¶ Определение нейронного машинного переводы
Задача машинного перевода (Machine Translation — MT) — это задача перевода предложения (текста) x с одного языка (исходный язык) к предложению (тексту) y на другом языке (целевом языке).
Формально: задача поиска максимально правдоподобного предложения y на целевом языке для предложения x на исходном.
Нейронный машинный перевод (Neural Machine Translation — NMT) — решение задачи машинного перевода с использованием нейронных сетей.
¶ Архитектура сети для NMT. Seq2Seq
Для решения задачи машинного перевода целесообразно применять рекуррентные нейронные сети вида Many to Many:

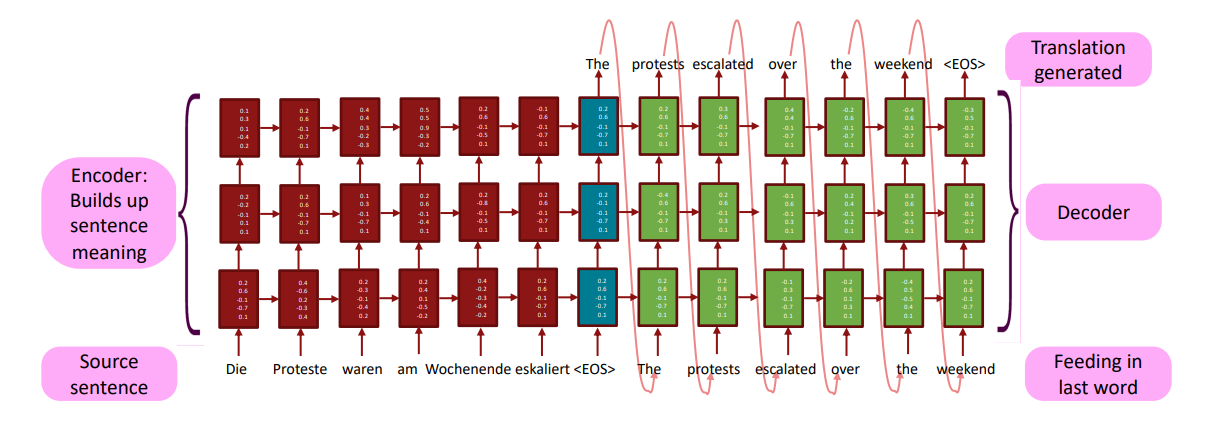
Архитектура приведенная выше называется Seq2Seq (Sequence-To-Sequence). Модель состоит из двух частей — кодировщик (Encoder) и декодеровщик (Decoder).
Кодировщик и декодировщик представляют из себя отдельные рекуррентные рекуррентные нейронные сети. Конечное скрытое состояние кодировщика является начальным состоянием декодировщика.
Таким образом, кодировщик выполняет извлечение информации о контексте исходного предложения (текста). Формируется конечное скрытое состояние. Декодировщик, используя накопленную информацию о контексте исходного текста, последовательно формирует предложение на целевом языке.
Для каждого текущего токена на исходном языке кодировщик предсказывает (задача классификации) следующий токен на целевом языке.
Модели Seq2Seq применяются при решении самых разных задач обработки естественного языка:
- суммаризация (длинный текст → краткий текст)
- генерация кода (естественный язык → код Python)
- генерация текста (начало истории → продолжение истории)
При решении задачи машинного перевода можем использовать глубокие рекуррентные нейронные сети:
¶ Особенности обучения модели NMT
Критерием оптимизации является категориальная перекрестная энтропия. Negative log probability — это результат применения логарифма к результату softmax, взятый со знаком минус.

Генерация следующего токена на целевом языке опирается на результат предыдущей генерации.
Поэтому, если модель предскажет неверный токен в середине предложения, все последующие токены будут предсказываться также неверно.
Для устранения этой проблемы применяется подход Teacher Enforcing.
Обучение реализуется следующим образом:
- берем текст на исходном языке и прогоняем его через кодировщик
- подаем на первом шаге в декодировщик специальный токен (Start of sequence)
- предсказываем с помощью декодировщика первый токен предложения на целевом языке
- используя гиперпараметр Teacher Enforcing (от 0 до 1) случайным образом определяем, будем ли мы далее на вход кодировщику подавать предсказанный ранее токен или будем подавать истинный токен
- продолжаем генерацию
Таким образом, модель будет учиться предсказывать следующие токены не накапливая ошибку.
¶ Оценка качества машинного перевода. BLEU
Одной из часто применяемых метрик качества системы машинного перевода является BiLingual Evaluation Understudy (BLEU).
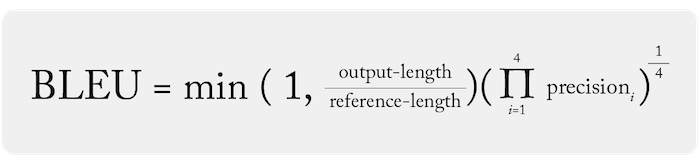
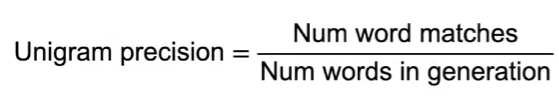
Метрика BLEU не является ориентиром — может существовать несколько правильных переводов
¶ Attention. Механизм внимания
В основе современного NLP лежит использование механизма внимания. Мы начнем знакомиться с ним уже сейчас, в рамках задачи машинного перевода.
Основной вопрос, возникающий при использовании рекуррентных нейронных сетей для кодирования контекста: можем ли мы сохранить всю информацию о контексте в одном векторе (в скрытом состоянии)?
В случае коротких текстов — нет проблем. Но статью из более чем 50 слов уже не получится адекватно сжать до вектора размерности 256 (допустим). При этом конечное скрытое состояние является основой нашего перевода. Таким образом имеем “бутылочное горлышко”.
Основная идея механизма внимания: на каждом шаге декодирования использовать связи со всеми скрытыми состояниями кодировщика для того, чтобы фокусироваться (обращать внимание) не только на всю входную последовательность, но и на отдельные подпоследовательности.

Вычисляем скалярные произведения между текущим состоянием декодировщика и каждым скрытым состоянием кодировщика.

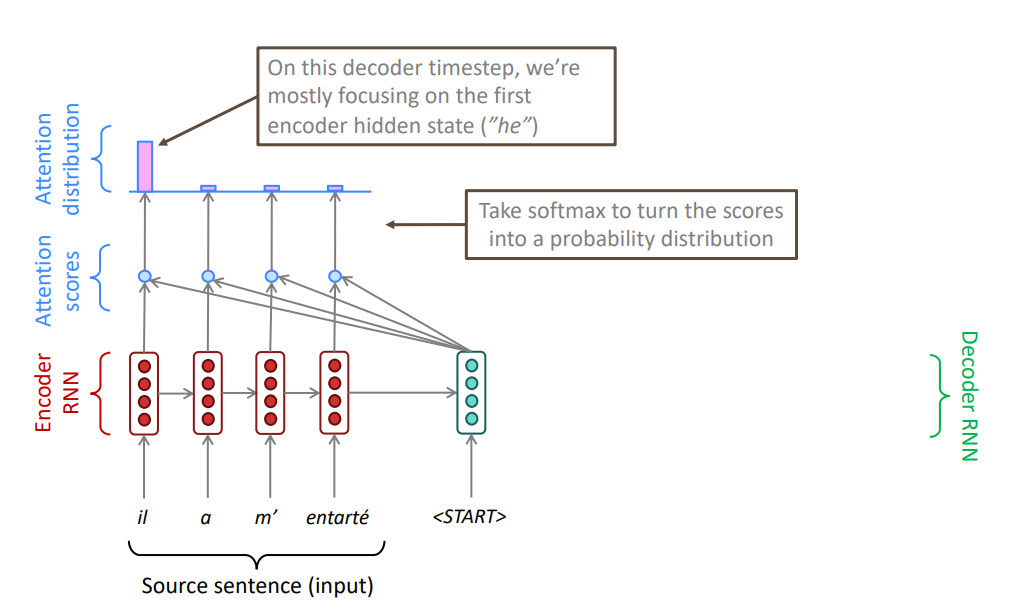
Получаем n чисел, где n — количество токенов входной последовательности. Применяем softmax.
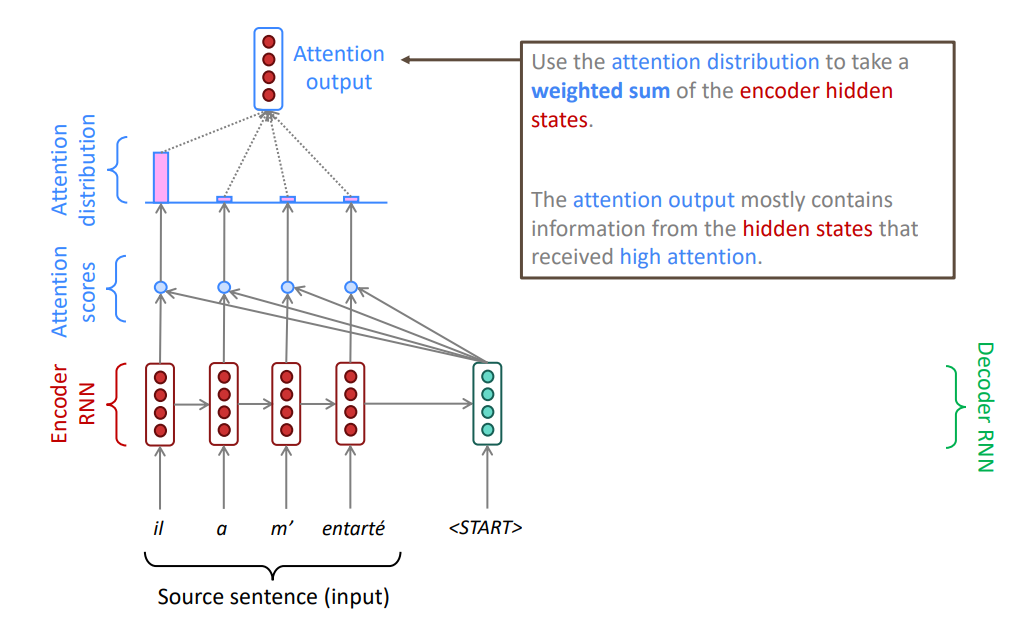
Используем полученный в результате применения softmax вектор в качестве коэффициентов и вычисляем взвешенную сумму состояний кодировщика.
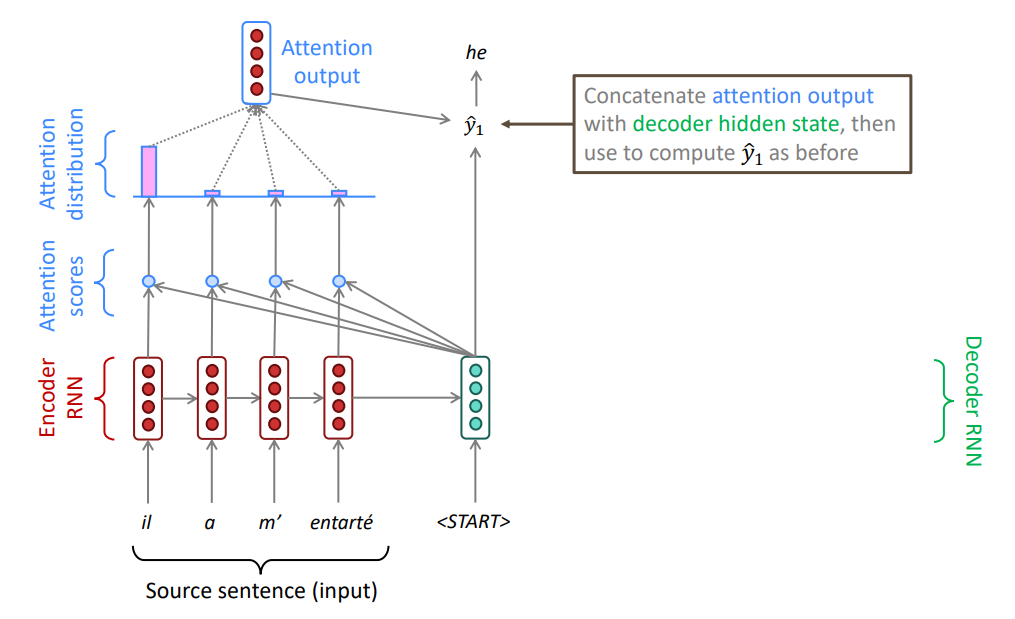
Вектор, соответствующий взвешенной сумме, конкатенируем с текущим состоянием декодировщика и используем его для получения предсказания.
Механизм внимания позволяет извлекать из входной последовательности наиболее важную для текущего состояния декодировщика информацию.
¶ Общее определение внимания в глубоком обучении
Дан некоторый набор векторов-значений (values) и некоторый вектор-запрос (query).
Механизм внимания — это метод получения взвешенной суммы векторов-значений в зависимости от вектора-запроса (аналогией может быть поисковая система, например Google, которая по запросу ранжирует сайты).
В механизме внимания необязательно использовать скалярное произведение векторов — можно использовать вспомогательные обучаемые матрицы (когда размерности векторов-запросов и векторов-значений различаются). Также можно добавлять функцию активации.
Однако в современном NLP в механизме внимания обычно используется скалярное произведение (поскольку его быстро считать).
Механизм внимания лежит в основе самых современных моделей глубокого обучения — трансформеров, с которыми мы скоро познакомимся.