¶ Основная теория
¶ Колоночная СУБД ClickHouse
Классические реляционные системы управления базами данных (MS SQL Server, MySQL, PostreSQL) являются строчными:

Значения, относящиеся к одной строке, физически хранятся рядом. В колоночных СУБД все наоборот:
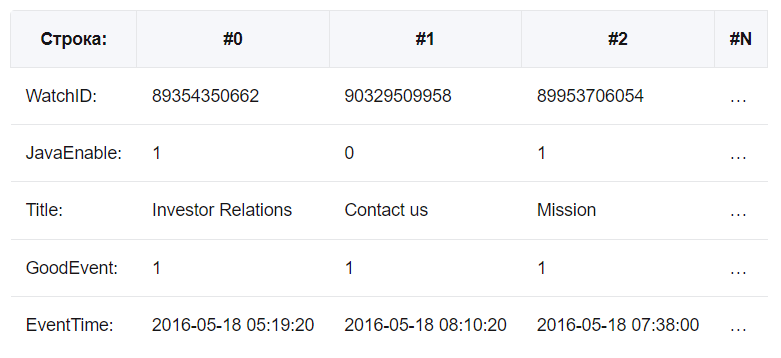
Разный порядок хранения данных подходит для разных сценариев работы.
Классический OLTP-сценарий (Online Transaction Processing):
- подавляющее большинство запросов — на запись данных
- данные обновляются часто, но небольшими пакетами
- при чтении извлекаются небольшие пакеты данных
- запросы идут сравнительно часто
Сценарий извлечения и обработки больших данных, OLAP-сценарий (Online Analytical Processing):
- подавляющее большинство запросов — на чтение данных
- данные либо не обновляются, либо обновляются большими пакетами
- при чтении извлекаются большие пакеты данные (требуется высокая пропускная способность сервера)
- запросы идут сравнительно редко
Для OLTP-сценария целесообразно применять строковые базы данных, а для OLAP-сценария — колоночные.
Примеры колоночных СУБД: ClickHouse, Cassandra, Snowflake, Amazon Redshift и BigQuery.
В рамках лабораторной работы мы будем работать с СУБД ClickHouse, разработку которой начинал Яндекс. ClickHouse был разработан для решения задач веб-аналитики для Яндекс Метрики — третьей по популярности системы веб-аналитики в мире. В настоящее время ClickHouse используют Cloudflare, Bloomberg, ВКонтакте, Т-Банк и другие.
Особенности ClickHouse:
- реализовано эффективное сжатие данных
- поддерживаются сложные типы данных: JSON, UUID, Point, Array, Map и другие
- реализована параллельная обработка запросах на нескольких ядрах
- реализована распределенная обработка в кластере
- поддерживается шардирование и репликация
¶ Apache Spark и PySpark
Spark является частью экосистемы Hadoop и альтернативой MapReduce. Spark позволяет производить пакетную и потоковую обработку данных.
В отличии от MapReduce в Spark:
- данные в ходе обработки хранятся в RAM, а не на жестком диске
- можно реализовать не только пакетную, но и потоковую обработку данных
Spark может работать в Hadoop-кластере под управлением YARN и загружать данные из распределенных файловых систем (например, из HDFS). Spark состоит из следующих компонентов:
- Core — ядро фреймворка
- Spark SQL — инструмент обработки данных с помощью SQL-запросов
- Streaming — инструмент потоковой обработки данных
- MLLib — набор инструментов машинного обучения
- GraphX — инструмент обработки графов
Основными абстракциями в Spark являются Resilient Distributed Dataset (RDD) и DataFrame. Для работы с Apache Spark существуют API на самых разных языках программирования (Java, Python, Scala, R). Мы будем использовать PySpark.
¶ Цель работы
Научиться работать с колончатой системой управления базами данных ClickHouse и выполнять аналитические запросы с использованием PySpark.
¶ Предварительная подготовка
- переименуйте виртуальные машины:
- машину с Namenode назовем
Spark (Hadoop) - машину с Ansible из ЛР 2 назовем
ClickHouse
- машину с Namenode назовем
Эти названия будут использоваться далее в инструкции
Вы можете выполнять эту ЛР до выполнения ЛР 2. В этом случае вам просто потребуются две настроенные виртуальные машины с различными IP-адресами, находящиеся в одной виртуальной сети. Переименуйте их, чтобы было проще следовать инструкции
- загрузите набор данных и скопируйте его на машину
ClickHouse(потребуется авторизоваться на Kaggle, возможно у вас есть аккаунт, можно через Google)
Чтобы скачать набор данных на странице с данными нажмите
Download, далееDownload dataset as zip
-
в архиве будет 2 файла с расширением .csv; возьмите тот, который больше по размеру (~400 МБ), для удобства переименуйте его в
data.csvи перенесите на виртуальную машинуClickHouse -
это данные о финансовых транзакциях, могут быть использованы для решения задачи классификации (мошенническая транзакция или нет)
Чтобы было удобнее писать код на Python в режиме подключения по SSH через Visual Studio Code сразу после подключения к виртуальной машине перейдите на вкладку
Extensionsв Visual Studio Code и установите на конкретную виртуальную машину расширениеPython.
¶ Задачи работы:
¶ Установка ClickHouse
- подключитесь к машине
ClickHouse - установите СУБД ClickHouse, выполнив команды
Обратите внимание: в ходе установки нужно будет установить пароль пользователя по умолчанию. Запомните этот пароль!
# установка необходимых зависимостей
sudo apt-get install -y ca-certificates curl gnupg
# добавление ключа репозитория ClickHouse
curl -fsSL 'https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key' | sudo gpg --dearmor -o /usr/share/keyrings/clickhouse-keyring.gpg
# добавление репозитория ClickHouse
echo "deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb stable main" | sudo tee /etc/apt/sources.list.d/clickhouse.list
# обновление списка пакетов
sudo apt-get update
# установка ClickHouse
# в ходе установки нужно будет ввести пароль дефолтного пользователя (default)
sudo apt-get install -y clickhouse-server clickhouse-client
- создайте файл конфигурации:
sudo nano /etc/clickhouse-server/config.d/listen_host.xml
- добавьте в него следующее содержимое и сохраните:
<clickhouse>
<listen_host>0.0.0.0</listen_host>
<allow_unrestricted_reads_from_file>1</allow_unrestricted_reads_from_file>
</clickhouse>
- мы разрешили подключение из внешних сетей
- можно запускать сервер
# запуск сервера
sudo clickhouse start
# подключение к клиенту
clickhouse-client
- переключаясь в
clickhouse-clientвы можете писать SQL-запросы к серверу - чтобы выйти из
clickhouse-clientвыполните командуexit - можно пользоваться графическим интерфейсом
- перейдите на страницу http://<IP адрес машины ClickHouse>:8123/play в браузере и введите пароль сверху
- на этой странице можно писать запросы на диалекте SQL и выполнять их
- для проверки работоспособности выполните команду:
SELECT version();
Не забудьте ввести пароль пользователя
Если веб-интерфейс не открывается, остановите сервер командой
sudo clickhouse stop; выполните командуsudo clickhouse-serverи посмотрите логи; по логам можно заняться исследованием ошибок
¶ Создание таблицы и импорт данных
- продолжаем работать на машине
ClickHouse - перенесите файл
data.csvв нужную директорию и измените владельца:
sudo mv data.csv /var/lib/clickhouse/user_files/
sudo chown clickhouse:clickhouse /var/lib/clickhouse/user_files/data.csv
- создайте таблицу из файла; для этого выполните запрос:
CREATE TABLE transactions
ENGINE = MergeTree()
ORDER BY tuple()
AS SELECT * FROM file('data.csv', 'CSVWithNames', 'auto');
Не забудьте указать корректный путь к файлу! Путь указывается относительно директории
/var/lib/clickhouse/user_files/
- выведите 500 строк таблицы
SELECT * FROM transactions LIMIT 500
-
используя документацию по запросам, попрактикуйтесь с выполнением аналитических запросов
- выведите все транзакции в категории (Product Category) ‘home & garden’
- выведите средний размер (Transaction Amount) транзакций с мобильных телефонов (Device Used = ‘mobile’)
- выведите количество транзакций для каждого метода оплаты (Payment Method)
Пример вывода:

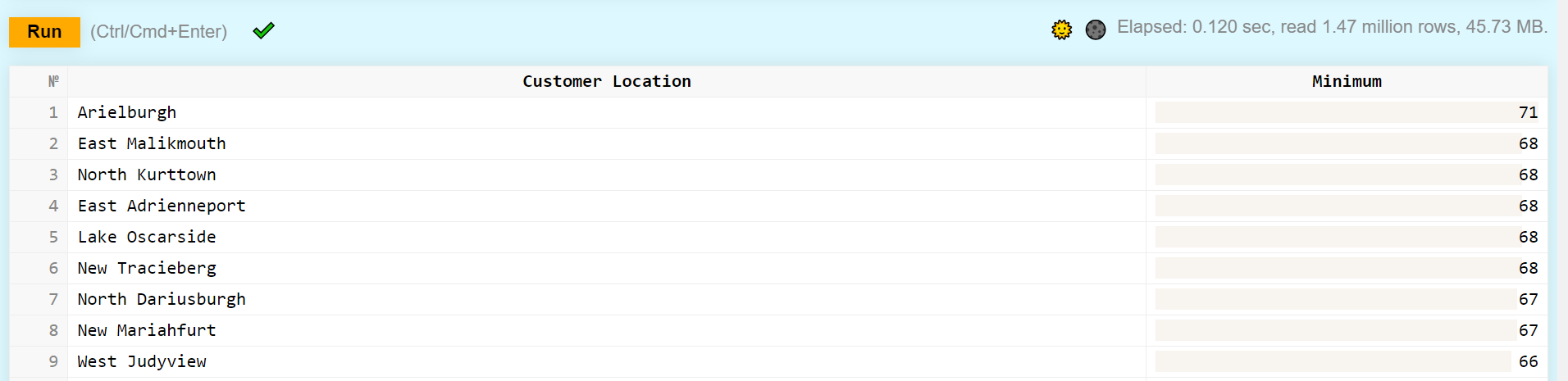
- выведите минимальный возраст покупателя (Customer Age) в каждой локации (Customer Location) и отсортируйте вывод по убыванию значения минимального возраста (при этом для столбца с минимальными значениями должен быть задан какой-нибудь псевдоним)
Пример вывода:
¶ Установка PySpark
- подключитесь к машине
Spark (Hadoop) - скачайте архив со Spark:
wget https://dlcdn.apache.org/spark/spark-3.5.5/spark-3.5.5-bin-hadoop3.tgz
- разархивируйте его:
tar xvf spark-3.5.5-bin-hadoop3.tgz
- добавьте в конец файла
~/.bashrcследующие значения (важно: следите за вашими путями; у вас могут быть другие пути, не такие как у меня):
export SPARK_HOME=/home/mikhail/spark-3.5.5-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
- выполните команду
source ~/.bashrc - для проверки установки выполните команду
spark-shell, запустится оболочка Spark, ее можно закрыть черезCtrl+C - если ошибок нет - Spark установлен
¶ Работа с PySpark
- продолжайте работать с машиной
Spark (Hadoop) - создайте какую-нибудь папку, в ней — виртуальное окружение для Python
- активируйте окружение и установите через pip пакет
pyspark - далее надо код писать, удобно будет подключиться и делать это через Visual Studio Code
- попробуйте написать следующий код и запустить его
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('Spark Test')\
.getOrCreate()
- если выполнение прошло без ошибок (warning — не ошибка), значит все хорошо
- скачайте этот jar-файл и копируйте его на виртуальную машину
Spark (Hadoop), поместите его в папку с проектом (где вы код пишите на Python) - запустите этот код, он загружает данные из ClickHouse в виде DataFrame
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master('local[*]')\
.appName('Spark Test')\
.config('spark.driver.extraClassPath','clickhouse.jar')\
.getOrCreate()
# здесь не забудьте если нужно поменять адрес
url='jdbc:clickhouse://192.168.56.101:9000'
user='default'
# и здесь
password='12345'
# здесь имя пользователя и таблицы
dbtable='default.transactions'
driver='com.github.housepower.jdbc.ClickHouseDriver'
# загружаем данные в виде DataFrame
df=spark.read.format('jdbc').option('driver',driver).option('url',url).option('user',user).option('password',password).option('dbtable',dbtable).load()
# выводим 5 строк датафрейма
df.show(5)
- используя функциональность DataFrame в PySpark (методы
pyspark.sql) напишите код для выполнения тех же 4 запросов, которые вы писали в браузере; - может пригодиться:
¶ Критерии приема работы:
- установлен ClickHouse, открывается страница в браузере для выполнения запросов
- создана таблица из скачанного csv файла
- написаны и работают необходимые аналитические SQL-запросы (на странице в браузере)
- установлен Spark
- написан и работает код на Python с PySpark, загружены данные, работают необходимые аналитические запросы