¶ Основная теория
¶ Потоковая обработка данных (Data Streaming)
Существуют данные, которые необходимо обрабатывать по мере их поступления.
Например:
- клики пользователей на сайте
- координаты GPS
- звонки и SMS
- банковские транзакции
- онлайн-игры и др.
¶ Принципы DataStreaming
- непрерывный поток данных (теоретически может быть не ограничен)
- низкая задержка (данные должны обрабатываться очень быстро)
- обработка данных практически в реальном времени
¶ Инструменты DataStreaming
- Apache Kafka, RabbitMQ, IMB MQ и другие брокеры сообщений
- Apache Spark Structured Streaming (ранее Apache Spark Streaming), Amazon Kinesis Data Streams, Google Cloud Dataflow и другие инструменты преобразования и обогащения потоков данных
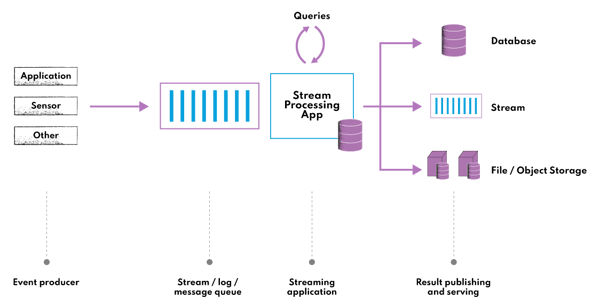
¶ Схема потоковой обработки данных
При потоковой обработке данных реализуется прослушивание брокера сообщений на предмет поступления новых данных, после чего они очищаются, обогащаются и добавляются к уже имеющимся.
Одним из ключевых механизмов при работе с потоками данных являются окна, позволяющие производить группировку поступающих данных по времени.
После выполнения агрегаций мы можем:
- сохранить новые данные в хранилище
- отправить очищенные и обогащенные данные в очередь сообщений для последующей обработки другими сервисами
- визуализировать / представить в удобном для восприятия виде
¶ Брокеры сообщений
Брокерами сообщений называют сервисы, являющиеся посредниками при взаимодействии других сервисов (источников и приемников сообщений). Сообщение — это информация, представленная в произвольном формате (JSON, CSV, Protobuf и другие).
Брокеры сообщений позволяют реализовать схему Procuder-Consumer (или Publisher-Subscriber)
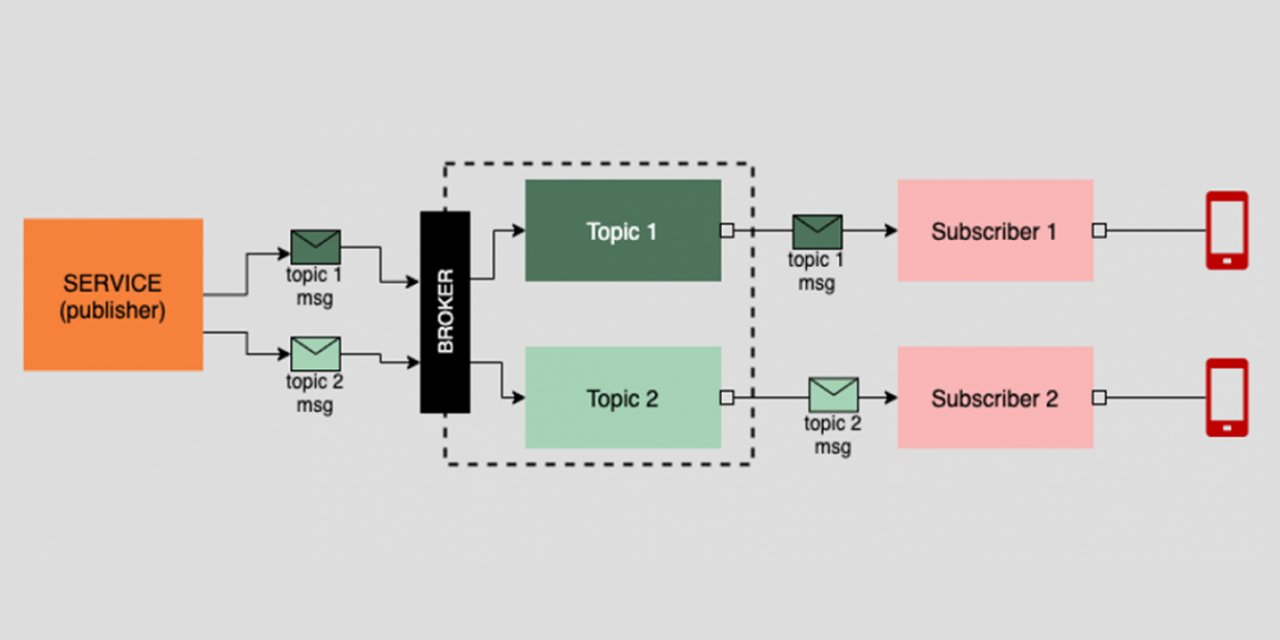
В разработке высоконагруженных приложений брокеры сообщений позволяют настроить взаимодействие микросервисов (в рамках микросервисной архитектуры). При работе с большими данными брокеры сообщений применяются для сбора и обработки данных.
¶ Интеграция данных
ETL (Extract, Transform, Load) — стандартная последовательность действий по интеграции данных, используемая для перемещения и подготовки информации из различных источников в централизованное хранилище данных (Data Warehouse,DWH) для последующего анализа и использования.
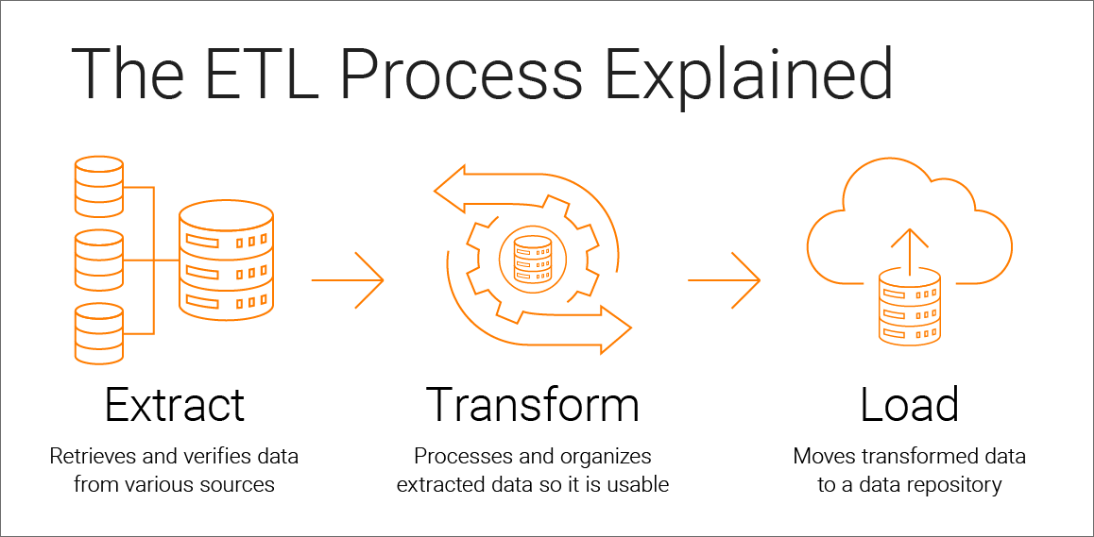
| Этап | Описание |
|---|---|
| Извлечение | Сбор данных из различных источников |
| Преобразование | Очистка, стандартизация, обогащение и подготовка данных к загрузке |
| Загрузка | Перенос подготовленных данных в целевое хранилище |
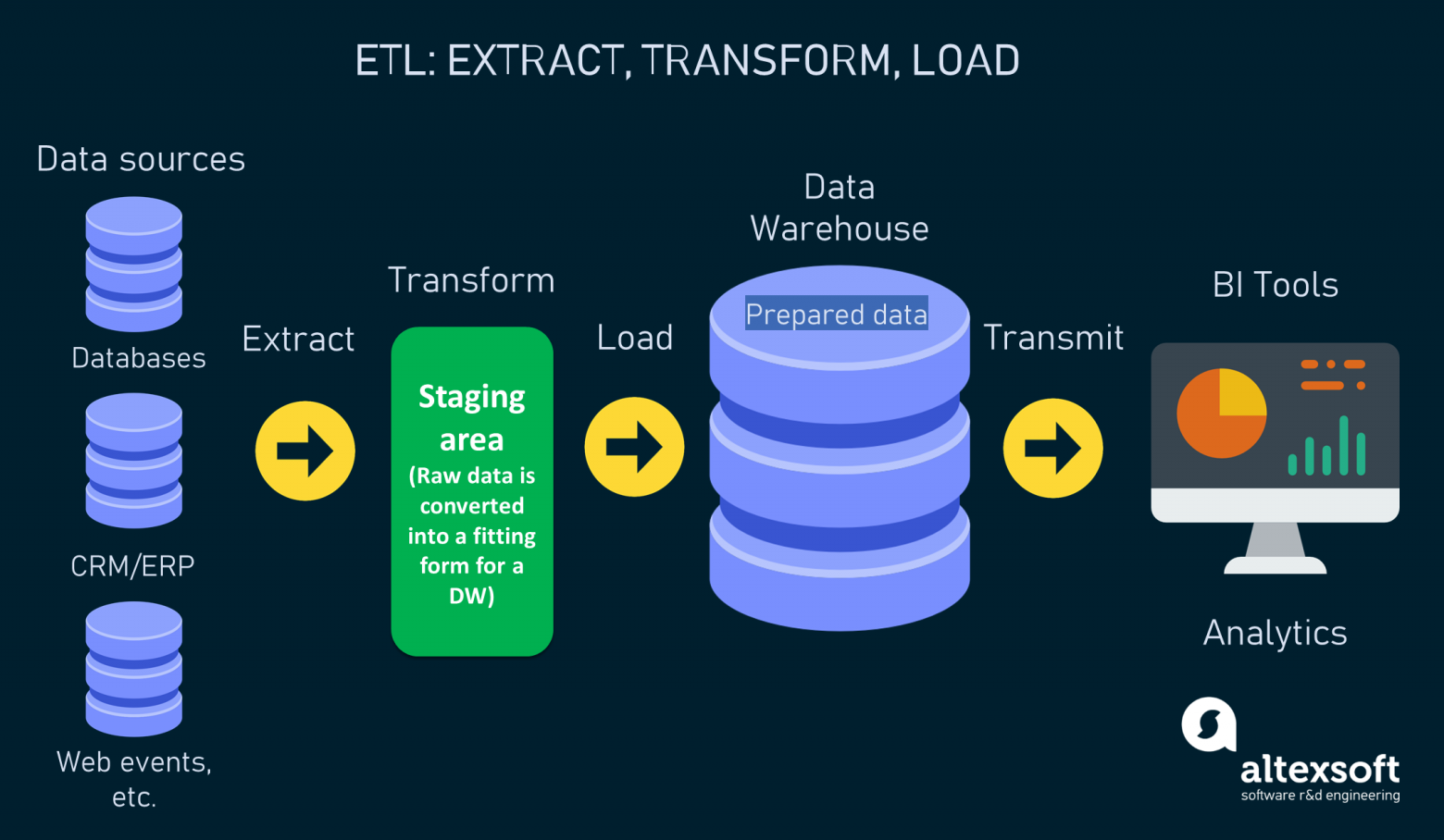
При потоковой обработке данных на этапе Extract сырые данные отправляются в очередь сообщений, на этапе Transform данные очищаются / обогащаются, а на этапе Load направляются в другое хранилище.
ELT (Extract, Load, Transform) — подход к интеграции и обработке данных, при котором порядок этапов отличается от ETL. Данные сначала извлекаются из различных источников, затем в исходном (сыром) виде загружаются напрямую в целевое хранилище (например, Data Lake), и только после этого проходят необходимые преобразования уже внутри этого хранилища.
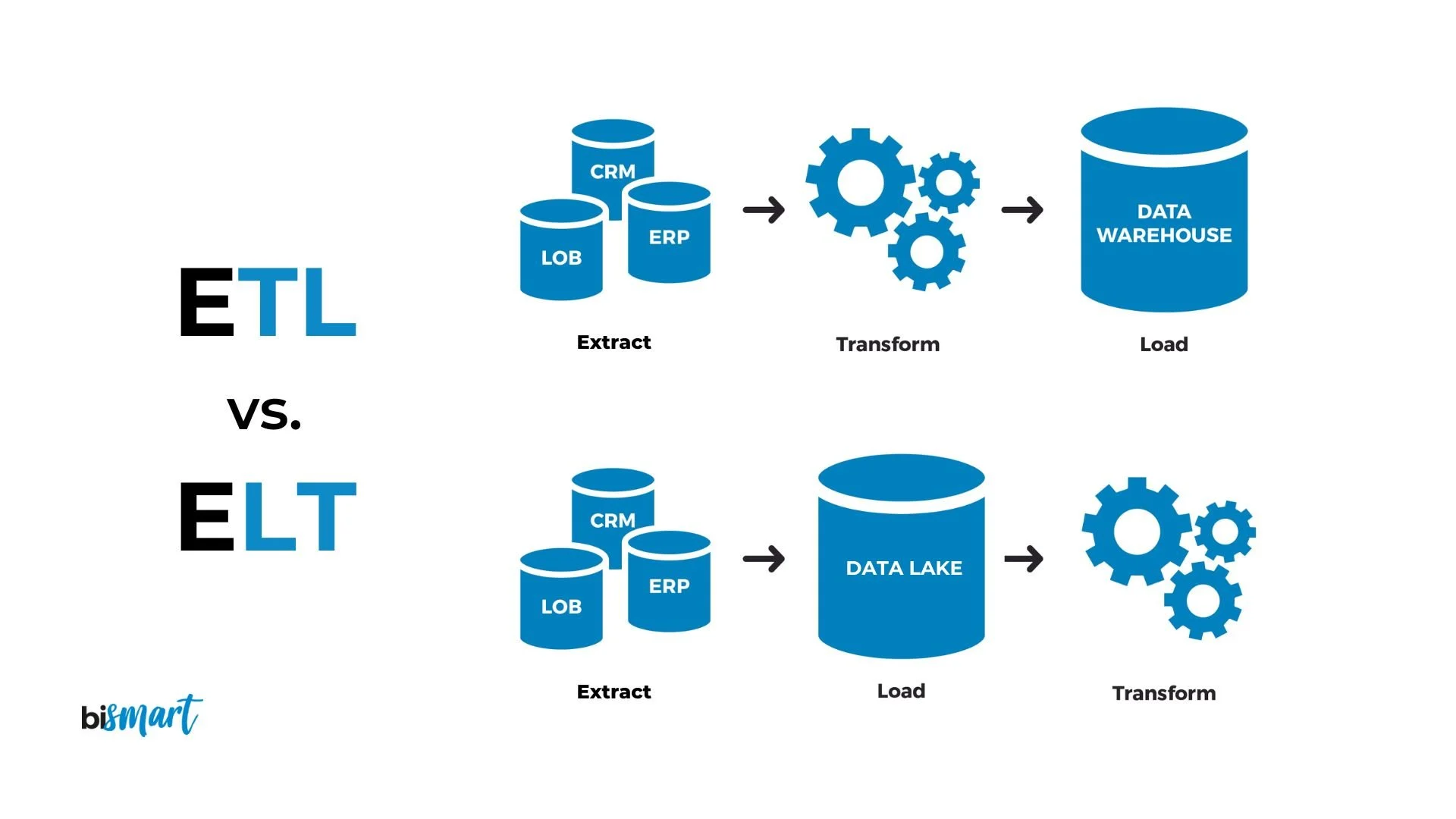
Data Warehouse (хранилище данных) — специализированная система для хранения, консолидации и управления большими объемами структурированных данных, которые собираются из разных источников.
Data Lake (озеро данных) — репозиторий, предназначенный для хранения огромных объемов данных в их исходном, необработанном виде (RAW-формате).
| Параметр | Data Warehouse | Data Lake |
|---|---|---|
| Тип данных | Структурированные | Любые (структурированные, полу-, неструктурированные) |
| Схема хранения | Заранее определена (schema-on-write) | Определяется при чтении (schema-on-read) |
| Подготовка данных | Данные очищаются и структурируются до загрузки | Хранятся в сыром виде, обработка по необходимости |
| Основные задачи | Бизнес-аналитика, отчеты, исторический анализ | Big Data, ML, хранение сырых данных, исследовательский анализ |
| Масштабируемость | Ограничена, дороже | Высокая, дешевле |
| Инструменты | BI, OLAP | Data Science, ML, Big Data |
Рассмотренная в ЛР 4 СУБД ClickHouse может выступать в качестве DWH в некоторой системе для обработке больших данных
¶ Цель работы
Научиться выполнять потоковую обработку данных с использованием Apache Kafka и Apache Spark Structured Streaming.
¶ Предварительная подготовка
- для выполнения работы вам потребуется 3 виртуальных машины (при этом на одной из них должны быть установлены Hadoop и Spark)
- переименуйте виртуальные машины:
- машину
ClickHouseназовемKafka(у меня 192.168.56.101) - машину
Spark (Hadoop)назовемSpark Streaming(у меня 192.168.56.102) - машину с
DataNodeназовемData Generator(у меня 192.168.56.103)
- машину
- эти названия будут использоваться далее в инструкции
- Python 3 установлен по умолчанию на Ubuntu
¶ Задачи работы:
¶ Установка Kafka
- подключитесь к машине
Kafka - установите
Kafka, выполнив команды
# установка JRE
sudo apt install default-jre
# загрузка архива с Kafka
curl -LO https://dlcdn.apache.org/kafka/3.7.0/kafka_2.12-3.7.0.tgz
# распаковка архива
tar -xvzf kafka_2.12-3.7.0.tgz
- (необязательно) откройте файл kafka_2.12-3.7.0/config/server.properties и добавьте в конец строку
delete.topic.enable = true(чтобы была возможность удалять топики) - для удобства переименуйте папку kafka_2.12-3.7.0 в kafka
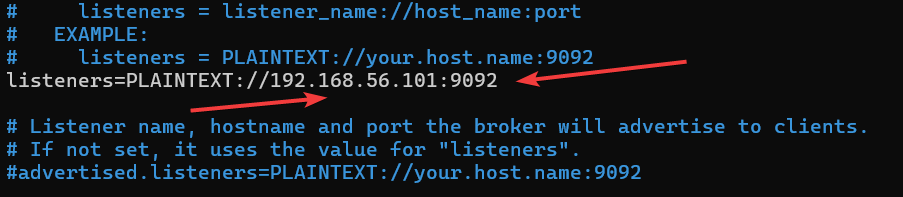
- откройте файл
kafka/config/server.properties - укажите в качестве значения свойства
listenersIP-адрес машины Kafka (текущей машины)
- запустите службы
ZookeperиKafka(следите за путями)
# запуск вспомогательной службы Zookeper (в конце команды &)
/home/mikhail/kafka/bin/zookeeper-server-start.sh /home/mikhail/kafka/config/zookeeper.properties &
# запуск службы Kafka
/home/mikhail/kafka/bin/kafka-server-start.sh /home/mikhail/kafka/config/server.properties &
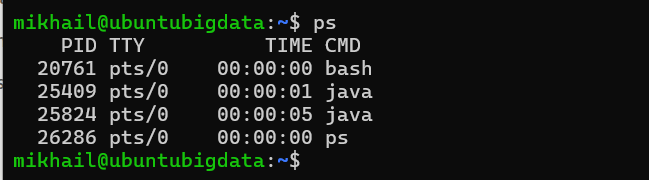
- при выполнении команды
psувидите 2 запущенных Java-приложения (ZookeperиKafka)
- для проверки работоспособности Kafka откройте в браузере страницу http://IP:9092; если Kafka работает, вы получите ERR_EMPTY_RESPONSE
- обратите внимание, что все логи сервисов
ZookeperиKafkaотправляются в терминал
¶ Создание топика. Публикация и подписка
- откройте еще один терминал и подключитесь к машине
Kafka - в любом из терминалов создайте топик командой:
# создается топик с именем “logs”
~/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.56.101:9092 --topic logs
- в одном из терминалов отправьте сообщение в топик командой:
echo "Hello" | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.56.101:9092 --topic logs
- в другом терминале подпишитесь на обновления топика командой:
~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092 --topic logs --from-beginning
- теперь попробуйте публиковать в первом терминале новые сообщения — вы должны моментально видеть обновления топика во втором терминале; именно так работает брокер сообщений
¶ Реализация сервиса Publisher
Подключитесь к машине Data Generator. Создайте отдельную папку, в ней — виртуальное окружение. Активируйте его. Установите в окружение пакеты faker, kafka-python и numpy. Напишите следующий код и запустите его:
from kafka import KafkaProducer
from faker import Faker
from time import sleep
from numpy import random
from datetime import datetime
faker = Faker()
# здесь укажите IP-адрес вашей машины с запущенной Kafka
producer = KafkaProducer(bootstrap_servers=['192.168.56.101:9092'])
while True:
verbs=['GET', 'POST', 'DELETE', 'PUT']
ualist=[faker.firefox, faker.chrome, faker.safari, faker.internet_explorer, faker.opera]
ip = str(faker.ipv4())
dt = str(datetime.now())
verb = str(random.choice(verbs, p=[0.6,0.1,0.1,0.2]))
uri = str(faker.uri())
ua = str(random.choice(ualist, p=[0.5,0.3,0.1,0.05,0.05])())
# формируем строку
line = f'{ip}|{dt}|{verb}|{uri}|{ua}'
# отправляем ее в качестве сообщения в топик logs
# необходимо отправлять строку в бинарном виде
producer.send('logs', line.encode('utf-8'))
# ждем случайное количество секунд от 1 до 3
sleep(random.uniform(1, 3))
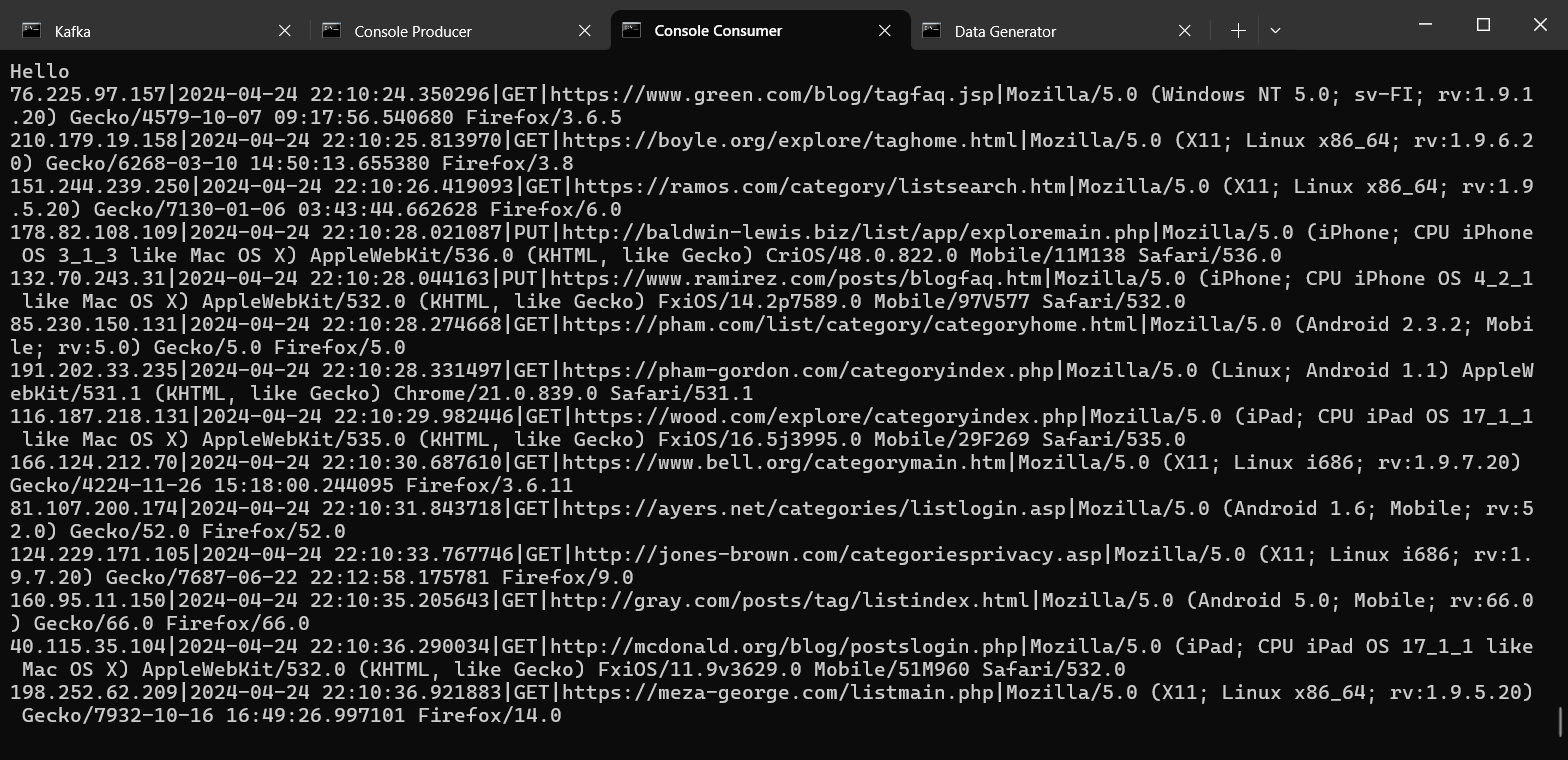
Подпишитесь на машине с Kafka на обновления топика logs:
~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092 --topic logs --from-beginning
Вы должны наблюдать появление новых сообщений в топике (они генерируются сервисом
Publisher, исходный код которого представлен выше)
На данном этапе мы симулируем поступление фейковых данных в брокер сообщений. Осталось реализовать сервис Subscriber и научиться агрегировать потоковые данные.
¶ Реализация сервиса Subscriber
Подключитесь к машине Spark (Streaming). Создайте отдельную папку, в ней — виртуальное окружение. Активируйте его. Установите в окружение пакет pyspark. Напишите следующий код (подключение к брокеру сообщений):
import os
# не меняем
# здесь указываются подключаемые зависимости для работы с Kafka
# они скачиваются с репозитория Maven Central
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.5.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 pyspark-shell'
from pyspark.sql import SparkSession
# это база
spark = SparkSession.builder\
.master('local[*]')\
.appName('Spark Structured Streaming Test')\
.getOrCreate()
# указывае, откуда читаем поток (сервер с Kafka), а также название топика
# в результате сразу же получаем динамический DataFrame
df = spark \
.readStream \
.format('kafka') \
.option('kafka.bootstrap.servers', '192.168.56.101:9092') \
.option('subscribe', 'logs') \
.load()
# создаем поток вывода в консоль
# ожидаем завершения потока
df.writeStream.format('console') \
.start() \
.awaitTermination()
Запустите этот код, а также запустите генерацию данных (приложение Publisher на машине Data Generator). Вы должны наблюдать поступление потоковых данных:
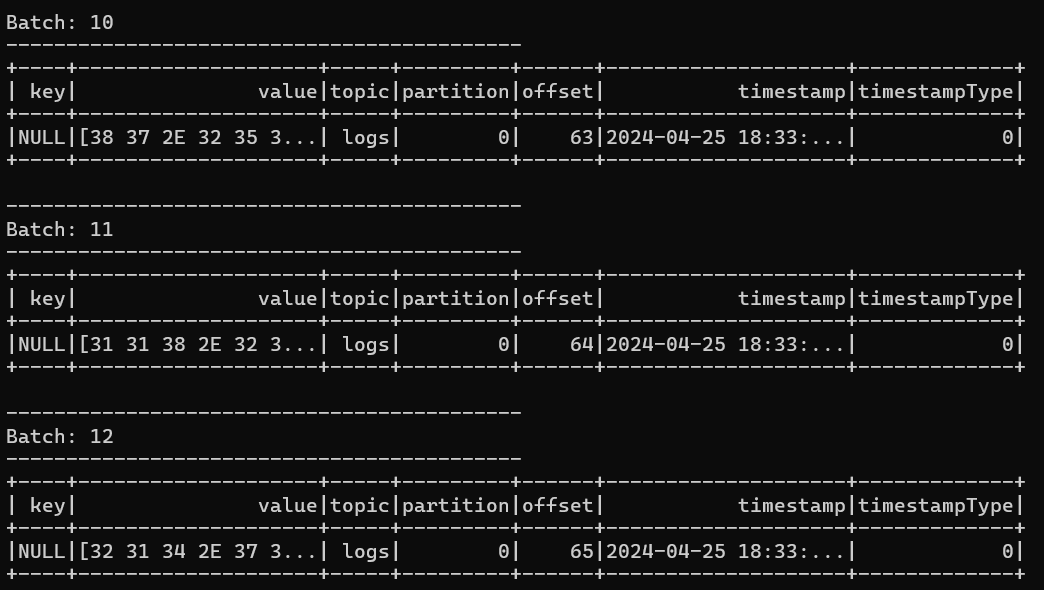
Потоковые данные в общем виде поступают батчами (пакетами), но сейчас у нас каждый батч содержит одно сообщение (в бинарном формате). Процесс обработки потоковых данных в Spark включает в себя преобразование данных к нужному виду и выполнение агрегаций (при необходимости).
¶ Решите следующую задачу (допишите исходный код сервиса Subscriber)
- организуйте считывание данных из топика logs каждые 10 секунд (данные будут группироваться и попадать в один батч)
- напишите схему данных и используйте ее для преобразования сырого потока данных в структурированный (данные в бинарном формате → строка в формате csv → строка в DataFrame, состоящая из именованных столбцов)
- выполните группировку всех данных по методу (поле
verb) - посчитайте количество запросов для каждого метода (агрегация
count) - при выполнении группировки и агрегации не забудьте поменять
outputMode
Ожидаемый результат:
- до группировки (outputMode = ‘append’, по умолчанию)
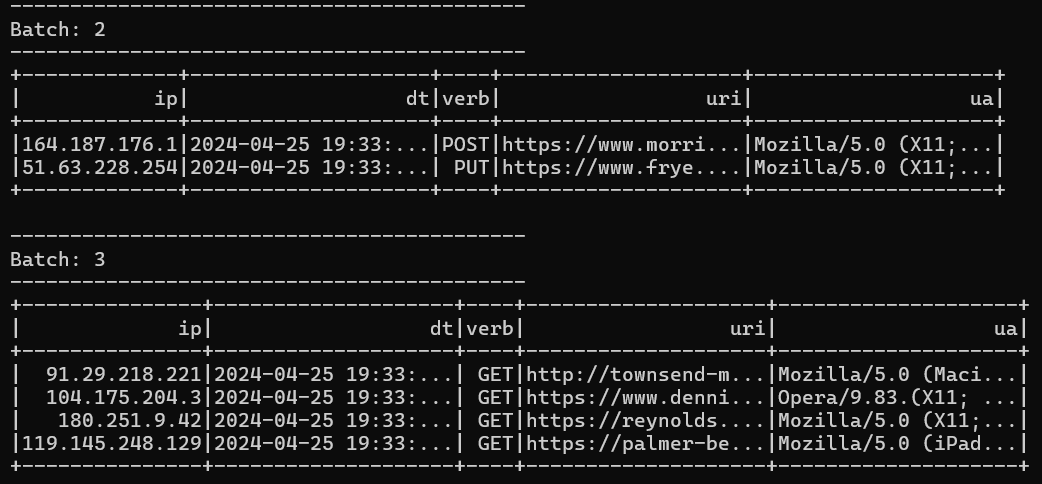
- после группировки и агрегации (outputMode = ‘complete’)

Материалы, которые очень помогут:
- статья, откуда можно взять большую часть необходимой информации и примеров
- про Data Definition Language (DDL)
- еще про схему и DDL
- про from_csv
- про outputMode
¶ Критерии приема работы:
- установлен и работает брокер сообщений
Kafka - сообщения отправляются и читаются из топика
- написан и работает сервис
Publisherдля генерации логов и записи их в очередь - написан и работает сервис
Subscriber(с использованиемSpark Streaming), работает чтение логов из топика - решена задача потоковой группировки и агрегации логов
¶ Последнее слово Гуненкова
Дорогой друг!
Ты только что увидел последнюю лабораторную работу по дисциплине "Технологии больших данных". А это значит, что я могу тебя поздравить: ты сделал большой шаг в мир математического обеспечения и администрирования информационных систем (осталось не так много).
Может показаться, что это все не нужно  Возможно, для кого-то это действительно окажется правдой. Но наш с Иваном Владимировичем опыт в сфере ИТ показывает, что знать команды Linux и уметь работать по SSH — солидно, практиковать Ansible и IaC в целом — уважаемо, разворачивать собственный Hadoop-кластер с распределенной файловой системой — достойно.
Возможно, для кого-то это действительно окажется правдой. Но наш с Иваном Владимировичем опыт в сфере ИТ показывает, что знать команды Linux и уметь работать по SSH — солидно, практиковать Ansible и IaC в целом — уважаемо, разворачивать собственный Hadoop-кластер с распределенной файловой системой — достойно.
А что по поводу больших данных? Мы изучили и попробовали на практике пакетную и потоковую обработку. Рассмотрели востребованные инструменты. Мы осознали концепции ETL и ELT, понимаем, для чего нужны столбчатые СУБД и почему брокеры сообщений получили настолько лютый хайп.
Если у тебя есть желание, предлагаю оставить отзыв по лабораторным работам в этой форме. Мы стремимся быть лучше!
Желаю тебе не сдаваться и сохранять мотивацию. Если ты действительно намерен стать специалистом, у тебя все получится. Спасибо за внимание и работу. Успехов во всем, коллега!
М. Ю. Гуненков