¶ Основная теория
¶ Что такое Hadoop
Hadoop - это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах. Кластер представляет собой множество связанных узлов (нод).
Основные компоненты Hadoop:
- Hadoop Common - связующее программное обеспечение, инфраструктурные библиотеки
- Hadoop Distributed File System (HDFS) - распределенная файловая система
- Yet Another Resource Negotiator (YARN) - система управления кластером и планирования заданий
- Hadoop MapReduce - платформа программирования в парадигме MapReduce (приложение разбивается на множество элементарных заданий, которые выполняются параллельно и далее объединяются в общий результат)
Экосистема Hadoop также включает в себя различные СУБД, инструменты для реализации алгоритмов ML и многое другое.
¶ Как работает HDFS?
На рисунке ниже приведена общая схема HDFS:
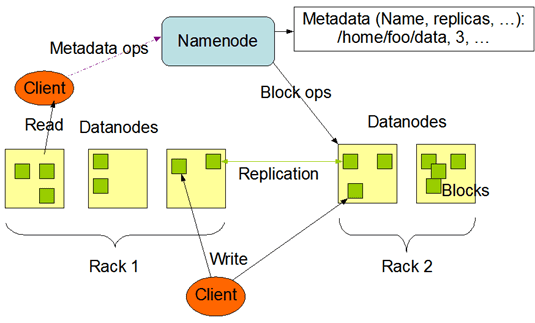
Как и в любой файловой системе HDFS представляет собой набор папок и файлов
Файлы в HDFS хранятся в виде блоков размером по умолчанию 128 мб. Каждый блок может реплицироваться (копироваться и храниться в виде нескольких реплик)
Основными составляющими HDFS являются:
- Namenode — нода, на которой запущено ПО, которое отвечает за хранение информации о расположении реплик каждого блока и другой метаинформации; Namenode также отвечает за ведение журнала транзакций (изменений файлов) и регулярный опрос (heartbeats) нод с данными (если нода не отвечает, значит считается, что она не работает)
- Datanode — нода, на которой непосредственно размещаются реплики блоков; при выполнении репликации рекомендуется хранение реплик одного блока на различных серверных стойках (rack) - в HDFS существует встроенный механизм rack awareness; на Datanode запущено свое ПО, которое является частью HDFS
- Клиент — приложение, взаимодействующее с HDFS через какой-либо API (например через терминал)
¶ Запись файла
- клиент запрашивает у NameNode разрешение на запись
- NameNode выделяет блоки и указывает, на какие DataNode записывать данные
- клиент записывает данные напрямую в DataNode
- DataNode реплицируют данные на другие узлы
¶ Чтение файла
- клиент запрашивает у NameNode список блоков файла
- NameNode возвращает список блоков и их расположение
- клиент читает данные напрямую с DataNode
¶ Удаление файла
- клиент отправляет запрос на удаление в NameNode
- NameNode обновляет метаданные и отправляет команду на удаление блоков в DataNode
Основная задача HDFS - распределенное хранение файлов большого объема, обеспечивающее высокую скорость чтения/записи.
Основной недостаток HDFS: Namenode является единой точкой отказа системы (в реальных системах применяется Secondary Namenode - реплика Namenode, однако это не спасает ситуацию).
¶ Концепция Data Lake (Озеро данных)
В отличие от традиционных реляционных баз данных, куда мы пишем строго структурированные данные (схемы, типы полей), в Data Lake мы сгружаем данные сырые данные (raw data).
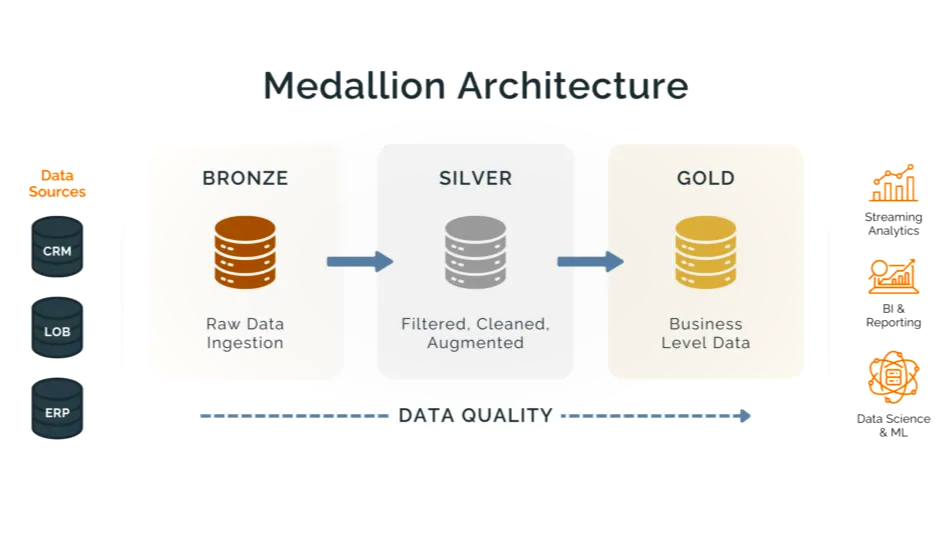
Обычно озеро делят на зоны (слои):
-
Bronze: сырые данные в исходном формате (JSON, CSV, Logs) без обработки, пишем всё, что собрали
-
Silver: очищенные данные, приведенные к единому формату
-
Gold: витрины данных, агрегаты, готовые для аналитики
Логика: сначала данные сгрузили, дальше решим, что делать. Зачем: чтобы можно было пересчитать витрины при изменении логики парсинга без повторного обращения к источнику.
В этой работе мы будем создавать Bronze слой.
При построении озер данных принято использовать Hive-style partitioning, когда структура папок сама по себе является индексом данных:
-
/data/schedule_2026_02_17.json -
/data/schedule/year=2026/month=02/day=17/data.json
Будем использовать WebHDFS и Python для взаимодействия с HDFS через API.
¶ AirFlow Connections и Dynamic Task Mapping
Параметры подключения к внешним системам (базам данных, API, HDFS) не пишут в коде DAG.
Airflow использует сущность Connection. Это запись в мета-базе данных Airflow, которая хранит:
- Conn Id: уникальный идентификатор
- Host, Port, Login, Password
- Extra: дополнительные параметры (JSON)
В коде обращаемся только к Conn Id. Если адрес сервера изменится, то поменяем его один раз в веб-интерфейсе.
Частая задача — обработать список объектов одинаковым способом. Скачать расписание для 5 преподавателей. Циклы for сегодня притаких вещах не используются, вместо этого Dynamic Task Mapping.
¶ Цель работы
Развернуть кластер Hadoop HDFS, настроить Connection в Airflow и реализовать динамический DAG, который параллельно собирает данные для списка преподавателей и сохраняет их в Data Lake с учетом партиционирования.
¶ Задание
Используйте обновлённые файлы для развёртывания (с заменой).
Запустите контейнеры с повторной сборкой образов (docker compose up -d --build) и проверьте localhost:9870. Если ошибки, то остановите контейнеры и запустите их без флага -d (либо используйте docker logs).
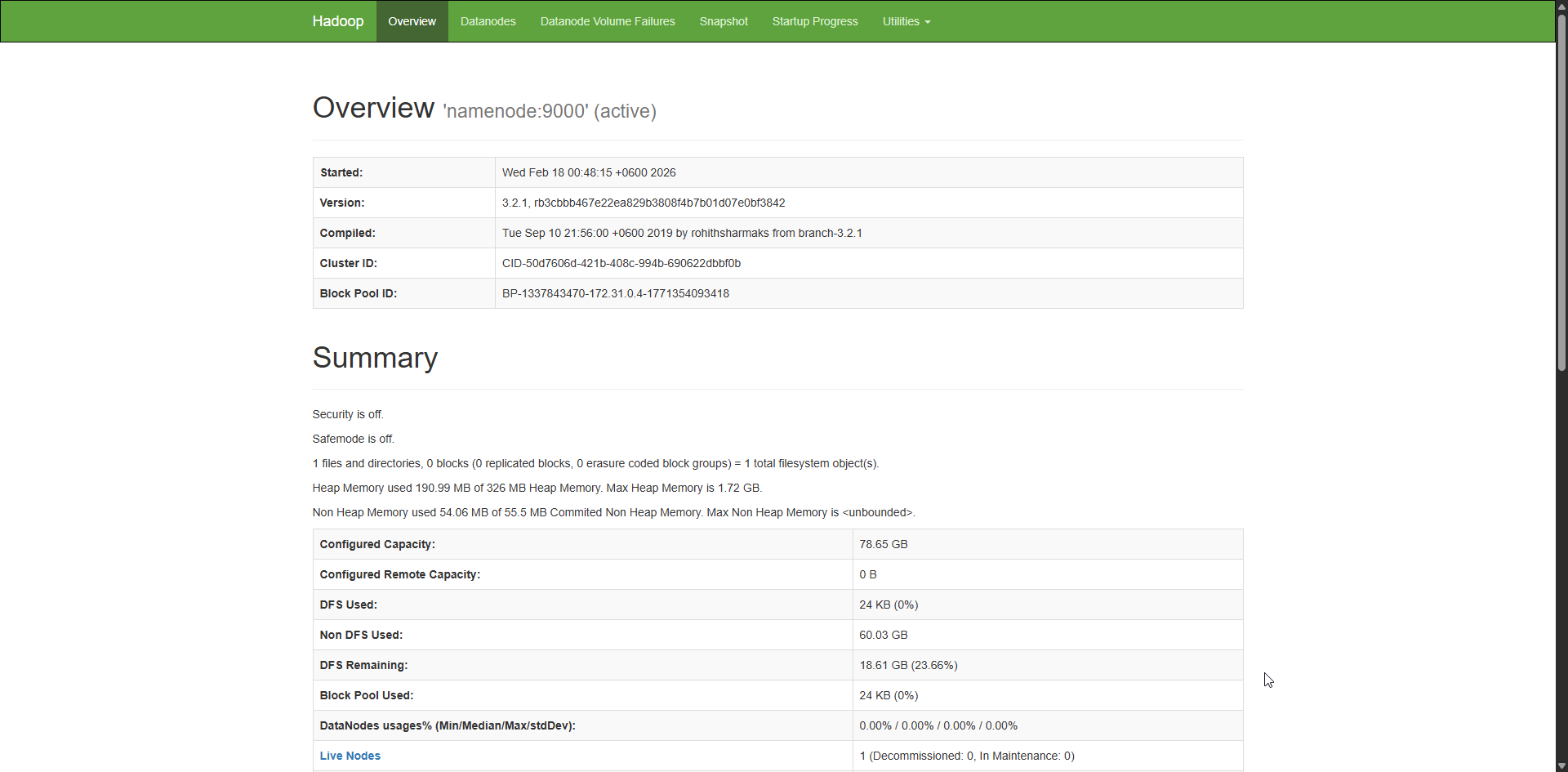
Обратите внимание на
Utilities -> Browse the file system
Перейдите в Admin -> Connections. Создайте в веб-интерфейсе AirFlow подключение webhdfs с Connection Type Apache WebHDFS, Host namenode и Port 9870.
Контейнеры объединены в одну сеть. Вместо IP-адреса NameNode указывается имя сервиса или контейнера (если оно задано). Если посмотреть в
docker-compose.yaml, то имя контейнера будетnamenode.

Создайте новый DAG, Определите список из ID 5 преподавателей (найдите их через инструменты разработчика в браузере; преподаватели на ваш выбор).
Используйте поиск по фамилии преподавателя и следите за вкладкой
Network
Создайте задачу get_teachers, вовзращающую список ID преподавателей.
Создайте задачу process_teacher_schedule, которая получает расписание преподавателя за текущую неделю (принимает ID преподавателя).
Используйте хук WebHDFSHook для работы с HDFS. Реализуйте скачивание и сохранение списка занятий в формате JSON. Используйте партиционирование: /user/airflow/schedule/year={date.year}/month={date.month}/day={date.day}/teacher_id={teacher_id}/schedule.json (это пример).
Используйте
logical_date, а неdatetime.nowдля обеспечения идемпотентности (возможность перезапуска DAG за прошлые даты).
Реализуйте Dynamic Task Mapping для задачи process_teacher_schedule.
¶ Критерии приёмки
- в веб-интерфейсе Airflow настроено соединение
- DAG выполняется без ошибок до конца
- в исходном коде DAG используется ID подключения, а не хардкод
- на графе после запуска виден Dynamic Task Mapping (квадратные скобки и число)
- в интерфейсе HDFS видна структура папок с партиционированием
- можно скачать любой файл
schedule.jsonчерез веб-интерфейс, и там будет информация о занятиях - студент отвечает на вопросы преподавателя (в том числе про устройство HDFS, особенности распределённых систем и т. д.)
При скачивании в адресной строке браузера замените
datanodeнаlocalhost, когда получитеERR_NAME_NOT_RESOLVED