¶ Задание
¶ 1. Изучение примеров
Изучите материалы.
¶ 2. Загрузка и подготовка данных
- Сгенерировать 3 датасета с использованием функции make_classification и 2 датасета с использованием функции make_blobs. Данные необходимо сгенерировать так, чтобы на них можно было получить хорошее качество кластеризации. Количество кластеров должно быть различным и не менее трёх.
- В соответствии с индивидуальным вариантом загрузите предобработанный датасет в формате CSV для решения задачи классификации. Удалите метку класса.
Для студентов Гуненкова М. Ю. и Шаруна И. В.: достаточно сгенерировать 2 датасета для выполнения данной ЛР. Один с метками классов (через
make_classification) для применения на нем внешних метрик и один без меток (черезmake_blobs) для применения на нем внешних и внутренних метрик.
¶ 3. Решение кластеризации
С использованием библиотек:
- Реализовать следующие алгоритмы кластеризации на синтетических данных: k-means, иерархическая кластеризация, DBSCAN, EM-алгоритм, Affinity Propagation.
- Реализовать следующие алгоритмы кластеризации на данных для задачи классификации: k-means, DBSCAN, EM-алгоритм, Affinity Propagation.
- Для соответствующего алгоритма кластеризации (используемых в пунктах выше) подобрать оптимальные гиперпараметры. В случае алгоритма кластеризации k-means используйте «метод локтя» и график силуэтов.
- Провести визуализацию работы всех алгоритмов кластеризации. Если это возможно, то вывести номер кластера. Описать качество кластеров по их внешнему виду.
- Если это возможно, то вывести номер кластера, создав дополнительный столбец в датасете для задачи классификации. Найдите характеристики каждого из кластеров с помощью библиотеки Pandas
¶ 4. Оценка качества моделей
Каждый реализованный алгоритм кластеризации оцените 2 внешними и 2 внутренними метриками оценки качества.
¶ 5. Реализация алгоритма кластеризации k-means
- Самостоятельно разработать и реализовать алгоритм кластеризации kmeans с возможностью подсчета суммы квадратов расстояний между точками и соответствующими центроидами.
- Поместить разработанный алгоритм кластеризации k-means в существующий файл библиотеки алгоритмов ML и подключите его к основной программе.
- Провести кластеризацию двух сформированных датасетов (для k-means и любой другой) и датасета для классификации с использованием собственной реализации алгоритма k-means и k-means из библиотеки Scikit-learn.
- Произвести визуализацию построенных моделей и показать распределение кластеров.
- Выполнить оценку качества полученных моделей кластеризации. Сравнить полученные результаты.
Для студентов Моисеевой Н. А. использовать следующий образец:
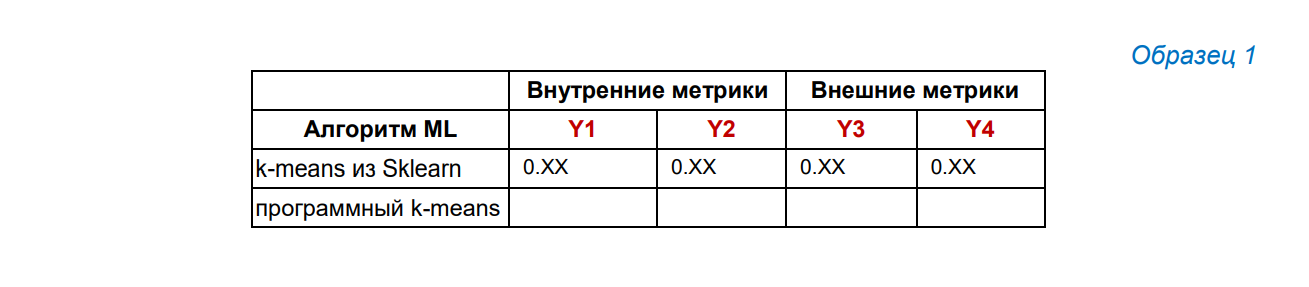
¶ 6. Создание таблицы результатов (для студентов Моисеевой Н. А.)
Создать таблицу, вывести в ней наименования используемых алгоритмов кластеризации, наименования и значения вычисленных метрик оценки качества (Y1 и т.д.,) для синтетических данных и датасета для задачи классификации (Образец 2).

¶ 7. Вывод
Напишите вывод о выполненной лабораторной работе, в котором выберите лучшую модель кластеризации для синтетических данных и данных задачи классификации. Обоснуйте свое решение.
¶ Длительность выполнения
2 пары, считая пару выдачи