольших наборах данных.
Во многих задачах производительность GRU и LSTM сопоставима.
Рекомендуется начинать с GRU из-за ее эффективности и переходить к LSTM только если есть основания полагать, что ее дополнительная сложность принесёт значимое улучшение качества для конкретной задачи
¶ Задача классификации текстовых данных
Задача классификации текста заключается в присвоении тексту одной из предопределенных меток ("позитивный", "негативный", "нейтральный" для анализа тональности; "спорт", "политика", "культура" для тематической классификации).
С помощью RNN задача решается путём обработки последовательности слов (или токенов) и получения единого векторного представления текста, который далее используется для классификации.
Элементы архитектуры модели:
Слой встраивания (Embedding Layer): преобразует числовые индексы токенов в плотные векторы фиксированной размерности (эмбеддинги); они могут быть обучены с нуля вместе с остальной моделью или инициализированы предварительно обученными векторами (Word2Vec, GloVe, FastText, Navec).
Рекуррентный слой (LSTM/GRU Layer): обрабатывает последовательность эмбеддингов, формирует итоговое состояние сети после обработки всей последовательности; используется последний скрытый вектор .
Полносвязный слой (Dense/Fully Connected Layer): принимает на вход последний скрытый вектор и преобразует его в вектор, размерность которого равна количеству классов.
Выходной слой (Output Layer): применяет функцию активации (Softmax, Sigmoid) к выходу полносвязного слоя для получения итоговых вероятностей.
¶ torch.nn.RNN
Реализует сеть Элмана.
Основные параметры:
input_size: размерность вектора для одного элемента последовательности (размер эмбеддинга)hidden_size: Размерность скрытого состоянияnum_layers: Количество рекуррентных слоев для создания стековой RNNbatch_first=True: указывает, что тензоры будут иметь формат(batch, seq_len, features), а не(seq_len, batch, features)по умолчанию
Обратите внимание на этот параметр при выполнении ЛР и дополнительных заданий
bidirectional=True: позволяет сделать сеть двунаправленной
Входы:
input: тензор с даннымиh_0: начальное скрытое состояние
Выходы:
output: скрытые состояния со всех временных шагов последнего слояh_n: финальное скрытое состояние для каждого слоя
¶ torch.nn.LSTM
Реализует LSTM. Основные параметры аналогичны torch.nn.RNN.
Входы:
input, кортеж (h_0, c_0) (начальное скрытое состояние и начальное состояние ячейки)
Выходы:
output, кортеж (h_n, c_n) (итоговые состояния)
¶ torch.nn.GRU
Реализует GRU. Основные параметры: Аналогичны torch.nn.RNN.
Входы:
input, h_0 (начальное скрытое состояние)
Выходы:
output, h_n (финальное скрытое состояние)
При работе с этими модулями, особенно с
bidirectional=Trueиnum_layers > 1, необходимо внимательно отслеживать размерности тензоров; для двунаправленной модели размерность признаков вoutputиh_nудваивается, так как происходит конкатенация выходов прямого и обратного проходов
¶ Выводы
RNN, LSTM и GRU являются мощными фундаментальными моделями обработки последовательностей (в том числе текстовых данных)
Недостаток рекуррентных архитектур — их последовательная природа. Для обработки -го элемента необходимо дождаться завершения обработки -го, что препятствует эффективному распараллеливанию вычислений на современных GPU. Это ограничение стало предпоссылкой к развитию архитектур, полностью основанных на механизме внимания (Attention).