¶ Введение
Мы уже знаем, что, используя максимально общие рассуждения, все задачи NLP можно разбить на два класса:
- понимание языка (классификация, регрессия, кластеризация, тегирование и др.);
- моделирование языка (генерация, перевод и др.)
В заключении разговора о трансформерах мы обсудим интересные подходы к решению некоторых задач понимания естественного языка.
¶ Часть 1. Семантическая схожесть текстов (Semantic Textual Similarity)
Важнейшей фундаментальной задачей первого класса, являющейся базовой для решения других задач, является задача оценки схожести пары текстов (предложений).
Замечание: здесь и далее под терминами “текст” и “предложение” будем понимать строку на естественном языке; размером будем пренебрегать; термины будем считать синонимами.
Предположение: если для любых двух текстов мы можем оценить степень их семантической схожести (вычислить “меру похожести” текстов), значит мы научились понимать язык.
Следствие: мы получили способ представления как отдельных слов в виде векторов, так и целых предложений.
Мы уже знаем, что тексты удобно сравнивать с использованием BERT-based моделей.
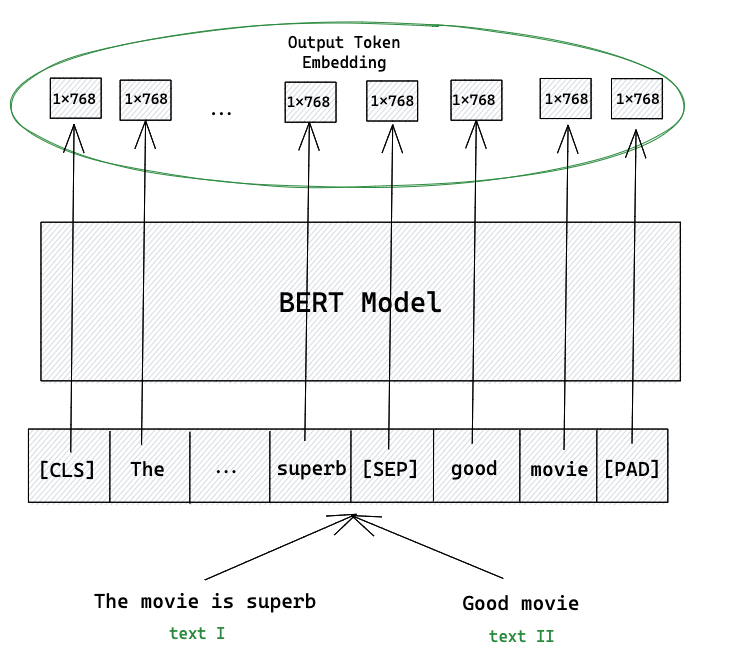
Мы берем пару предложений, подаем ее на вход трансформеру, на выходе получаем набор эмбеддингов, берем эмбеддинг специального токена и используем его для предсказания меры схожести текстов (задача регрессии).
Казалось бы, все понятно и работает, но есть недостатки.
Ранее было сказано, что задача оценки схожести пары текстов является базовой и редко когда решается сама по себе. Возьмем прикладную задачу - семантический поиск.
Пусть дан текст q и набор текстов p1,…,pm. Необходимо найти k наиболее похожих на q текстов из набора p1,…,pm. Задача семантического поиска - это классическая задача для поисковых и вопросно-ответных систем. Значение m может быть очень большим, но для решения задачи нам необходимо выполнить инференс BERT-based модели m раз. При этом каждый раз на вход мы подаем пару текстов.
Замечание: какой бы большой не была бы длина паддинга (количество токенов, которое на вход принимает трансформер) современные трансформеры используют так называемую attention mask для того, чтобы токен padding не учитывался в механизме внимания. Поэтому вы реально почувствуете разницу между 10 и 500 “полезными” токенами на входе.
Поэтому для решения этой задачи использование BERT-based модели в том виде, который мы рассмотрели, - не лучший вариант!
А есть еще задачи, когда нам просто дан набор из m текстов, и нам необходимо попарно оценить их схожести (например, чтобы потом объединять семантически близкие тексты). Тогда получается, что нам нужно (m*(m-1))/2 раз выполнить инференс модели. И каждый раз на входе 2 текста! Это не порядок.
В 2019 году была предложена идея, которая предполагает решение этих задач с использованием традиционной меры схожести текстов в NLP - косинуса между векторными представлениями текстов. Получается, что нужно было разработать метод получения эмбеддингов текстовых документов.
Исследователи предложили использовать идею сиамских нейронных сетей (Siamese Neural Networks) для решения задачи семантического поиска. Можно подавать на вход двух одинаковых (веса тоже одинаковы) BERT-based моделей первый и второй тексты. Получать для каждого текста таким образом набор эмбеддингов, после чего за счет пуллинга превращать этот набор в эмбеддинг для всего текста. А далее можно к получившимся эмбеддингам применить любую меру близости (например, косинусную близость) и использовать ее в качестве функции потерь (если нужно).
Замечание: при обучении таких моделей достаточно сделать шаг градиентного спуска для одной из них. А потом копировать новые веса.
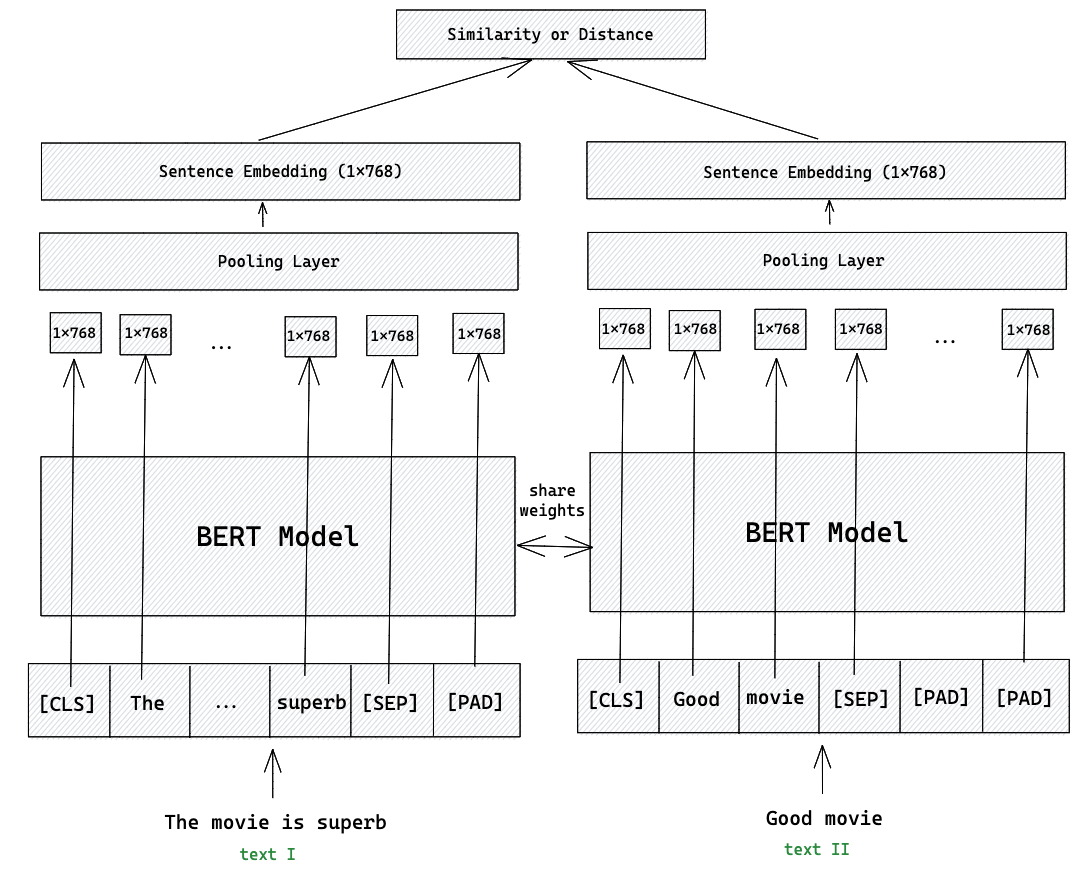
Авторы статьи предложили вместо использования эмбеддинга токена в качестве векторного представления текста использовать Mean Pooling - усреднять эмбеддинги “полезных” токенов.
Таким образом, в результате обучения подобных моделей, мы получаем способ векторизации текстов. Больше не нужны никакие Navec и предварительно обученные векторные представления, потому что теперь мы можем для любого текста сразу же получить векторное представление с применением механизма внимания.
Косинус между векторами показывает семантическую близость текстов. При этом для повышения производительности целесообразно сначала нормировать векторные представления, а затем считать скалярное произведение (вспомните формулу скалярного произведения векторов и случай, когда длины векторов равны единице).
Описанный подход получил название Sentence BERT (или SBERT). Кстати в настоящее время “зеленый банк” применяет идею SBERT в своих голосовых ассистентах и использует собственную модель.
Исследователи пошли дальше и разработали фреймворк Sentence Transformers, который позволяет всем желающим задействовать возможности трансформеров для решения задач понимания естественного языка. Основная идея: эффективное вычисление векторных представлений текстов, их нормировка и вычисление косинусной близости.
¶ Часть 2. Задача распознавания именованных сущностей
Давайте сделаем небольшое отступление, чтобы плавно перейти потом к следующей части. Ранее мы уже упоминали задачу извлечения именованных сущностей (Named Entity Recognition). Давайте сформулируем ее и посмотрим на простой способ решения.
Источник: доклад на IT-субботнике.
Именованной сущностью (named entity) в тексте называют слово или словосочетание, обозначающее предмет или явление определенной категории.
В качестве классических примеров можно привести имена людей, организаций, названия географических объектов и др.
При решении современных задач обработки естественного языка к именованным сущностям относят все важные для понимания деталей текста слова и словосочетания. На практике крайне важно извлечение из текста таких именованных сущностей, как числа и даты.

Существует два основных подхода к решению задачи.
Подход на основе правил (rule-based approach)
- Использование регулярных выражений (извлечение таких сущностей, как номера телефонов, адреса электронной почты, элементы библиографического списка публикации и т. д.).
- Формулирование правил (первая буква заглавная, остальные – строчные).
Подход на машинного обучения (machine learning approach)
Решение задачи классификации с использованием архитектур глубоких нейронных сетей, позволяющих обрабатывать последовательности (RNN, LSTM, BiLSTM, трансформеры и др.).
Задача распознавания именованных сущностей в текстовом документе эквивалентна задаче сопоставления каждому токену исходного текста метки, которая характеризует связь токена с одной из именованных сущностей (мультиклассовая классификация).
Требуется разметка данных. Наиболее распространенным подходом является BIO-нотация:
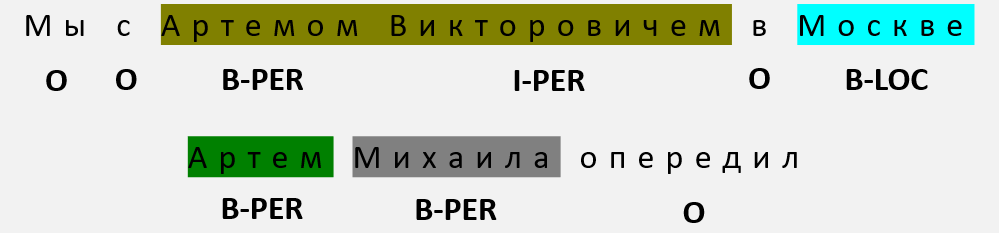
При решении задачи следует учитывать сильнейший дисбаланс классов, который является следствием BIO-нотации. Классическая перекрестная энтропия не всегда способна преодолеть такой дисбаланс, поэтому часто вводят балансирующие коэффициенты.


Часто задача NER решается с использованием BERT-based моделей, однако некоторые исследователи изобретают альтернативные решения. Да, я сейчас имею в виду авторов компанию Explosion AI, авторов фреймворка Spacy.
¶ Часть 3. Фреймворк Spacy
Spacy - это большой фреймворк, который применяется для решения самых разных задач обработки естественного языка. Особенность фреймворка - собственная единая архитектура моделей, напоминающая конвейер.
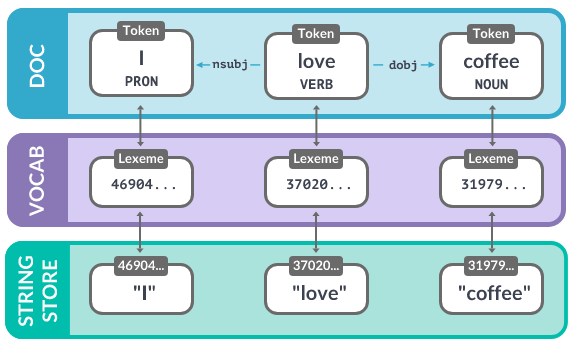
Идея Spacy: мы прогоняем текст через последовательность компонентов модели. Результатом обработки является объект Doc, который содержит в себе всю извлеченную из текста информацию (отдельные токены, их леммы, информацию о частях речи и синтаксической роли каждого токена, именованные сущности и т. д.).

Объект Doc очень похож на обычные списки (массивы). Обращаясь по индексу (к конкретному слову) мы извлекаем объект Token. Обращаясь по нескольким индексам (с помощью среза) мы получаем объект Span (несколько токенов).
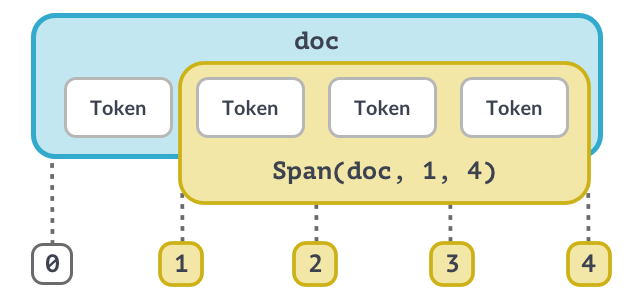
Каждый токен содержит в себе ссылку на соответствующий ему объект в словаре (в объекте Vocab). Каждый объект в словаре содержит хэш, по которому модель находит лемму для токена.