¶ Основная теория
¶ Apache Spark и PySpark
Ранее мы научились собирать сырые данные и складывать их в DataLake на основе HDFS. Однако сырые JSON-файлы неудобно использовать для построения витрин и последующей аналитики. Их нужно очистить, преобразовать в плоскую табличную структуру и отфильтровать (Silver Layer). Для ресурсоемких распределенных вычислений стандартом индустрии является Apache Spark.
Spark — фреймворк для распределенной обработки неструктурированных и слабоструктурированных данных в оперативной памяти. Он состоит из следующих компонентов:
- Core — ядро фреймворка
- Spark SQL — инструмент обработки данных с помощью SQL-запросов
- Streaming — инструмент потоковой обработки данных
- MLLib — набор инструментов машинного обучения
- GraphX — инструмент обработки графов
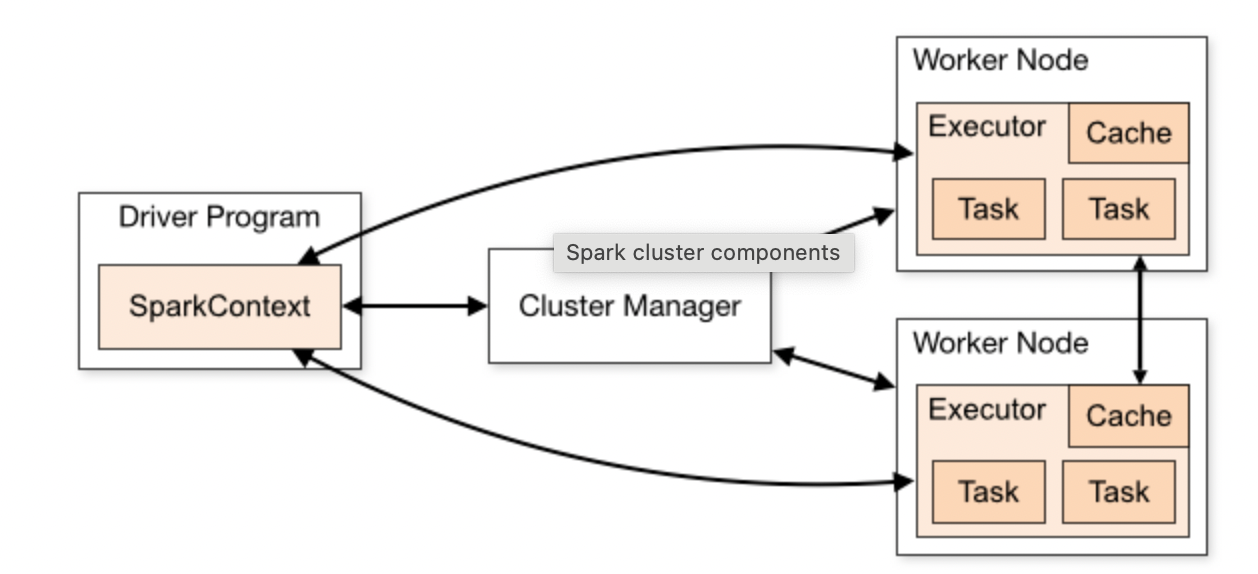
Мы будем использовать локальный режим
Основными абстракциями в Spark являются Resilient Distributed Dataset (RDD) и DataFrame. Для работы с Apache Spark существуют API на самых разных языках программирования (Java, Python, Scala, R). Мы будем использовать PySpark.
Базовой концепцией являются ленивые вычисления: фреймворк не выполняет вычисления сразу при вызове трансформаций (filter, select); строится оптимальный план выполнения (DAG); вычисления запускаются только при вызове действия (write, show, count)
Для хранения данных на слое Silver будем использовать Apache Parquet — колоночный формат хранения данных (сохраняет схему данных внутри себя, отлично сжимается).
¶ Колоночная СУБД ClickHouse
После обработки данных в Spark (создания слоя Silver) их нужно загрузить в базу данных, оптимизированную для быстрых аналитических запросов (слой Gold). Для этих целей отлично подходят колоночные СУБД.
Классические реляционные системы управления базами данных (MS SQL Server, MySQL, PostgreSQL) являются строчными:

Значения, относящиеся к одной строке, физически хранятся рядом. В колоночных СУБД все наоборот:
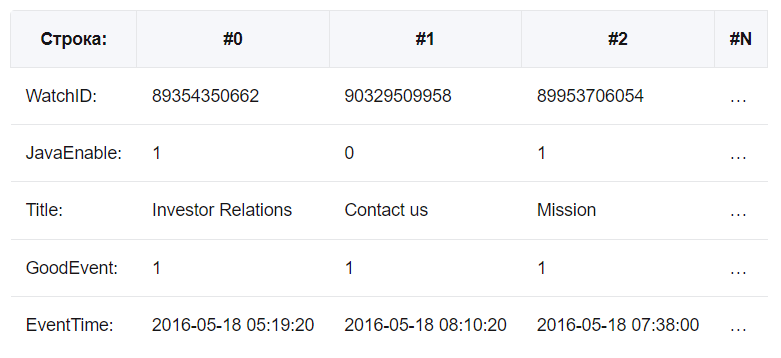
Разный порядок хранения данных подходит для разных сценариев работы.
Классический OLTP-сценарий (Online Transaction Processing):
- подавляющее большинство запросов — на запись данных
- данные обновляются часто, но небольшими пакетами
- при чтении извлекаются небольшие пакеты данных
- запросы идут сравнительно часто
Сценарий извлечения и обработки больших данных, OLAP-сценарий (Online Analytical Processing):
- подавляющее большинство запросов — на чтение данных
- данные либо не обновляются, либо обновляются большими пакетами
- при чтении извлекаются большие пакеты данных (требуется высокая пропускная способность сервера)
- запросы идут сравнительно редко
Для OLTP-сценария целесообразно применять строковые базы данных, а для OLAP-сценария — колоночные
Примеры колоночных СУБД: ClickHouse, Cassandra, Snowflake, Amazon Redshift и BigQuery.
В рамках лабораторной работы мы будем работать с СУБД ClickHouse, разработку которой начинал Яндекс. ClickHouse был разработан для решения задач веб-аналитики для Яндекс Метрики — третьей по популярности системы веб-аналитики в мире. В настоящее время ClickHouse используют Cloudflare, ВКонтакте, Т-Банк и другие.
Особенности ClickHouse:
- реализовано эффективное сжатие данных
- поддерживаются сложные типы данных: JSON, UUID, Point, Array, Map и другие
- реализована параллельная обработка запросов на нескольких ядрах
- реализована распределенная обработка в кластере
- поддерживается шардирование и репликация
Основная идея выделения слоя Silver — переиспользование данных: если завтра решим обучить ML-модель для предсказания отмены пар, то пойдем не в ClickHouse, а возьмем готовые Parquet-файлы из Silver слоя прямо в HDFS
В результате наших действий получим Data Lakehouse (связку Data Lake + Data Mart)
¶ Цель работы
Разработать конвейер в Airflow, который автоматически запускается при обновлении сырых данных в HDFS, преобразует JSON в Parquet с помощью PySpark и загружает витрину данных в ClickHouse для построения аналитики.
¶ Задание
¶ Подготовка
Используйте обновлённые файлы для развёртывания (с заменой).
Запустите контейнеры с повторной сборкой образов (docker compose up -d --build) и проверьте localhost:8123 (должно появиться слово Ok.). Если ошибки, то остановите контейнеры и запустите их без флага -d (либо используйте docker logs).
Перейдя к localhost:8123/play можно выполнять в браузере SQL-запросы в ClickHouse:
Обратите внимание: в
docker-compose.yamlзаданы логин (default) и пароль (airflow) для подключения к БД ClickHouse. Также настроено автоматическое создание БДrasp_omgtu(можете работать с ней, а можете создать другую)
Создайте новый Connection с типом HTTP. Host: clickhouse. Port: 8123. Укажите пароль к БД ClickHouse, чтобы не хардкодить его, а получить потом через хук.
Создайте файл для .py для описания нового DAG.
Используя механизм Asset-Aware Scheduling свяжите новый DAG с DAG из ЛР 2.
Новый DAG должен запускаться автоматически при появлении новых данных на слое Bronze. Но слой Silver не должен полностью пересоздаваться. Подсказка: используйте общий ассет и
logical_date
Подумайте внимательно, какие поля в сырых данных вам потребуются в дальнейшем для решении задачи поиска дат переноса занятий данного преподавателя (с учетом доступности группы и аудитории), а также для общей аналитики (какие пары и в каком количестве ведет конкретный преподаватель). Состав полей можно будет изменить в ходе выполнения последующих лабораторных работ.
¶ Первая task
Реализуйте загрузку всех сырых файлов в директории за нужный день (logical_date) с применением PySpark. Очистите данные (выберите только нужные поля) и сохраните их в формате Parquet с нужной схемой (рекомендуется определить для сохранения отдельный базовый путь со словом silver, например /user/airflow/silver/schedule/). Не забывайте о партиционировании и следите за идемпотентностью (режим overwrite).
Необходимо обрабатывать именно те периоды, с которыми работал DAG из ЛР 2, сохраняющий расписание в сыром виде
¶ Вторая task
С помощью хука и clickhouse-connect реализуйте сохранение данных в таблицу ClickHouse. Сделайте так, чтобы ClickHouse в запросе читал данные формата .parquet напрямую из HDFS (функция hdfs(...)). Будьте аккуратны и следите за идемпотентностью (удаляйте партицию перед записью данных за текущий день).
Таблица должна быть создана с ключем партиционирования по дате (
PARTITION BY)
¶ Аналитика
Напишите SQL-запрос для ClickHouse, позволяющий получить агрегированные данные о количестве пар по видам занятий у каждого преподавателя за некоторый установленный период. Убедитесь с помощью веб-интерфейса ClickHouse, что запрос действительно выполняется возвращает нужные данные.
¶ Критерии приемки
-
в интерфейсе Airflow на вкладке Assets визуально отображается связь между графом сбора данных (ЛР 2) и новым графом обработки (ЛР 3)
-
при ручном запуске DAGа из ЛР 2 после его успешного завершения автоматически стартует DAG из ЛР 3
-
в HDFS (смотрим через веб-интерфейс) находятся сгенерированные Spark файлы с расширением .parquet с учетом партиционирования
-
обработанные данные в формате
.parquetсохранены в таблицу БД ClickHouse, это можно проверить SQL-запросом через веб-интерфейс -
студент может выполнить в веб-интерфейсе SQL-запрос на получение агрегированных данных о количестве пар по видам занятий у каждого преподавателя за некоторый установленный период; запрос возвращает корректные данные
-
студент понимает и может объяснить концепцию Data Lakehouse (зачем нужен Parquet в Silver слое, если есть ClickHouse), разницу между строковой и колоночной СУБД, а также может ответить на другие теоретические вопросы