¶ Основная теория
¶ Брокеры сообщений
Ранее мы строили конвейеры, которые запускались по расписанию или привязывались к готовности других данных. Однако в реальных системах задачи часто возникают в случайные моменты времени — пользователь нажимает кнопку "Найти время для переноса занятия" в веб-интерфейсе.
При решении таких задач используются брокеры сообщений. Это промежуточное ПО, которое принимает сообщения от отправителей (Producer), маршрутизирует их и сохраняет в очереди (Queue), откуда их забирают получатели (Consumer).
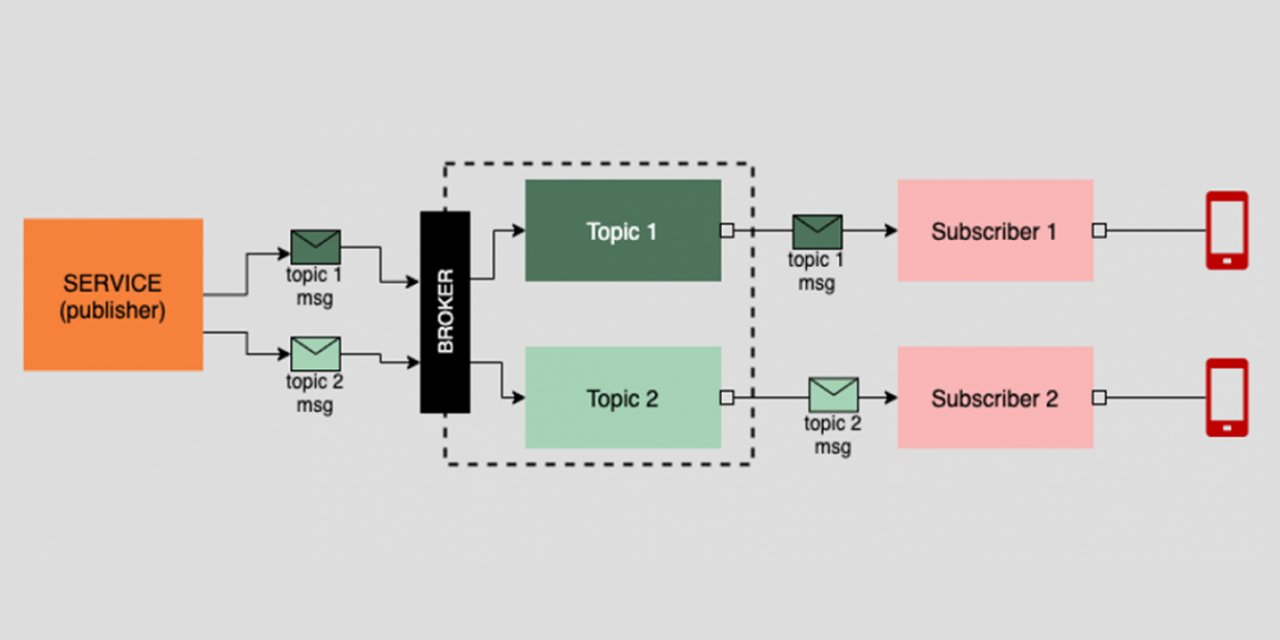
В разработке высоконагруженных приложений брокеры сообщений позволяют настроить взаимодействие микросервисов (в рамках микросервисной архитектуры). При работе с большими данными брокеры сообщений применяются для сбора и обработки данных.
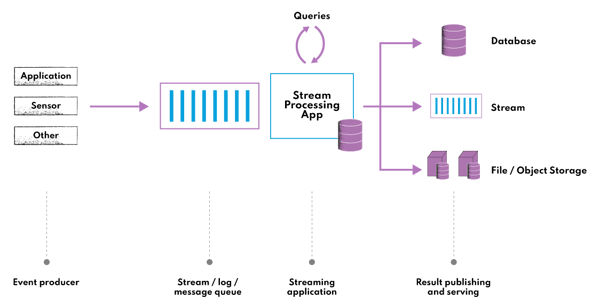
Примеры: RabbitMQ, Apache Kafka, IBM MQ и многие другие
RabbitMQ — брокер сообщений с открытым исходным кодом, реализующий протокол AMQP (Advanced Message Queuing Protocol).
Основные сущности:
- Producer: приложение, отправляющее сообщения
- Exchange: маршрутизатор, который решает, в какую очередь отправить сообщение на основе правил
- Queue: буфер, в котором сообщения хранятся до тех пор, пока их не заберет потребитель
- Consumer: приложение, читающее сообщения из очереди
Важным отличием брокеров сообщений от HTTP-запросов является механизм подтверждения. Если Consumer начал обрабатывать сообщение и упал с ошибкой, то сообщение не должно потеряться. RabbitMQ будет хранить сообщение в очереди до тех пор, пока Consumer явно не отправит сигнал об успешном завершении работы — ack (от acknowledgment).
¶ Event-Driven подход
Как это работает:
-
Сервис-продюсер (приложение) получает запрос от пользователя
-
Сервис-продюсер кладет параметры тяжелой задачи в очередь RabbitMQ
-
Сервис-потребитель забирает сообщение из очереди, выполняет вычисления и отправляет ответ в другую очередь RabbitMQ
-
Сервис-продюсер получает результат из соответствующей очереди и предоставляет его пользователю (вызывает другой скрипт)
¶ Планирование переносов занятий
Задача переноса занятий сводится к поиску пересечения свободных интервалов времени с учетом ограничений. При поиске слота для переноса пары нужно убедиться, что выполняются следующие условия:
- свободен преподаватель
- свободна группа / подгруппа
- свободна аудитория
- не более 4 занятий в день у группы / подгруппы
- отсутствие окон (или не более 1 пары в качестве окна)
¶ Цель
Развернуть локально брокер сообщений RabbitMQ и реализовать событийно-ориентированную архитектуру обработки запросов. Разработать независимый сервис-потребитель, который читает входящие запросы на поиск оптимального времени для переноса занятий из очереди RabbitMQ, выполняет расчет свободных слотов на основе витрины данных в ClickHouse и публикует сформированный результат в очередь ответов RabbitMQ.
¶ Несколько практических советов
Вам потребуется расширить набор данных, который вы загружали и обрабатывали в предыдущих лабораторных работах
В ЛР 2 можно сделать так, чтобы функция get_teachers стала функцией get_targets и возвращала примерно такую структуру:
[
{"type": "person", "id": 1},
{"type": "group", "id": 1},
{"type": "auditorium", "id": 1}
]
Задача на получение данных из расписания должна учитывать type и выполнять соответствующие запросы.
Рекомендуется изменить партиционирование: /user/airflow/schedule/year=.../month=.../day=.../type=.../id=.../schedule.json. Предлагается, чтобы DAG с PySpark читал все записи за конкретную дату.
Структура JSON для преподавателя, группы и аудитории обычно одинакова (список занятий). Необходимо обрабатывать дубликаты с применением PySpark
Убедитесь, что DAG из ЛР 2 скачивает расписание не только для преподавателя, но и для связанных с заданием групп и аудиторий. Самостоятельно определите списки сущностей
DAG из ЛР 3 должен корректно объединять эти данные в ClickHouse, предварительно удаляя дубликаты занятий
¶ Задание
¶ Подготовка
Отредактируйте docker-compose.yaml, добавив новый сервис в секцию services:
rabbitmq:
image: rabbitmq:3-management
container_name: rabbitmq
ports:
- "5672:5672"
- "15672:15672"
volumes:
- rabbitmq_data:/var/lib/rabbitmq
healthcheck:
test: ["CMD", "rabbitmq-diagnostics", "-q", "ping"]
interval: 10s
timeout: 10s
retries: 5
restart: always
Отредактируйте секцию volumes и добавьте новый том:
...
volumes:
...
rabbitmq_data:
Внимательно следите за отступами. При необходимости используйте один из сервисов для валидации YAML
Пересоберите и запустите контейнеры (docker compose up -d --build). При необходимости запускайте без флага -d. Перейдите по адресу http://localhost:15672 (логин и пароль по умолчанию guest / guest).
В веб-интерфейсе RabbitMQ перейдите на вкладку Queues and Streams и вручную создайте очереди reschedule_requests и reschedule_responses.
На практике в реальных задачах рекомендуется декларировать очереди в сервисах
¶ Разработка сервиса Producer
Создайте локальный скрипт producer.py. Этот скрипт должен:
- формировать сообщение в формате JSON с запросом (пример):
{"request_id": "1", "teacher_id": 12, "group_id": 4, "auditorium_id": 3, "subject": "Технологии больших данных"}
В структуру сообщения можно добавить информацию о периоде, в котором следует искать слоты (
start_dateиend_date)
- подключаться к RabbitMQ (
localhost:5672) с помощью библиотекиpikaи публиковать сообщение в очередьreschedule_requests
По умолчанию библиотека
pikaможет использовать автоматическое подтверждение сообщений (auto_ack=True). Следует отключить его и отправлять подтверждение вручную только после того, как скрипт-потребитель успешно выполнил запросы и отправил ответ
¶ Разработка сервиса Consumer
Реализуйте скрипт consumer.py, который:
- подключается к RabbitMQ (библиотека
pika), слушает очередьreschedule_requests - при получении сообщения подключается к ClickHouse и выполняет SQL-запросы к витрине для извлечения информации о занятости на неделю / месяц / другой выбранный период
- выполняет поиск слотов (количество можете определить самостоятельно) с применением ограничений
- публикует результат (слоты) в формате JSON в очередь
reschedule_responses - явно подтверждает успешную обработку исходного сообщения (
basic_ack), чтобы оно удалилось из очередиreschedule_requests
Обратите внимание на то, чтобы
request_idбыл указан в JSON с результатом
¶ Критерии приемки
- поднят контейнер с RabbitMQ и доступен его веб-интерфейс
- в DAGи из предыдущих ЛР внесены изменения: скачиваются данные по группам/аудиториям/преподавателям, реализовано удаление дубликатов
- реализован скрипт, который успешно отправляет сообщение в очередь
reschedule_requests - реализован сервис, который слушает очередь
reschedule_requestsи обрабатывает входящие сообщения - алгоритм корректно определяет свободные слоты
- используется механизм ручного подтверждения, сервис-потребитель подтверждает успешную обработку сообщения после завершения вычислений
- результат работы можно увидеть в веб-интерфейсе RabbitMQ в очереди
reschedule_responses - студент может ответить на вопросы преподавателя, касающиеся Airflow, брокеров сообщений, Event-Driven подхода, а также на другие смежные вопросы, позволяющие оценить самостоятельность выполнения задания и понимание хода работы