¶ Статистический машинный перевод
¶ Теория
Задача машинного перевода (Machine Translation — MT) — это задача перевода текста с одного языка (исходный язык) к тексту на другом языке (целевом языке). До середины 2010-х годов доминирующей технологией в этой области был статистический машинный перевод (Statistic SMT).
SMT, в частности его фразовая версия (Phrase-Based SMT, PB-SMT), представляет собой подход, в котором перевод рассматривается как задача поиска наиболее вероятного предложения на целевом языке с учетом исходного предложения. Вероятность вычисляется на основе статистических данных, собранных из огромных объемов параллельных текстов.
Основная идея PB-SMT заключается в том, что переводятся не отдельные слова, а целые фразы (последовательности слов). Это позволяет лучше справляться с идиомами, локальными изменениями порядка слов и словосочетаниями, которые не переводятся дословно. Процесс перевода — это сложный поиск наилучшей "мозаики" из переведенных фраз.
Система PB-SMT состоит из нескольких независимо обученных моделей, которые работают вместе в процессе, называемом декодированием.
Модель перевода (Phrase Table)
Двуязычный словарь фраз. Для каждой фразы из исходного языка он содержит список ее возможных переводов на целевой язык, каждому из которых присвоена вероятность. Например, для английской фразы "a beautiful girl" в таблице могут быть такие русские варианты, как "красивая девушка" (высокая вероятность) и "прекрасная девочка" (более низкая вероятность). Эти вероятности рассчитываются на основе того, как часто данные пары фраз встречались вместе в параллельном корпусе текстов.
Модель языка (Language Model)
Оценивает, насколько грамматически правильным является сгенерированное предложение на целевом языке. Она ничего не знает об исходном тексте. Модель языка обучается только на больших объемах текстов на целевом языке (например, на миллионах русских статей). Обычно работает на основе N-грамм, предсказывая вероятность появления следующего слова, зная предыдущие N-1 слов. Например, она присвоит высокую вероятность фразе "сидит на стуле" и очень низкую — "сидит стуле на".
Модель переупорядочивания (Reordering Model).
Языки имеют разный порядок слов (прилагательное перед существительным в английском и русском, но после в французском). Она учится на том, как фразы в параллельных текстах меняют свои позиции при переводе. При переводе с немецкого, где глагол часто стоит в конце предложения, модель научится перемещать его на второе место в русском или английском.
¶ Пример
Нужно перевести с английского на русский предложение: "My name is John".
Сегментация. Система разбивает исходное предложение на возможные фразы. Это может быть несколько вариантов: ["My name", "is", "John"] или ["My", "name is", "John"].
Поиск переводов (Модель перевода). Для каждой фразы из каждого варианта сегментации система ищет соответствия в таблице фраз:
"My name" → "Меня зовут" (вероятность 0.8), "Мое имя" (вероятность 0.2)
"is" → "есть" (вероятность 0.5), "" (пустой перевод, вероятность 0.3)
"John" → "Джон" (вероятность 0.9)
Генерация гипотез. Декодер начинает комбинировать эти переводы, создавая множество потенциальных предложений (гипотез). Он также учитывает разные варианты порядка фраз (хотя в этом простом примере порядок сохраняется).
Гипотеза 1: "Меня зовут" + "" + "Джон" → "Меня зовут Джон"
Гипотеза 2: "Мое имя" + "есть" + "Джон" → "Мое имя есть Джон"
Гипотеза 3: "Мое имя" + "" + "Джон" → "Мое имя Джон"
Каждая гипотеза оценивается всеми моделями
Модель перевода суммирует вероятности выбранных переводов фраз. Гипотеза 1 использует перевод "Меня зовут" с высокой вероятностью (0.8).
Модель языка оценивает получившиеся русские предложения. Фраза "Меня зовут Джон" очень распространена в русском языке и получит высокую оценку. "Мое имя есть Джон" — грамматически верная, но звучит менее естественно и получит оценку ниже. "Мое имя Джон" также является естественной и получит хорошую оценку.
Модель переупорядочивания в данном случае не накладывает штрафов, так как порядок фраз не менялся.
Выбор лучшего перевода. Декодер вычисляет итоговый балл для каждой гипотезы, комбинируя оценки всех моделей. Гипотеза, набравшая максимальный балл, выбирается в качестве окончательного перевода. Cкорее всего победит "Меня зовут Джон" благодаря высокой вероятности в модели перевода и высокой гладкости в модели языка.
¶ Нейронный машинный перевод
В 2014-2015 годах произошла революция и появилился нейронный машинный перевод (Neural MT, NMT). Вместо конвейера из множества компонентов используется одна большая нейросеть, которая обучается сквозным образом (end-to-end).
Фундаментальная задача NMT — напрямую смоделировать условную вероятность получения правильного перевода при наличии исходного предложения
Системы SMT строились на статистических принципах, которые были до некоторой степени интерпретируемы. Исследователь мог изучить таблицы фраз или вероятности языковой модели, чтобы понять, почему система приняла то или иное решение. NMT сворачивает все эти функции в единую нейронную сеть ("черный ящик").
Центральная задача — Sequence-to-Sequence (Seq2Seq), отображение входной последовательности переменной длины (предложение на одном языке) в выходную последовательность переменной длины (предложение на другом языке). Первой архитектурой для решения этой задачи стала Encoder-Decoder.
¶ Обзор архитектуры
Концепция практически одновременно предложена в работах:
- Sequence to Sequence Learning with Neural Networks (Sutskever et al., 2014)
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation (Cho et al., 2014)
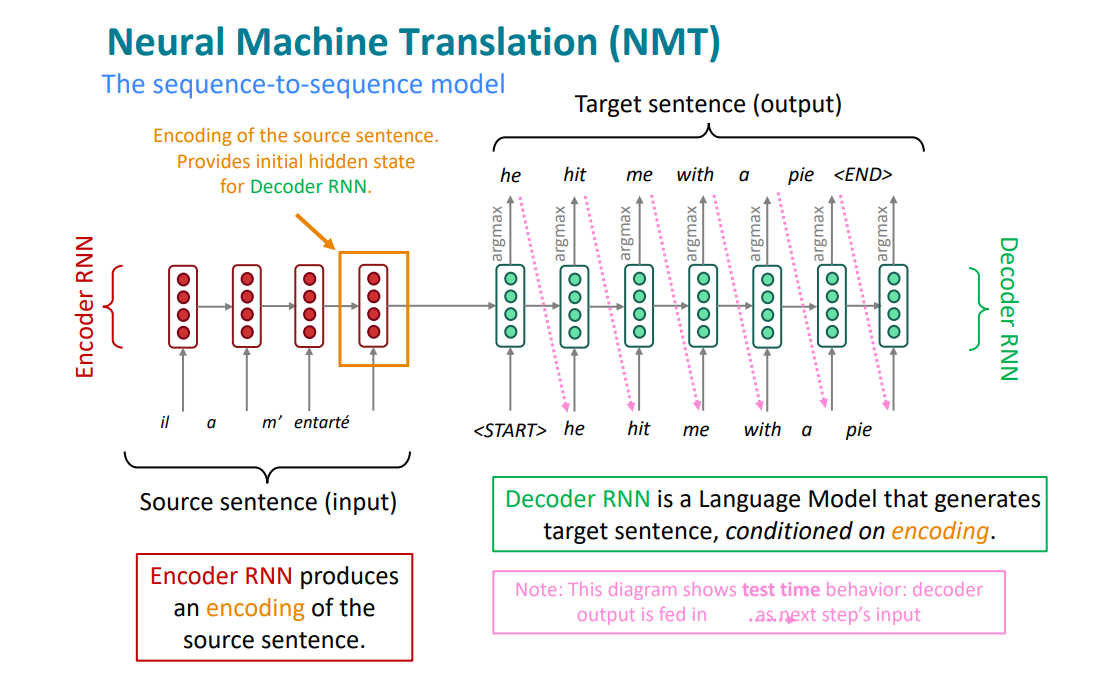
Две RNN. Одна (Кодировщик, Encoder) читает исходное предложение и сжимает его смысл в единый вектор. Другая (Декодировщик, Decoder) использует этот вектор, чтобы написать новое предложение.
Конечное скрытое состояние кодировщика является начальным состоянием декодировщика
Для решения задачи машинного перевода целесообразно применять рекуррентные нейронные сети вида Many to Many
Для каждого текущего токена на исходном языке кодировщик предсказывает (задача классификации) следующий токен на целевом языке
Модели Seq2Seq применяются при решении самых разных задач обработки естественного языка:
- суммаризация (длинный текст → краткий текст)
- генерация кода (естественный язык → код Python)
- генерация текста (начало истории → продолжение истории)
Кодировщик обрабатывает входную последовательность токенов один за другим. На каждом временном шаге скрытое состояние обновляется на основе предыдущего скрытого состояния и текущего входного токена . осле обработки всей входной последовательности до последнего токена финальное скрытое состояние кодировщика принимается за представление всего предложения. Этот вектор фиксированного размера называется вектором контекста (context vector) .
Декодировщик функционирует как языковая модель. Его задача — сгенерировать целевую последовательность токен за токеном.
Начальное скрытое состояние декодировщика инициализируется вектором контекста , полученным от кодировщика ()
На первом шаге () декодировщик принимает специальный токен начала предложения <sos> (Start of Sequence) и свое начальное скрытое состояние для предсказания первого токена целевого предложения . На каждом последующем шаге он принимает в качестве входа сгенерированный на предыдущем шаге токен и предыдущее скрытое состояние , чтобы сгенерировать следующий токен . Этот процесс продолжается до тех пор, пока не будет сгенерирован токен конца предложения <eos> (End of Sequence).
¶ Обучение модели
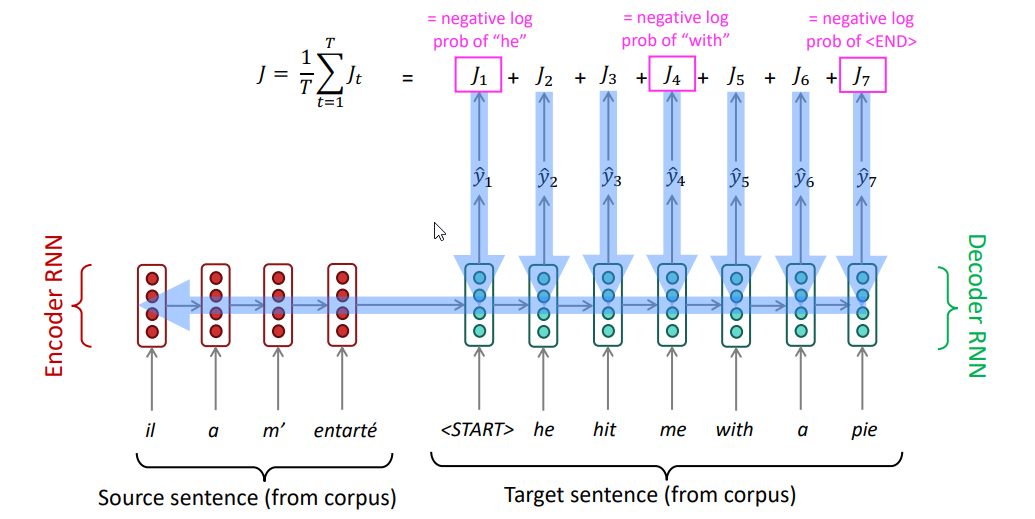
Общая функция потерь для одной пары исходного и целевого предложений вычисляется как сумма отрицательных логарифмов вероятностей (через Softmax) для каждого правильного слова в целевой последовательности:
Здесь:
- — итоговая ошибка (потери) для одной последовательности, которую стремимся минимизировать
- — длина целевой последовательности (количество токенов в правильном переводе)
- — текущий шаг генерации
- — правильный токен на шаге
- — последовательность правильных токенов перед шагом , то есть .
- — вектор контекста, полученный от кодировщика
- — это вероятность, которую модель (декодировщик) присвоила правильному токену на шаге , получив на вход предыдущие токены и контекст
Генерация следующего токена на целевом языке опирается на результат предыдущей генерации. Поэтому, если модель предскажет неверный токен в середине предложения, все последующие токены будут предсказываться также неверно.
Для устранения этой проблемы применяется подход Teacher Enforcing.
Обучение реализуется следующим образом:
- берем текст на исходном языке и прогоняем его через кодировщик
- подаем на первом шаге в декодировщик специальный токен
<sos> - предсказываем с помощью декодировщика первый токен предложения на целевом языке
- используя гиперпараметр
Teacher Enforcing(от 0 до 1) случайным образом определяем, будем ли мы далее на вход кодировщику подавать предсказанный ранее токен или будем подавать истинный токен - продолжаем генерацию
Таким образом, модель будет учиться предсказывать следующие токены не накапливая ошибку.
¶ Оценка качества
Самой распространенной метрикой является BLEU (Bilingual Evaluation Understudy).
Чем ближе машинный перевод к профессиональному человеческому переводу, тем он лучше
Сначала вычисляется модифицированная точность n-грамм (униграмм, биграмм, триграмм, 4-грамм) в машинном переводе по сравнению с некоторым эталонным переводом. "Модификация" вводит простое правило: нельзя засчитывать одно и то же слово больше раз, чем оно встречается в эталонном переводе.
Эталонный перевод: "мальчик пошел в магазин за хлебом"
Машинный перевод: "хлебом хлебом хлебом хлебом хлебом"
Далее нужно учитывать переводы, которые слишком коротки по сравнению с эталонными, так как короткие предложения могут иметь искусственно высокую точность.
где — длина машинного перевода, а — длина эталонного перевода.
Итоговая оценка — геометрическое среднее точностей для разных , умноженное на штраф за краткость.
где — веса (обычно равномерные, ).
На практике достичь оценки 1 почти невозможно, и даже перевод, выполненный другим профессиональным переводчиком, не всегда получит максимальный балл, так как могут использоваться разные синонимы и конструкции. Поэтому для интерпретации результатов используют следующую шкалу:
<0.1: бесполезный перевод0.1–0.2: суть уловить можно, но с трудом; много грамматических и смысловых ошибок0.3–0.39: понятный и в целом приемлемый перевод0.4–0.5: качественный перевод>0.5: очень качественный перевод, близкий к человеческому
¶ Механизм внимания
Вся суть исходного предложения, независимо от его длины или сложности, должна быть сжата в единый вектор контекста c фиксированного размера
Это создает "бутылочное горлышко" информации (information bottleneck). По мере увеличения длины предложения модели становится все труднее сохранить всю необходимую информацию. Информация из начала предложения может быть забыта к моменту, когда RNN обработает его конец. Это приводит к резкому падению качества перевода для длинных предложений.
Проблема информационного "бутылочного горлышка" была главным препятствием на пути к созданию высококачественного NMT. Решением стал механизм внимания (attention mechanism) — идея, которая не только кардинально улучшила машинный перевод, но и полностью перевернула NLP.
Нормальный переводчик не читает все исходное предложение, не запоминает его целиком, а затем пишет перевод. Он фокусируется на разных частях исходного текста по мере того, как переводит разные фрагменты целевого предложения. Механизм внимания стремится дать нейронной сети способность динамически "обращать внимание" на наиболее релевантные части исходного предложения на каждом шаге генерации перевода.
Вместо схемы, где вся информация упаковывается в один вектор, механизм внимания превращает кодировщик в своего рода "базу данных с возможностью запроса"
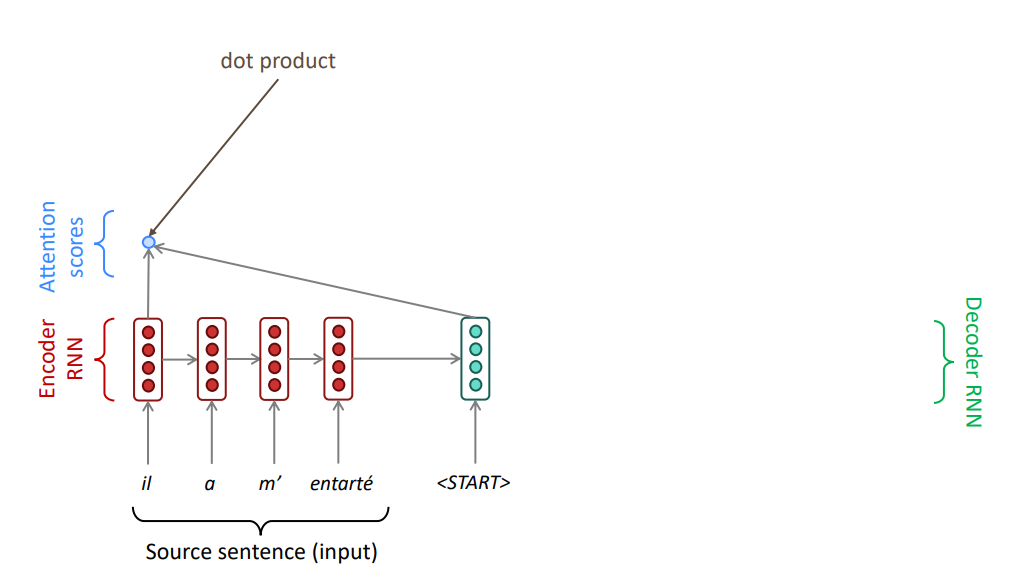
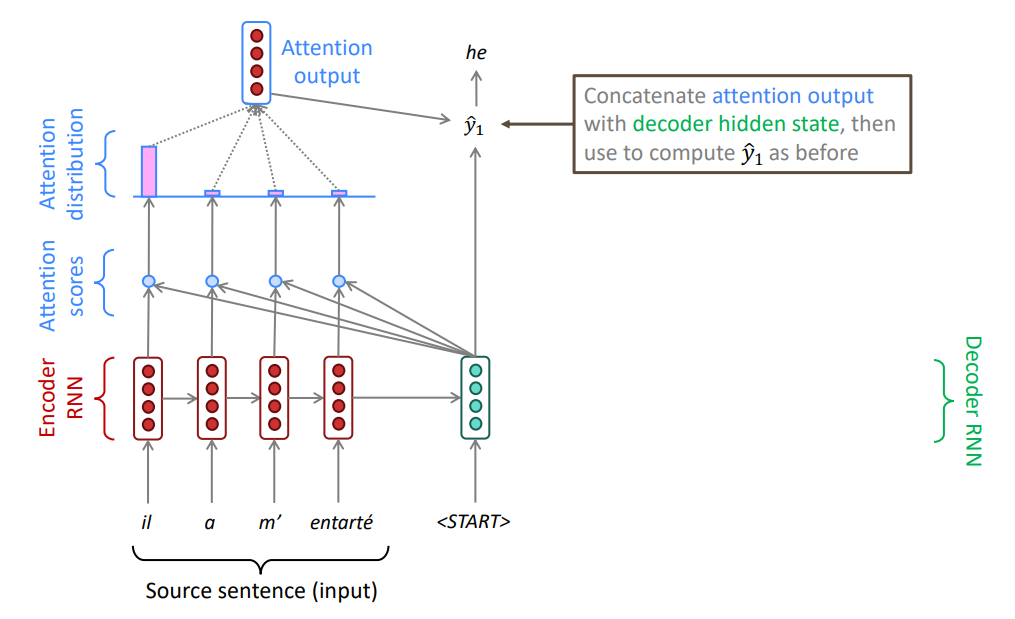
Кодировщик формирует не один вектор, а последовательность векторов — по одному на каждый токен исходного текста. На каждом шаге декодировщик может "отправить запрос" в эту "базу данных" векторов и извлечь наиболее релевантную информацию для генерации следующего токена.
Основная идея механизма внимания: на каждом шаге декодирования использовать связи со всеми скрытыми состояниями кодировщика для того, чтобы фокусироваться (обращать внимание) не только на всю входную последовательность, но и на отдельные подпоследовательности.
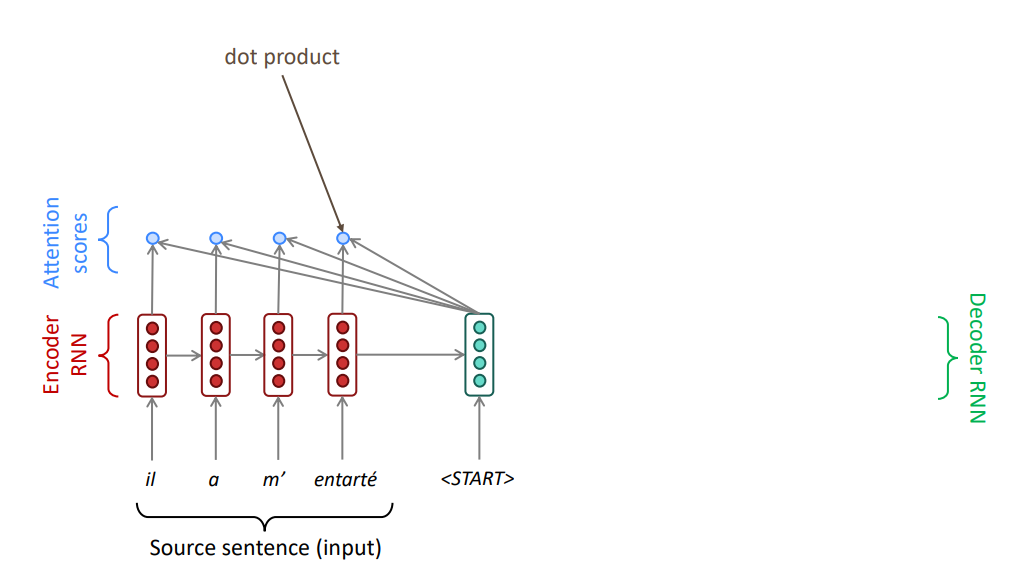
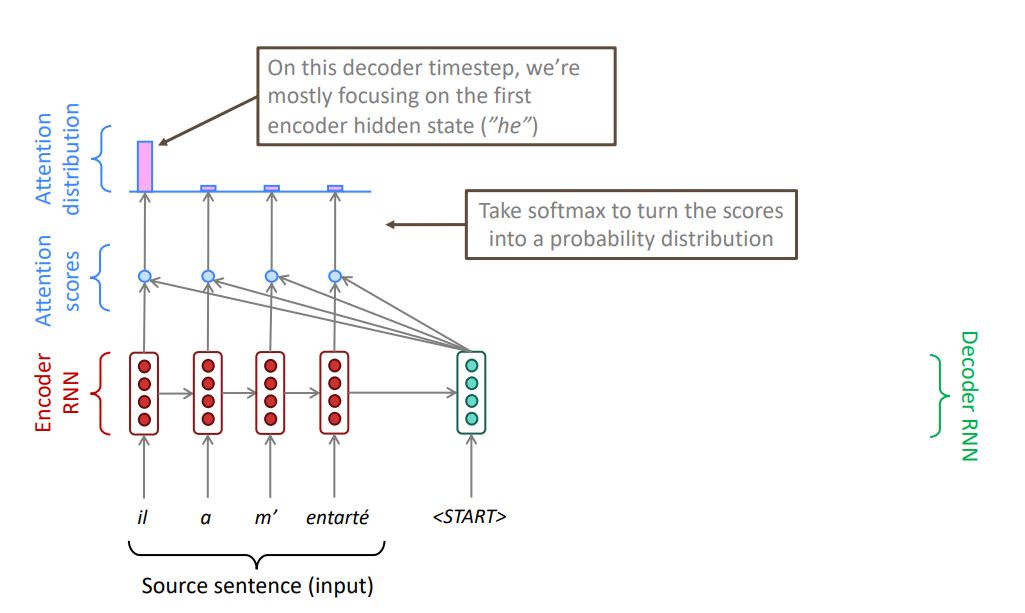
Получаем n чисел, где n — количество токенов входной последовательности. Применяем softmax.
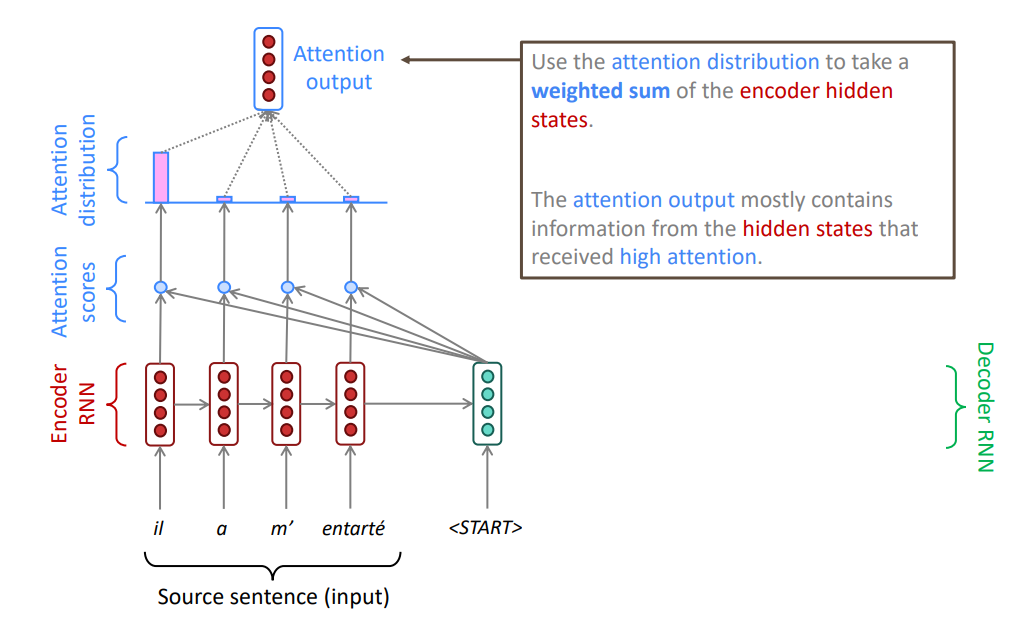
Механизм внимания построен на концепции запросов (queries), ключей (keys) и значений (values)
- Query (Запрос): в RNN это скрытое состояние декодера, которое "спрашивает", на что обратить внимание в исходном тексте
- Key (Ключ): метка для каждой записи в базе данных; единственная цель — быть сопоставленным с запросом, чтобы определить степень соответствия; в RNN это скрытые состояния кодировщика, которые служат "метками" для каждого слова исходного предложения
- Value (Значение): информация, хранящаяся в записи; в RNN это тоже скрытые состояния кодировщика, но они рассматриваются как носители содержательной информации о словах
Одна из ключевых идей внимания заключается в разделении двух процессов:
- Определение релевантности: насколько важен каждый элемент входной последовательности для текущей задачи?
- Агрегация информации: какую информацию из этих релевантных элементов нужно извлечь?
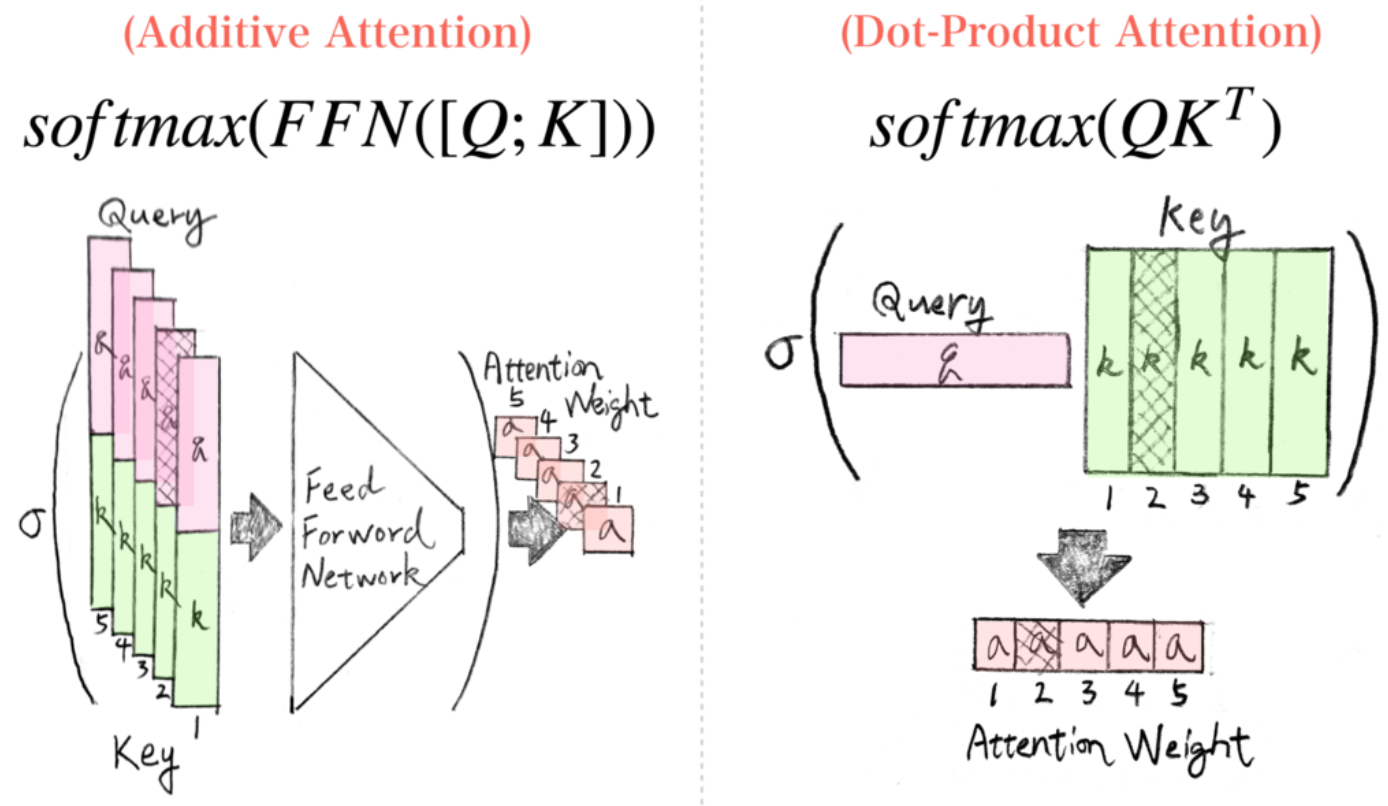
Существует два подхода к реализации механизма внимания (выше мы рассмотрели мультипликативный):
¶ Заключение
Даже с учетом модификации архитектуры Encoder-Decoder с применением механизма внимания, проблема RNN не решается - вычисления в виду рекурретности все еще не могут быть распараллелены.
При этом использование механизма внимания существенно повышает качество рекурретных моделей.