¶ Основная теория
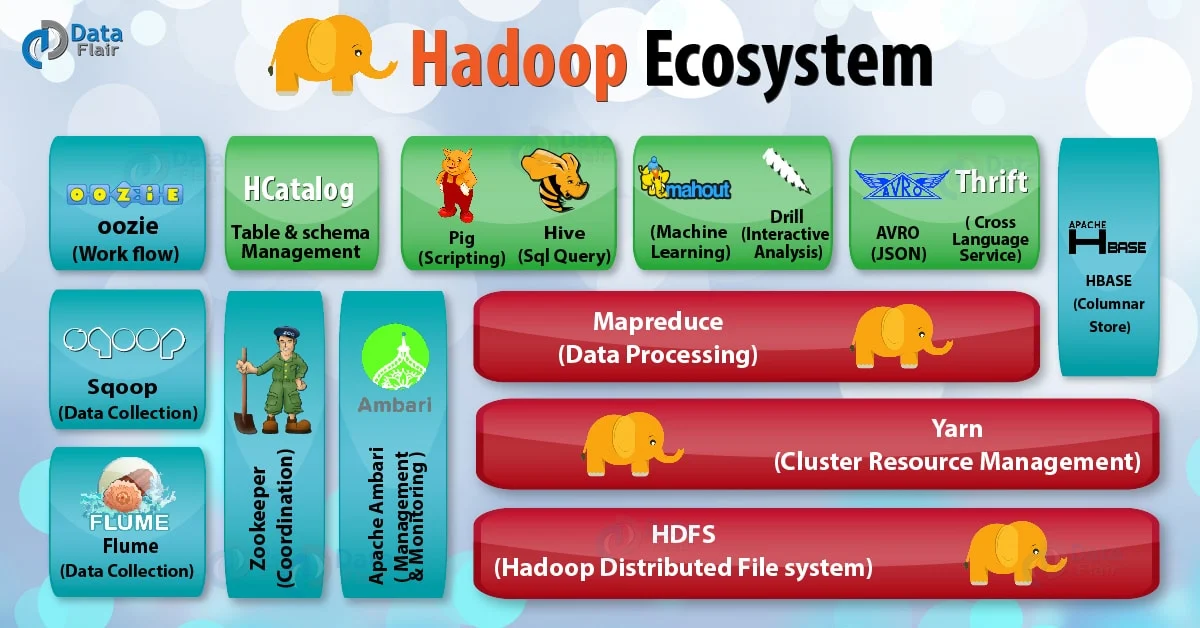
¶ Что такое Hadoop
Hadoop - это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах. Кластер представляет собой множество связанных узлов (нод).
Основные компоненты Hadoop:
- Hadoop Common - связующее программное обеспечение, инфраструктурные библиотеки
- Hadoop Distributed File System (HDFS) - распределенная файловая система
- Yet Another Resource Negotiator (YARN) - система управления кластером и планирования заданий
- Hadoop MapReduce - платформа программирования в парадигме MapReduce (приложение разбивается на множество элементарных заданий, которые выполняются параллельно и далее объединяются в общий результат)
Экосистема Hadoop также включает в себя различные СУБД, инструменты для реализации алгоритмов ML и многое другое.
¶ Как работает HDFS?
На рисунке ниже приведена общая схема HDFS:
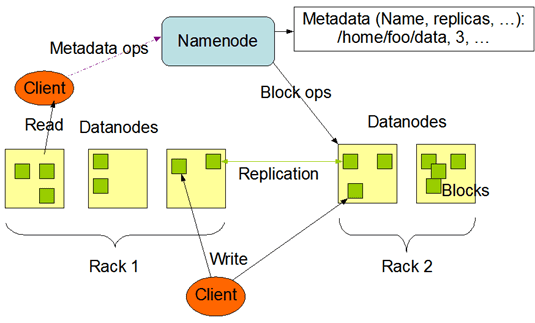
Как и в любой файловой системе HDFS представляет собой набор папок и файлов
Файлы в HDFS хранятся в виде блоков размером по умолчанию 128 мб. Каждый блок может реплицироваться (копироваться и храниться в виде нескольких реплик)
Основными составляющими HDFS являются:
- Namenode — нода, на которой запущено ПО, которое отвечает за хранение информации о расположении реплик каждого блока и другой метаинформации; Namenode также отвечает за ведение журнала транзакций (изменений файлов) и регулярный опрос (heartbeats) нод с данными (если нода не отвечает, значит считается, что она не работает)
- Datanode — нода, на которой непосредственно размещаются реплики блоков; при выполнении репликации рекомендуется хранение реплик одного блока на различных серверных стойках (rack) - в HDFS существует встроенный механизм rack awareness; на Datanode запущено свое ПО, которое является частью HDFS
- Клиент — приложение, взаимодействующее с HDFS через какой-либо API (например через терминал)
¶ Запись файла
- клиент запрашивает у NameNode разрешение на запись
- NameNode выделяет блоки и указывает, на какие DataNode записывать данные
- клиент записывает данные напрямую в DataNode
- DataNode реплицируют данные на другие узлы
¶ Чтение файла
- клиент запрашивает у NameNode список блоков файла
- NameNode возвращает список блоков и их расположение
- клиент читает данные напрямую с DataNode
¶ Удаление файла
- клиент отправляет запрос на удаление в NameNode
- NameNode обновляет метаданные и отправляет команду на удаление блоков в DataNode
Основная задача HDFS - распределенное хранение файлов большого объема, обеспечивающее высокую скорость чтения/записи.
Основной недостаток HDFS: Namenode является единой точкой отказа системы (в реальных системах применяется Secondary Namenode - реплика Namenode, однако это не спасает ситуацию).
В этой лабораторной работой мы организуем кластер и запустим HDFS на двух виртуальных машинах (одна будет Namenode, другая - Datanode). Очевидно, что нам придется выполнять команды по SSH на каждой машине. И вам может показаться, что мы будем делать это вручную. Но мы не будем. Потому что в этой работе мы знакомимся не только с HDFS, но и с такой полезной вещью как Ansible.
¶ Infrastructure as Code (IaC)
Infrastructure as Code (IaC) — это современный подход к управлению инфраструктурой, который позволяет:
- описывать инфраструктуру в виде кода
- автоматизировать развертывание и управление
- обеспечивать согласованность, надежность и масштабируемость
Ansible — это один из популярных инструментов для реализации подхода Infrastructure as Code, который предполагает, что все описание процессов настройки инфраструктуры и запуска приложений осуществляется не с помощью выполнения команд, а посредством применения конфигурационных файлов.
Ansible является системой управления конфигурациями. Написан на Python, поддерживает использование пользовательских модулей. Конфигурации пишутся с использованием декларативных языков разметки (YAML, INI). Ansible устанавливается из PyPI. Одной из основных особенностей является обеспечение идемпотентности.
Идемпотентность заключается в том, что применение кода инфраструктуры несколько раз приводит к одному и тому же результату
Основные составляющие Ansible:
- инвентарные файлы — содержат информацию об управляемых хостах (чаще всего хосты объединяются в группы)
- модули и команды (именованные модули) — конкретные инструкции с параметрами; выполняются по порядку сверху вниз; как правило объединяются в роли или используются в плейбуках; в командах можно использовать переменные (на уровне хоста, на уровне группы хостов; можно задавать переменные непосредственно в плейбуках)
- плейбуки — файлы, содержащие несколько команд, которые последовательно выполняются; плейбук описывает порядок выполнения команд (вызова модулей) для выполнения некоторой задачи по настройке инфраструктуры
- роли — наборы команд, выполняемых для конкретной категории управляемых хостов (например, если мы настраиваем сервера БД с PosgreSQL — это одна роль; если разворачиваем микросервисы на FastAPI — другая роль)
¶ Материалы для изучения Ansible:
¶ Цель работы
Научиться организовывать кластер с использованием подхода Infrastructure as Code на примере Hadoop HDFS
¶ Задачи работы
Перед выполнением этой и следующих лабораторных работ убедитесь, что на каждую виртуальную машину выделено минимум 30 GB физической памяти; инструкция по изменению размера логического тома
- клонировать подготовленную для работы с SSH виртуальную машину из ЛР 1 (в конце ЛР 1 мы получили клон, вот его надо 2 раза клонировать); одна из них будет Namenode, другая Datanode
Саму машину из ЛР 1 рекомендуется использовать в качестве управляющий машины — поставить на нее Ansible, подключиться через VS Code по SSH, писать и запускать плейбуки
- включить по очереди Namenode и Datanode, задать машинам разные статические IP-адреса (см. ЛР 1); проверить выполнением команды
pingс вашего компьютера; эти IP не должны совпадать с IP управляющей машины; - на управляющей машине создать виртуальное окружение и установить Ansible через PyPI или Poetry
в Ubuntu уже установлен Python, однако чтобы сделать venv надо будет установить python_venv —
sudo apt install python3.<версия>-venv
- скачать шаблоны файлов конфигураций и копировать их на управляющую виртуальную машину с помощью
scp; при необходимости и желании — создавайте папки (командаmkdir), копируйте (командаcp) или переносите (mv) файлы внутри управляющей виртуальной машины - обеспечить возможность подключения по SSH к машинам Namenode и Datanode без пароля (как в ЛР 1)
- на управляющей машине создать и заполнить инвентарный файл (рекомендуется выделить две группы хостов - одну под Namenode, другую - под Datanode, в перспективе их может быть множество)
- с использованием модулей Ansible написать плейбуки / роли для создания кластера (рекомендуется посетить занятия ЛР, может пригодиться официальная инструкция по настройке кластера); также может пригодиться инструкция для настройке кластера из одной ноды (но учтите, что по ЛР у нас должно быть две ноды)
¶ Основные шаги при установке Hadoop
Предстоит сделать следующее:
- установить на Namenode и Datanode
Java Development Kit 11
используйте пакет
default-jdkс осторожностью, поскольку он устанавливает не конкретную версию JDK, а версию по умолчанию для вашей системы: 11 для Ubuntu 22.04, 21 для Ubuntu 24.04; рекомендуется устанавливать конкретную версию JDK:
Рекомендуется установить пакет
openjdk-11-jdkи сделать JDK 11 версией по умолчанию с помощьюupdate-alternatives
- скачать на Namenode и Datanode Hadoop в виде архива
tarи разархивировать его (можно скачать заранее и передать через scp) - создать нужные папки для Hadoop и скопировать шаблоны файлов конфигурации в нужное место (на Namenode и Datanode)
- добавить переменные
HADOOP_HOME(значение:/home/mikhail/hadoop-3.3.6) иJAVA_HOME(значение:/usr/lib/jvm/default-java, если у вас Ubuntu 22.04, или/usr/lib/jvm/java-11-openjdk-amd64, если вы устанавливали пакетopenjdk-11-jdk) в файл~/.bashrc, обновить переменнуюPATH(значение:$PATH:/home/mikhail/hadoop-3.3.6/bin/), выполнить командуsource ~/.bashrc - открыть файл
<hadoop>/etc/hadoop/hadoop-env.shи ближе к концу в нем раскоментировать строку с установкой переменнойJAVA_HOME(значение переменнойJAVA_HOME:/usr/lib/jvm/default-java) - отключить фаервол на Namenode и Datanode командой
sudo ufw disable - отформатировать Namenode командой
sudo hadoop hdfs namenode -format
Если команда не работает, то выполнить
hdfs namenode -format -force
- на Namenode зайти в папку /sbin и прописать команду
./hadoop-daemon.sh start namenode - на Datanode зайти в папку /sbin и прописать команду
./hadoop-daemon.sh start datanode - на основной машине открыть дашборд в браузере, введя <ip-адрес Namenode>:<порт HDFS> (по умолчанию порт HDFS - 9870); проверить, что он открывается; убедиться, что в кластере есть Datanode
¶ Замечания
- в нашей конфигурации (поскольку машины клонировались) в каждой машине есть некоторый пользователь, от имени которого будем выполнять команды (remote_user); он имеет права администратора на машинах
- запустить плейбук можно командой
ansible-playbook hdfs.yaml -e "ansible_become_pass=пароль для remote_user" - не забудьте про файл
ansible.cfg
значение переменной nameNodeIp для NameNode —0.0.0.0(если будет127.0.0.1, то не получится подключиться с хостовой машины); порт можно оставлять по умолчанию —9000 - для проверки того, что Hadoop запущен в режиме NameNode или DataNode следует использовать команду
jps - если в результате выполнения команды
jpsпосле запуска "демона" вы не видите NameNode или DataNode - проверьте логи; там могут быть ошибки, которые рекомендуется гуглить; логи в папке<hadoop>/logs, ищите файл с раширением.log
¶ Больше материалов по установке и настройке Hadoop (HDFS):
- https://www.dmosk.ru/miniinstruktions.php?mini=hadoop-install
- https://www.youtube.com/watch?v=HAlv7uGi6OE
¶ Результат выполнения работы:
Две виртуальные машины развернуты и настроены. Дашборд HDFS (Namenode UI) открывается в браузере. Представлены артефакты Ansible (инвентарный файл, роли, плейбуки и другие вспомогательные файлы конфигурации).
Как у вас должно выглядеть:
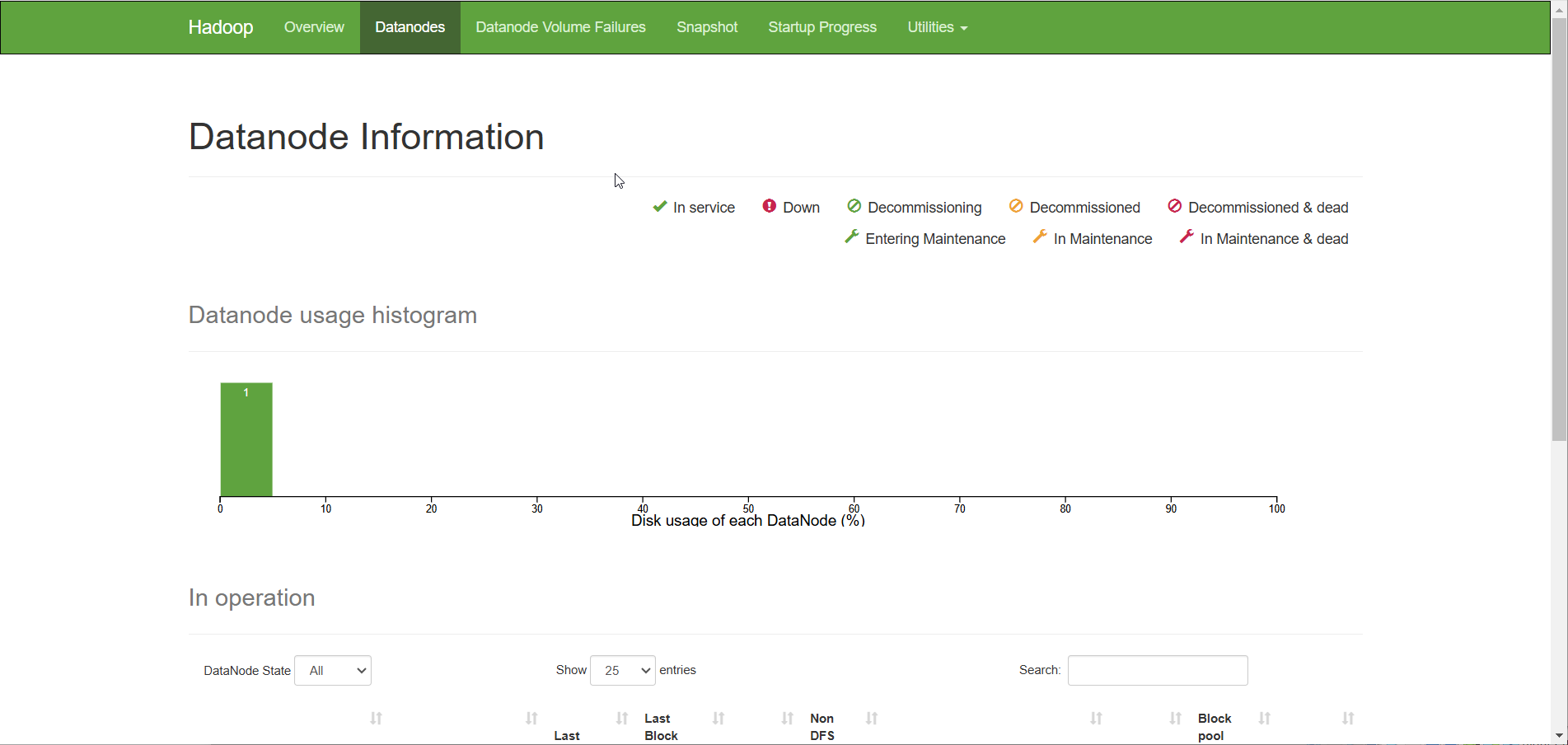
¶ Часто встречающиеся ошибки
- некорректно настроенные файлы конфигурации — убедитесь, что вы их не просто копируйте в Ansible, а именно используете template и подгружаете значения group_vars
- не задана в файле
<hadoop>/etc/hadoop/hadoop-env.shпеременнаяJAVA_HOME - NameNode не отформатирована